








ABSTRACT
COVID-19迅速席卷全球,引发了以谣言为代表的信息流行病,给世界带来了不可估量的损失。尽可能快速、准确地实现谣言检测迫在眉睫。然而,现有的方法要么关注谣言检测的准确性,要么设定固定的阈值来实现早期检测,遗憾的是无法适应各种谣言。在本文中,我们关注在线社交网络中的文本谣言,并提出了一种新颖的谣言检测方法。我们将检测时间、准确率和稳定性作为三个训练目标,并在整个训练过程中不断调整和优化该目标,而不是使用固定值,从而增强其适应性和通用性。为了提高效率,我们设计了一个滑动区间来截取所需的数据,而不是使用整个序列数据。为了解决多个优化目标集成带来的超参数选择问题,采用凸优化方法来避免枚举的巨大计算成本。大量的实验结果证明了所提出方法的有效性。与三个不同数据集中的最先进的同行相比,识别精度平均提高了 7%,稳定性平均提高了 50%。
关键词: 在线社交网络 谣言检测 神经网络 多目标优化 滑动区间
1. Introduction
2019年底,一场由新型冠状病毒(COVID-19)引发的灾难迅速席卷全球。结果,疫情引发的公共卫生危机给世界带来了前所未有的损失(Wu et al., 2020)。与以往不同的是,在病毒迅速传播的同时,以谣言为代表的虚假信息通过全球化网络社交媒体的泛滥而激增(Zarocostas,2020)。信息的传播速度比病毒还快,直接催生了世界各国的“第二战场”。正如世界卫生组织 (WHO) 总干事谭德塞所说:“我们不仅在抗击流行病,我们还在抗击信息流行病”(《柳叶刀》,2020)。
微博、推特、脸书等大型网络社交媒体的蓬勃兴起,取代传统媒体成为人们获取和发布信息的重要平台。这些平台因其速度快、范围广、即时性强,成为谣言的温床。缺乏有效监管,未经处理的谣言可能会很快被扭曲和放大,形成高度不确定的信息环境,从而误导公众影响社会稳定,甚至威胁国家安全。谣言已经成为比以往任何时候都更加严重的社会问题,需要全社会的关注和努力(冷等,2021)。有效识别谣言是一项非常具有挑战性的任务。有些谣言经过层层加工、精心包装,有时足以“以假乱真”。比如,一些造谣者捏造疫苗用于追踪人体、植入芯片的谣言,其杀伤力非常可怕。疫情进一步蔓延,引起公众普遍恐慌,严重危害国家稳定(马里兰州,2021)。但事实上,没有疫苗微芯片,疫苗也不会追踪人或将个人信息收集到数据库中。不同用户的知识、经验和情感在各方面差异很大,导致用户仅凭认知几乎不可能识别谣言。不同用户的知识、经验和情感在各方面差异很大,导致用户仅凭认知几乎不可能识别谣言。
幸运的是,越来越多的研究人员致力于探索和解决这个问题。政府部门和民间组织也搭建了一些反谣言平台,如国家网信办建立的“辟谣网”、美国夫妇建立的“斯诺普斯网”等。这些平台利用群体感知的优势,鼓励用户主动识别和报告可疑信息,然后将可疑信息传递给专业研究人员,以科学解释反驳谣言。虽然这种基于手动的检测方法具有很高的准确度(Li,Li,Wang,&Wang,2018;Xu,Rao,Xu,Yang,&Li,2019;Zhou et al.,2022),但它需要经过一系列过程具有明显的时滞性,无法适应在线社交网络(OSN)中的海量数据。此外,群体感知技术面临着冷启动问题,需要大量的人力。一些研究人员开始利用机器学习技术来自动识别谣言(Alkhodair、Ding、Fung 和 Liu,2020;Liang、Yang 和 Xu,2016)。这些基于传统机器学习的谣言检测方法很大程度上依赖于人工提取和选择的特征,耗费巨大的人力和时间。得到的特征向量鲁棒性不够鲁棒,难以应对复杂多变的场景。
受深度学习成功的推动,许多研究利用各种神经网络来检测谣言(Bian 等人,2020;Ma、Gao 和 Wong,2019;Yang 等人,2020)。深度学习方法比特征工程方法能够获得更好、更本质的代表性特征,从而达到更好的分类结果。从更实际的角度来看,研究人员不仅限于追求谣言检测的准确性,还希望能够更早地被检测到(Liu,Jin,&Shen,2019)。
然而,要有效实现谣言的精准识别,还有几个问题需要有效解决。首先,神经网络天然的端到端结构导致难以掌握谣言信息的关键成分,导致训练缺乏可控性和效率。因此,需要提取关键信息并优化网络结构。其次,我们注意到大多数研究只考虑谣言检测的单一角度,例如准确性,而忽略了在实践中花费在检测上的时间同样重要。尽管一些研究在谣言的早期发现方面做出了努力,但牺牲了部分预测的稳定性和准确性。因此,如何在不同目标之间进行平衡和妥协并达到最佳性能是一个重大挑战。第三,随着研究的深入,各种模型被提出,但变得越来越复杂,计算量也越来越大。因此,能否在复杂的网络模型中找到一种有效的方法来减少训练中的计算消耗也是一个值得进一步研究的问题。对于模型中超参数的存在,通常的做法是通过枚举尝试不同的值,然后从有限的选择中选择一个可以使用的参数来得到最好的结果,这不能保证最优性。
在本文中,我们研究了 OSN 中的一种新颖的谣言检测方法。为了掌握关键信息并优化网络结构,引入了注意力机制。从检测性能的不同角度,我们提出了三个优化目标。为了解决上述优化带来的超参数问题,引入了更简洁的确定方法。本文的值得注意的贡献总结如下。
• 我们关注在线社交网络中的文本谣言,并提出一种新颖的谣言检测方法。引入有效的空间注意机制来提取文本内容的内在特征。构建了有效的框架来提取谣言在传播过程中的进化特征,使得表征谣言在OSN上的扩散规律成为可能。
• 我们将检测时间、准确率和稳定性作为三个训练目标,并在整个训练过程中不断调整和优化,而不是使用固定值,从而增强其适应性和通用性。
• 为了提高效率,我们设计了一种基于滑动区间的检测方法,通过构造不同的优化损失目标来截取所需的数据,而不是使用整个序列数据。
• 为了解决多个优化目标集成带来的超参数选择问题,采用凸优化方法对它们进行参数化,使它们在整个模型学习过程中自适应变化,避免枚举的巨大计算成本。
本文的其余部分安排如下。我们在第 2 节中回顾了相关工作。在第 3 节中,我们提出了问题的表述。在第 4 节中,详细介绍了所提出的谣言检测方法和实现框架。在第五节中,进行了实验结果和性能评估。最后,我们在第 6 节中总结了本文。
2. Related works
随着OSN的快速发展,谣言检测受到越来越多的关注。谣言检测的任务是通过一些相关信息来区分OSN中的信息是否是谣言,人们提出了各种计算方法,主要包括四种类型:人群感知相关方法、特征工程相关方法、传播模式相关方法和深度学习方法。
2.1. Crowd sensing related methods
人群感知相关方法是当前社交网络平台的主流谣言检测方法。该平台将用户举报的可疑信息传递给经验丰富的编辑或行业专家,然后他们利用知识和经验以科学的解释反驳谣言。
Mohler和Brantingham(2018)提出了一种基于新颖的在线霍克斯过程估计算法的众包框架,利用报告、提示和邻居帖子等众包信息构建预测模型,为收集谣言提供了便利。考虑到异构任务的动态参与者选择问题,Li 等人。 (2018)在保持一定水平的概率覆盖的同时最大限度地降低感知成本,从而为谣言收集用户较少的问题提供了解决方案。为了鼓励用户参与谣言举报,Xu 等人。 (2019)设计了具有多个协作任务的群体意识系统的激励机制,以最小化社会成本,以便每个协作任务都可以由一组兼容的用户执行。人群感知相关方法虽然准确率很高,但由于需要用户主动举报,造成时滞。而且,OSN每天都会产生大量的数据,人类不可能处理所有的数据,这可能会遗漏重要的谣言。
2.2. Feature engineering related methods
特征工程相关方法从训练数据集中选择并提取能够有效表示数据的特征,并利用这些特征进行训练以获得分类模型。
梁等人。 (2016)发现谣言者的行为与普通用户不同,提出了一种基于用户行为特征的谣言检测方法,并分析了不同内容和类型之间的差异。郭、曹、张、郭和李(2018)利用不同层次和社会情境的层次表示进行分析,提出了一种引入重要语义信息(例如帐户和文本特征)的两层神经网络。 Wu、Yang和Zhu(2015)在综合考虑主题、情感等语义特征以及信息传播的结构特征的基础上,提出了一种基于图形核的混合支持向量机分类器。
然而特征工程相关方法依赖于人工特征选择,难以获得高维、复杂、抽象的特征数据。因此,得到的特征向量鲁棒性较差,难以全面、系统地总结谣言的特征。
2.3. Propagation mode related methods
只提取单条信息的特征往往忽略了谣言之间的联系,而传播模式相关方法可以通过其层次结构反映谣言之间的潜在联系。 Jin,Cao,Jiang和Zhang(2014)利用由事件、子事件和消息组成的三层声誉网络来表示事件的发生,并通过语义和社会关系建立联系,然后提出分层传播模型。万等人。 (2021)通过探究谣言与反谣言之间的耦合关系,提出了谣言扩散模型,进而预测谣言的传播并提出相应的干预措施。 Ma、Gao和Wong(2017)提出了一种基于核的传播树方法,通过评估传播树之间的相似性来识别谣言,该方法发现并捕获Ru-MORS传播树中的显着子结构。传播模式相关方法是研究热点之一,但谣言的传播受到多种因素的影响。目前,谣言传播的一致性结构尚未得到很好的探索,仍需进一步研究。
2.4. Deep learning methods
受深度学习成功的推动,许多研究利用各种神经网络来检测谣言。于等人。 (2017)提出了一种基于卷积神经网络的谣言检测方法(CAMI),该方法提取分散的关键特征并形成它们之间的高级交互。 Yuan、Ma、Zhou、Han和Hu(2019)探索了局部语义关系和全局结构信息,并提出了一种基于全局和局部注意的网络(GLAN),联合编码局部语义和全局结构信息以进行谣言检测。宋等人。 (2021)提出“可信检测点”的概念,并从检测入手,实现谣言的早期发现。
我们注意到,目前大多数研究的重点只集中在检测的准确性上。尽管一些研究(Song等,2021;Yuan等,2019)已经开始关注早期检测,但他们的方法通常是设定一个固定的阈值。然而,谣言的内容多种多样,固定的阈值可能无法满足其检测的需要。而且,随着网络结构越来越复杂,其计算复杂度也越来越高。当实验中出现超参数时,常见的方法是枚举,不断尝试不同的值,然后从有限的选择中选择最有效的参数。但该方法只能找到相对合适的超参数,并不能保证最优性。为了解决这些问题,我们将检测点作为训练目标,在训练过程中不断调整和优化,而不是使用固定值,从而增强其通用性。同时将准确率和稳定性作为另外两个训练目标,在提高准确率的同时可以尽早实现谣言的检测。为了减少训练过程中的计算量,我们使用滑动区间来截取所需的数据,而不是使用整个序列数据。
3. Problem statement
我们综合考虑两个方面:文字内容和转发特征。为了清楚地说明,我们提出以下定义。
定义1.我们用序列M={m1,m2,...,mn}来表示源微博的集合,其中n是源微博的数量,源微博mi表示文本内容。
定义2. 每个源微博mi都有一个相关的转发序列和对应的一组时间,表示为Ri = (ri, ti)。转发微博 ri = {ri1, ri2, ... , rivi } 表示文本内容, ti = {ti1, ti2, ... , tivi } 表示内容发布时的时间戳, vi 表示转发序列的长度来源微博mi。谣言检测任务的目的是训练一个能够准确预测源微博是否为谣言的模型f∶M⇒P(y=1|Rt,θ)ε(0,1)。其中,y是类别标签,θ是模型的所有参数,对于谣言我们设置y = 1,否则设置y = 0。
4. Methodology
为了解决第3节中定义的问题,我们提出了一种基于多目标损失(IDMO)的区间检测方法,该方法提取微博内容和转发序列的隐藏特征,然后在小时间间隔内完成基于隐藏特征的检测。 IDMO整体框架主要包括以下功能模块:
• 数据预处理:该模块包含文本分割和词嵌入,将一段文本内容分成不同的单词,然后过滤掉重要的单词并将其转换为CNN模型可以识别的向量形式。
• 基于空间注意力的CNN模型:空间注意力机制通过直观地给出每个词对不同维度结果的贡献来克服记忆的缺乏。该模块可以利用文本内容来提取隐藏特征。主要操作包括卷积、池化和全连接层。
• 具有序列特征的GRU模型:该模块可以利用重发布序列来提取长距离特征特征,其中主要操作包括重置和更新。
• 多目标损失函数:该模块从多个损失函数的角度评估训练结果,并通过反向传播相应地调整模型的参数。
• 超参数的参数化:多个损失函数所携带的超参数很难确定。为了避免枚举法带来的巨大计算量,该模块将其转化为优化问题,通过理论分析,推导出保证帕累托最优的最优解。
4.1. Data preprocessing
词是语言的基本元素,具有客观或实际意义,可以单独使用。因此,将文本切分成单词,减少它们之间的耦合,将它们表征为输入,可以使语义分析更加准确。近年来,Jieba分割包(Lai et al., 2019)因其简单和高效而被许多研究人员广泛使用。本文利用jieba切分对文本数据进行切分,并根据每个单词的得分生成广义词云在文字中。这种做法是合理的,因为这种方法可以过滤掉常见的单词,保留重要的单词,避免无意义的单词被输入到模型中干扰最终的结果。计算分数的方法(He, Chang, Lim, & Banerjee, 2010)如下,
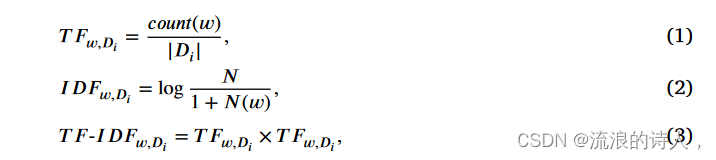
其中 w 是关键字,count(w) 是 w 出现的次数,|Di|分别是 Di 文档中所有单词的数量,N(w) 是语料库中出现单词 w 的文档数量,N 是语料库中文档的总数。
然后,我们需要将切分的单词转换为神经网络可以识别的特征向量,因此使用名为 word2vec 的高效词嵌入(Ji,Satish,Li,&Dubey,2019)。 Word2vec 模型可以将文本内容作为输入,并为该内容中出现的单词生成实值低维向量表示。设单词序列为W = {w1, w2, ... , wi, ... , wnw } ,并在指定窗口大小z内将wi周围的一组单词作为wi的上下文。通过最大化 wi 及其上下文单词之间的平均对数似然条件概率函数来学习它们的单词表示,如下所示,

4.2. CNN model based on spatial attention
卷积神经网络模型是一种包含卷积计算和深层结构的前馈神经网络,在图像等静态数据的特征提取方面取得了巨大成功(Husain & Bober,2019)。然而,由于CNN模型在自然语言处理过程中缺乏对历史词的记忆,会忽略历史词的权重,丢失重要词的位置信息,导致特征提取的准确率较低。
为了解决这个问题,我们引入了词级空间注意力机制来扩展 CNN 模型。通过考虑句子中单词的重要性,从不同维度提取相同数据的更多细化特征,从而获得更多信息,提高CNN模型对历史单词的记忆。从该机制中可以得到每个词对目标特征的贡献,因此所提出的IDMO具有一定的可解释性。
通过文本分割和词嵌入,我们可以获得每个文本内容(包括源微博和转发微博)的一系列d维词向量vi。那么单词拼接矩阵Mv可以构造如下:

其中 ⊕ 是串联操作,Mv ∈ Rd×nv ,其中 nv 是词向量的数量。 CNN模型包括卷积层、池化层和全连接层。在卷积层中,我们利用卷积核 Ki ∈ Rd×dk 扫描 Mv 并应用激活函数 ReLU (Glorot, Bordes, & Bengio, 2011) 来获得特征图,如下所示,

其中 Wc 是相应的权重矩阵,bi 是偏差。然后,在池化层中,应用下采样操作来提取最明显的特征,

在全连接层中,我们用ReLU重新组合最终的特征图̃C,以表示文本内容的总特征F如下,
![]()
然后,我们从不同的维度对源微博内容进行更细致的处理。如图1所示引入了词级空间注意力机制,它利用了空间关系。通过最大化池化和平均池化这两个操作,我们进一步细化了CNN提取的特征。我们通过卷积运算将它们连接起来并计算如下,

其中 σ 是 sigmoid 函数,K2 是卷积核。现有的研究(Woo, Park, Lee, & So Kweon, 2018)表明,当卷积核的大小为 7 × 7 时,空间注意力机制具有最佳性能。最后,空间注意力过程可以总结如下:
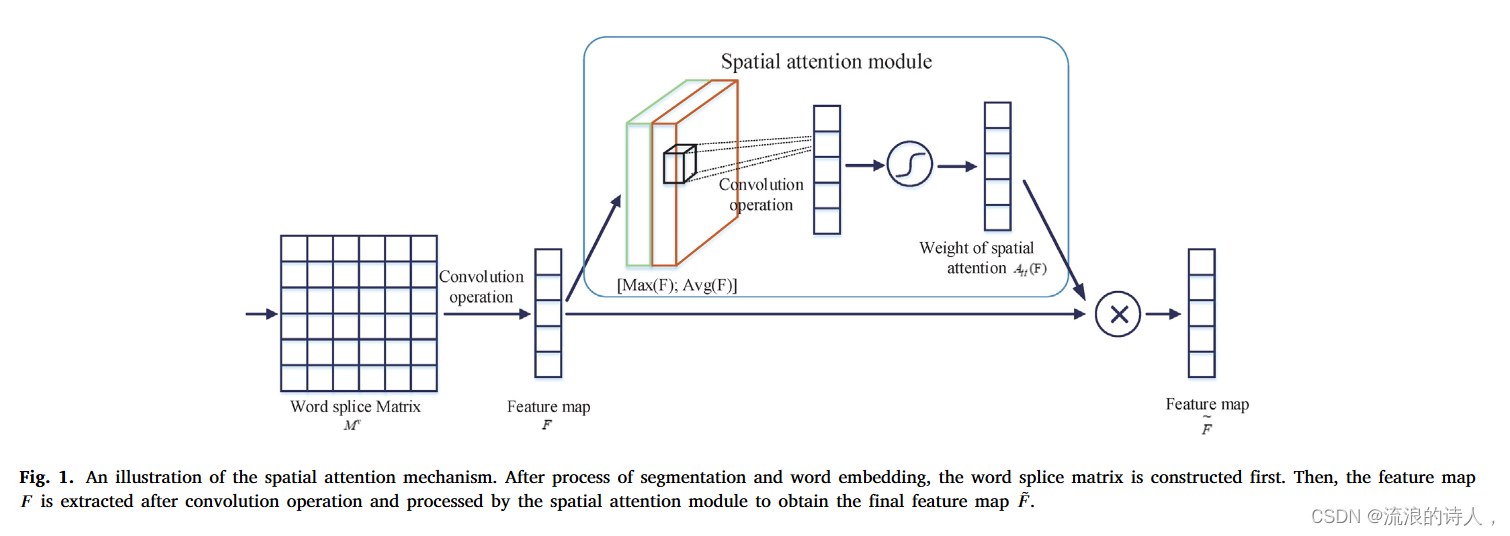
图 1. 空间注意力机制的图示。经过分词和词嵌入处理后,首先构建词拼接矩阵。然后,经过卷积运算后提取特征图F,并通过空间注意力模块进行处理,得到最终的特征图̃F。

其中 ⊗ 是 Hadamard 产品,̃ F 表示具有空间注意力的 CNN 模型输出的最终特征图。
4.3. GRU model with sequence feature
循环神经网络是一种处理序列数据的神经网络,在自然语言处理(NLP)领域取得了巨大成功。与其他神经网络相比,它可以处理具有时间依赖性的序列数据,特别适合处理微博的转发序列,从而提取OSN中的转发特征。门循环单元(GRU)是一种特殊的RNN,主要解决长序列训练过程中的梯度消失和梯度爆炸问题,在较长序列中比普通RNN有更好的表现。
通过CNN,提取转发序列中每个微博的特征,并将其输入GRU进行训练。 GRU单元包括重置门(r)和更新门(z),如下所示,
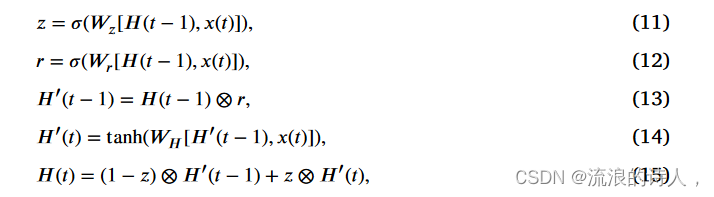
其中 ⊗ 是 Hadamard 乘积,H(t) 是隐藏层的输出,Wz、Wr 和 WH 是权重矩阵
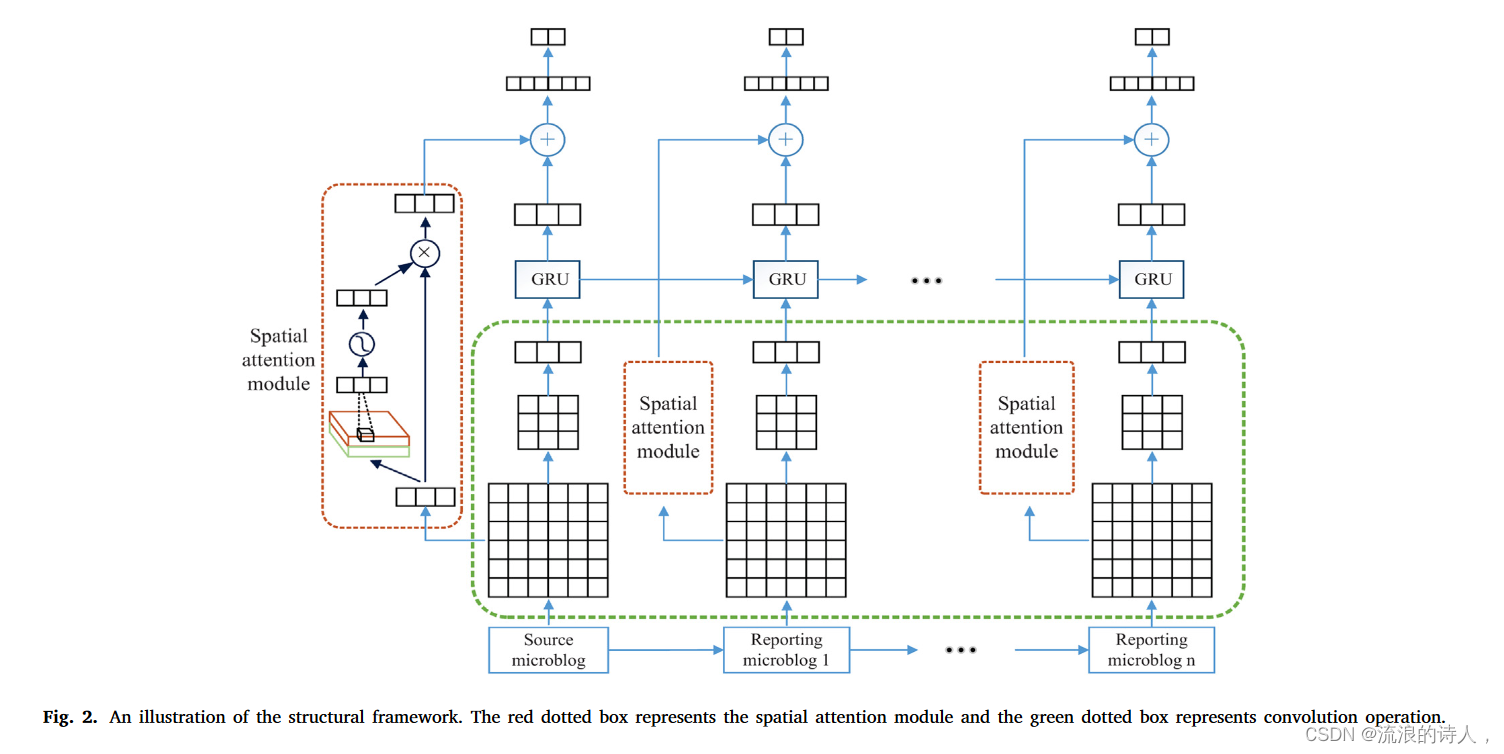
图 2. 结构框架图解。红色虚线框代表空间注意力模块,绿色虚线框代表卷积运算。
通过整合上述模块,IDMO的结构框架如图2所示。经过分词和词嵌入处理后,首先构建词拼接矩阵。然后,通过卷积运算从词级联矩阵中提取特征图F,并通过空间注意力模块进行处理,得到特征图̃F。之后,将特征图F输入GRU模块,并获得输出。进一步,将特征图̃F和H(t)进行拼接,放入分类器中得到最终的预测结果。 Focal loss 是 Lin, Goyal, Girshick, He, and Dollár (2020) 提出的一种解决单阶段目标检测中正负样本比例不平衡的方法,减少了大量简单负样本的权重训练样本,我们将其引入为以下损失函数,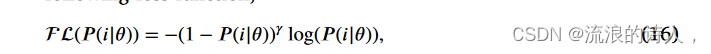
其中 P (1|θ) = σ(H, s) 且 P (0|θ) = 1 − P (1|θ),s 是相应隐藏层 H 的权重向量。
4.4. Multi-objective loss function
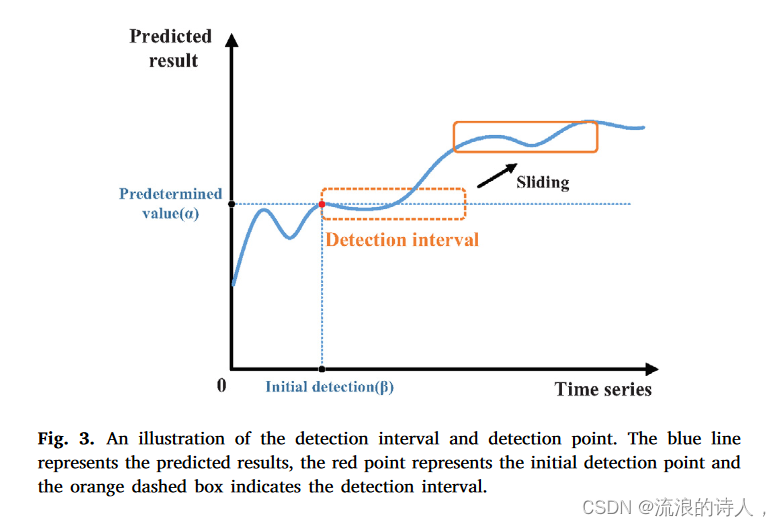
图 3. 检测间隔和检测点的图示。蓝线表示预测结果,红点表示初始检测点,橙色虚线框表示检测间隔。
为了在谣言转发过程中根据源微博尽早识别出谣言,我们需要为每个源微博找到一个初始检测点。如图3所示,在检测点之前,识别曲线的结果波动频繁,这意味着该时期的谣言很难辨别。此后,检测结果相对稳定,趋于准确。一旦确定了初始检测点,我们将使用它以固定长度的间隔来开始检测过程。这种检测间隔方法有效地节省了计算资源,而无需采用Song等人的整个序列的预测结果。 (2021)。
值得注意的是,由于不同源微博的内容和转发顺序存在差异,相应的检测间隔不可能完全相同。因此,人为给定检测阈值的方法(Song等,2021)不再适用。在本节中,我们提出了一种自适应区间检测方法来解决这个问题。
首先,我们为每个源微博引入两个参数 α ∈ [0, 1] 和 β ≥ 0 来确定初始检测点的位置,其中 α 是预定阈值,β 是时间点当预测结果达到阈值时。当预测结果P(y|Rt,θ)>α第一次达到阈值时,开始检测过程,对应的时间点为β。
我们的目的是通过自适应调整检测间隔来训练一个能够准确、快速、稳定地识别谣言的模型。我们从检测区间内和检测区间外两个方面进行调整。在检测区间内,我们目标的第一部分旨在实现预测的准确性,因此需要最大化检测区间内的预测结果,如下:

其中 len 是检测间隔的长度。为了保证最终预测结果的稳定性,避免预测趋势的过度波动,第二个目标是尽量减少检测区间内预测结果的差异。考虑到反向传播时求导的方便,我们采用平滑高斯径向基函数如下:

其中,ε 为高斯系数,r = ‖P (i|θ) − ̄ P ‖2 指预测结果的 L-2 范数减去平均值,̄ P= 1 len Σ β≤i≤β+len P (i|θ)。为了在谣言的传播过程中尽早实现有效识别,我们在第三个目标中引入时间约束,并使用对数似然的形式来降低推导的计算复杂度,如下:

β的初始值由α确定,然后β会根据检测间隔的筛选不断更新。 F是整个时间序列的长度。
为了在训练过程中考虑到上述三个目标,我们通过三个权重参数 λi (i = 1, 2, 3) 将它们整合如下:

由于这些权重参数需要在学习过程之前设置,而不是通过训练获得,因此也称为超参数。具体的确定方法将在下一节详细描述。在检测区间外,通过不断滑动检测区间,训练模型自适应地寻找最合适的检测时间点βnew,如下:

4.5. Parameterization of hyperparameters
在上一节中,我们通过引入三个权重参数将三个损失目标聚合到一个损失函数中。通常,这些权重参数是在开始学习过程之前设置的超参数,而不是通过训练获得的值。因此,不同的给定权重参数会极大地影响训练过程,进而影响最终的预测结果。处理超参数的方式是通过枚举,不断尝试不同的值,然后从有限的选择中选择一个能够达到最佳结果的参数。但这种方法只能找到相对合适的超参数,不能保证最优性。此外,随着超参数数量的增加,其选择的计算消耗呈指数级增长。
在本节中,我们将这些超参数引入到训练过程中,以便它们能够像非超参数一样在整个模型学习过程中自适应变化。使用学习排序(LTR)方法来处理(20)中引入的权重参数。该方法从理论上保证了这些权重参数是Pareto最优的,并且简洁且易于计算。
为了确保所有三个损失目标都能在模型的学习阶段发挥作用,我们在其超参数中添加边界约束,最优问题可以表述如下:
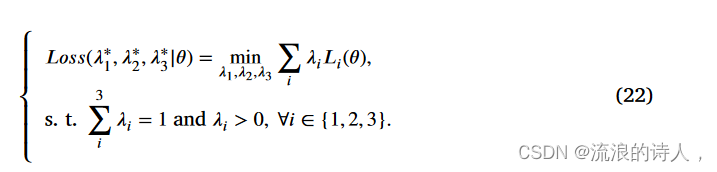
满足 KKT(Karush-Kuhn-Tucker)条件的解对称为帕累托平稳,如下所示:
定理 1(卡鲁什-库恩-塔克条件)。如果存在乘数 λi > 0, i = 1, 2, 3,则解对 (λ* 1, λ* 2, λ* 3) 是问题 (22) 的最优解,使得

详细的证明可以很容易地在 Ruszczynski (2011) 中找到。条件可以转化为以下二次优化问题,
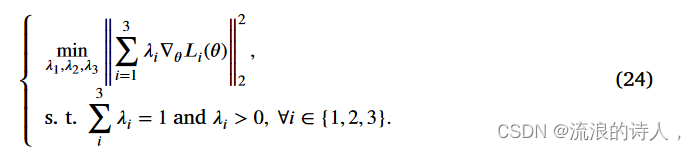
Sener 和 Koltun (2018) 证明了满足条件的解将使沿梯度的损失函数最小化。然后,我们首先处理等式约束,将上述问题重写为向量的形式,得到最优解如下:
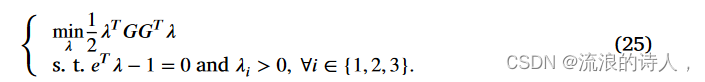
其中,λ是λi的级联向量,G是梯度∇θLi(θ)的堆叠矩阵,e是元素为1的3维列向量。接下来,我们构造拉格朗日L如下:
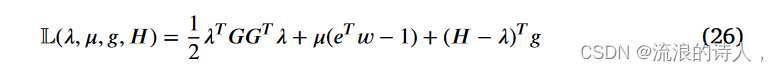
其中 μ 是等式约束的拉格朗日乘数,g = (g1, g2, g3)T 是不等式约束的拉格朗日乘数向量,其中 gi ≥ 0, ∀i ∈ {1, 2, 3}。 H = (h2 1, h2 2, h2 3)T 为松弛变量向量,引入h2 i 的目的是将不等式约束变为等式约束。
问题的解决方案如下:

我们可以通过求解以下线性系统来导出解:

根据摩尔-彭罗斯逆 (Wan, Wang, Han, & Wu, 2019),我们有

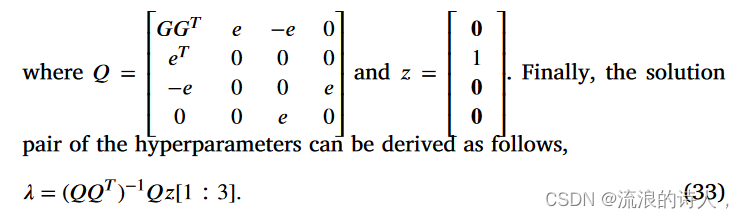
在本文中,我们采用 Adam 算法(Kingma & Ba,2015)来优化损失函数。尽管 Adam 具有批量随机梯度,但我们提出的方法仍然提供了梯度下降收敛的理论保证(Lin et al., 2019),具体过程如算法 1 所示。

5. Experiments
在本节中,通过数值实验评估基于多目标损失的区间检测方法。首先,我们用真实数据集验证了 IDMO 的有效性。其次,我们根据实验结果进行了深入的讨论。最后,我们分析了影响实验结果的参数的敏感性。
5.1. Datasets
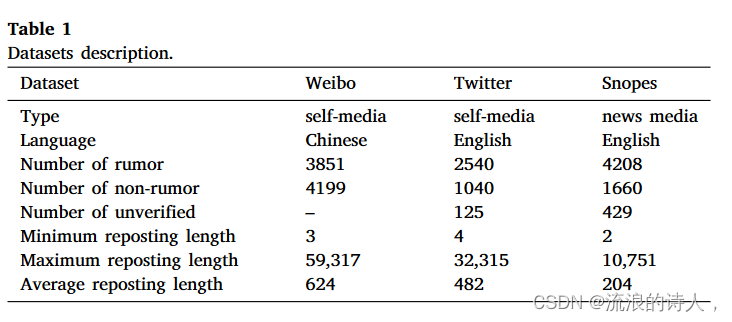
为了评估所提出方法的性能,我们在实验中使用了三个关于 COVID-19 的数据集,这些数据集是从现实世界的大型社交网络(例如微博、Twitter 和 Snopes.com)中提取的。微博数据集(Song et al., 2021)由清华大学发布,包含谣言内容、非谣言内容及其转发记录。 Twitter 数据集 (Elhadad, Li, & Gebali, 2020) 和 Snopes 数据集 (Hanselowski, Stab, Schulz, Li, & Gurevych, 2019) 根据 MIT 许可发布,收集有关 COVID-19 的信息,包括谣言、非谣言以及分别来自 Twitter 和 Snopes.com 的未经验证的内容。这三个数据集包括中文和英文、新闻媒体和自媒体,全面模拟了谣言检测的应用场景。数据集描述的详细信息列于表1中。
在模型训练和测试过程中,我们采用了holdout验证方法(Pang et al., 2019)来缓解过拟合问题,该方法将数据集按照比例随机分为训练集、验证集和测试集分别为 80%、10% 和 10%。训练集用于训练模型的参数,验证集用于初步评估模型的能力,测试集用于评估模型的泛化能力。
5.2. Baselines and evaluation metrics
为了公平比较不同方法的性能,本节采用三个评估指标(Yuan et al., 2019):准确率、精确率和召回率。此外,为了评估所提出的方法在预测时间和预测稳定性方面的性能,我们引入了 Song 等人的“早期率(ER)”。 (2021)并提出稳定性衡量标准(MS)如下,
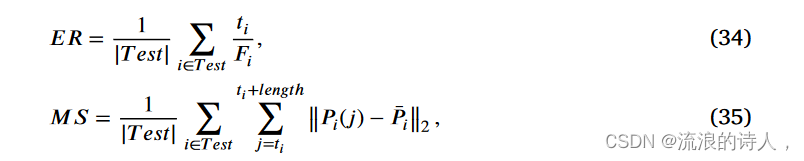
其中ti指的是预测结果第一次达到固定值(实验中我们设置为0.875)的时间节点,Fi是转发序列的长度,T est是测试集,长度指的是ti 和 ̄ Pi 之后我们想要检测稳定性的区间长度是其区间内预测结果的平均值。然后,我们将我们的方法与一系列代表性基线进行比较,如下所示,
• DSTS(Ma,Gao,Wei,Lu,&Wong,2015):一种具有动态时间序列结构模型的SVM,可以捕获各种社会背景特征随时间的变化。
• CAMI(Yu et al., 2017):为了形成重要特征之间的交互,CAMI利用CNN提取分散在输入序列中的关键特征,从而有效地识别谣言。 •
GLAN(Yuan et al., 2019):一种具有全局局部注意力网络的谣言检测方法,它将局部语义信息与全局结构信息相结合进行编码。
• CED(Song et al., 2021):一种使用 CNN+RNN 的早期检测方法,提出了“可信检测点”和多目标损失函数。
• IDMO:我们提出了基于多目标损失的谣言区间检测方法,该方法在处理文本时不使用空间注意机制。
• IDMO-SA:基于多目标损失和空间注意机制的谣言区间检测方法。
5.3. Parameters optimization
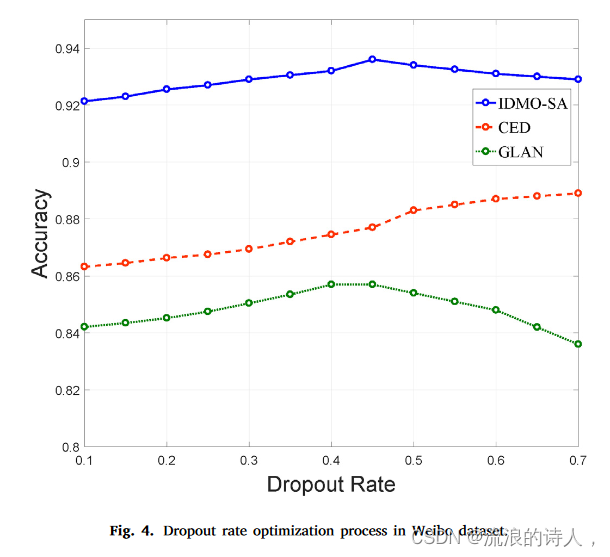
图 4. 微博数据集中的 Dropout 率优化过程。
我们重复实验,为每个基线方法提供最佳超参数。在训练过程中,我们将初始dropout率设置为0.5,并在0.05的范围内搜索。实验的结果如图4所示,当IDMO-SA的dropout率为0.45、CED为0.7、GLAN为0.4时,方法的性能最好。学习率从以下范围{0.0001,0.0005,0.001,0.005,0.01,0.1}进行探索,
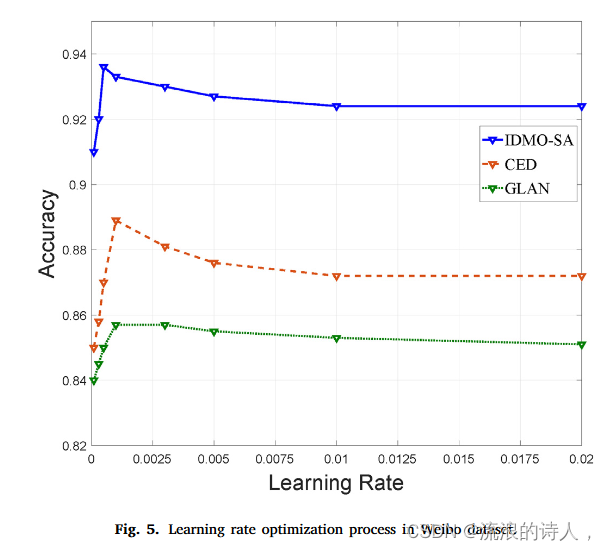
图 5. 微博数据集中的学习率优化过程。
相应的实验结果如图5所示。我们注意到,当IDMO-的学习率达到最高时,准确率达到最高。 SA 为 0.0005。当CED和GLAN的学习率为0.001时,该方法效果最好。正则化系数从一个很小的值(10e−6)开始,以10倍的增量进行搜索。实验结果会随着正则化系数的增大而增大。当达到最优结果时,实验结果会随着正则化系数的增大而减小,并趋于稳定。
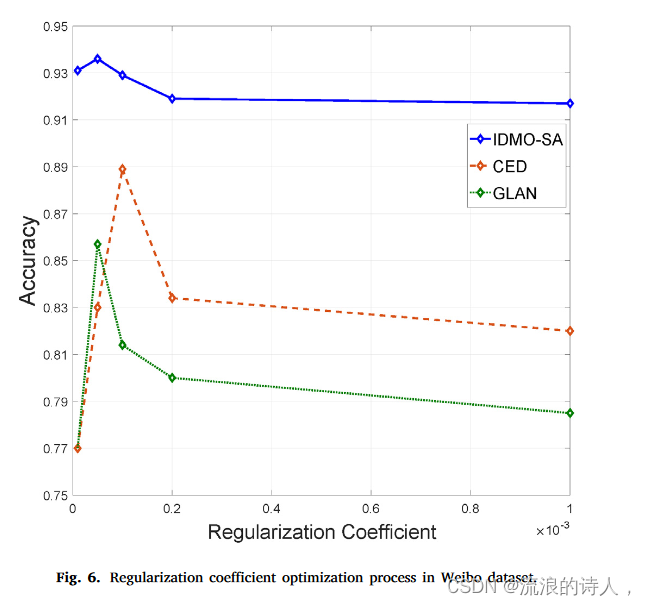
图6.微博数据集中正则化系数优化过程。
图6总结了当正则化系数在[10e−6, 10e−3]范围内时IDMO-SA、CED和GLAN的精度,其中对应的最佳系数值为6e−5、1e−4和5e−5 , 分别。
5.4. Performance evaluation
在本小节中,我们在表2-4中提供了详细的比较结果,分别对应于Weibo数据集、Twitter数据集和Snopes数据集。需要注意的是,Snopes数据集是在线新闻媒体的数据集,不具备传统社交网络的转发功能。但新闻媒体也充斥着谣言,不容忽视。因此,我们按照评论的发布时间对他们的评论进行排名,并将评论序列视为转发序列。考虑到DSTS、CAMI和GLAN无法获得ER和MS所需的数据,因此本文仅与CED方法进行比较。我们在表中将每个评估指标的所有最佳结果加粗。
表2展示了微博数据集的详细实验结果,其中所提出的IDMO-SA方法达到了93.6%的最高准确率。在精确率和召回率方面,IDMO-SA的性能明显优于基线,分别达到91.3%和94.6%。 IDMO-SA的早期率达到37.6%,高于CDE的早期率(32.7%)。然而,IDMO-SA的稳定性达到18.7%,明显低于CDE(64.1%)。这是因为CED在追求早期检测时部分忽略了实验结果的稳定性,从而可能导致检测结果出现误差。因此,我们可以看到,牺牲14.9%的检测时间来换取2.5倍的稳定性是值得的。
表3展示了Twitter数据集的详细实验结果。与微博数据集不同,Twitter引入了未经验证的信息,这在一定程度上增加了学习难度。由于 Twitter 中包含的数据量低于微博数据集,可能会导致学习不足。因此,表3中的各种指标的值相对低于表2中的值。尽管如此,IDMO-SA的性能与基线相比仍然显着提高。在准确率、精确率和召回率方面,IDMO-SA 在实验中获得了最好的结果,分别达到了 81.8%、74.9% 和 89.6%。 IDMO-SA的早期率达到49.9%,比CED低19.3个百分点。稳定性方面,IDMO-SA达到37.4%,比CDE提高了63.1%。
表4展示了Snopes数据集的详细实验结果,该数据集还包含未经验证的信息和较少的数据量。与 Twitter 每条推文都有字数限制不同,新闻媒体通常会发布更多文字的内容。这非常有利于注意力机制的训练。因此,IDMO的准确率比基线提高了约10%,远远超过了微博和Twitter数据集上的表现。就早期率而言,IDMO-SA(43.7%)的表现与CED(43.6%)相同。而且稳定性明显优于CDE,MS值降低约96.5%。
5.5. Sensitivity analysis
5.5.1. The initial point of the detection interval
检测间隔的起始点决定了是否启动间隔检测过程,进而决定了IDMO-SA的整体性能。如果α值太大,可能会导致间隔检测无法正常工作,导致ER和MS升高。如果α值太低,则检测阈值太低,在没有充分训练的情况下过早开始间隔检测进行预测可能会降低其准确性并增加MS值。
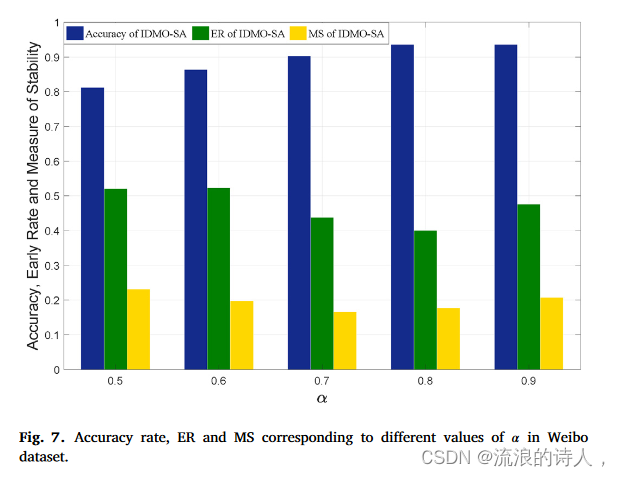
图 7 微博数据集中不同 α 值对应的准确率、ER 和 MS。
从以下范围{0.5,0.6,0.7,0.8,0.9}比较不同的α值,如图7所示。我们注意到,随着α的增加,IDMO-SA的准确率逐渐增加并趋于收敛于 0.8。对比α=0.8和0.9,我们认识到准确率已经稳定在93.6%,但是ER和MS都有一定程度的提高。这说明α并不是越大越好。如果α太大,多目标损失模块运行得太晚,导致早期检测和稳定性训练不足。比较α=0.5、0.6、0.7和0.8,我们还发现α太小也会影响其ER和MS。这是因为预测初期的结果非常不稳定(见图3)。当α很小时,这些不稳定的结果会过早地开启多目标检测模块,然后导致其ER和MS增加。因此,在实验中寻找合适的α是非常有必要的。
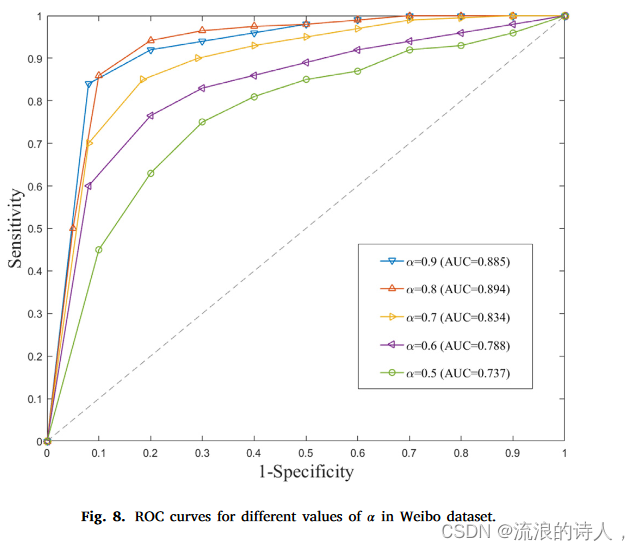
不同α值的ROC曲线如图8所示。灵敏度值越大,模型对真阳性样本的检测结果越好; 1-特异性的值越小,模型对假阳性样本的检测效果越好。我们注意到,随着α的增加,其ROC曲线更接近(1, 0),表明模型的性能也在提高。当α=0.8和α=0.9时,不再可以直接通过ROC曲线来判断。我们计算ROC曲线下面积(AUC),并注意到当α=0.8时,AUC达到最大值0.894,所提出模型的性能最好。
5.5.2. The length of the detection interval
检测间隔的长短决定了检测过程中的训练量,进而决定了IDMO-SA的整体性能。直观上,检测间隔越长,训练结果越充分,性能越好。然而,过长的检测间隔可能会导致训练冗余,这不会提高其准确性,同时会增加计算量。
为了找到合适的检测间隔长度,我们比较了以下范围{25,50、100、200、300}。
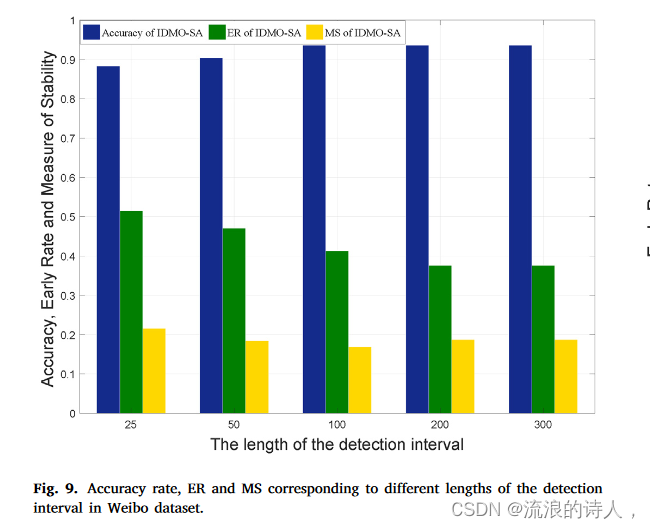
图 9 微博数据集中不同检测间隔长度对应的准确率、ER 和 MS。
图9说明了不同长度的准确率、ER和MS。从实验结果中我们注意到,随着间隔长度的增加,准确率逐渐增加,ER和MS逐渐下降。当长度为100时,准确率趋于收敛。当长度为200时,虽然区间长度增加,但其准确率、ER和MS不再变化。
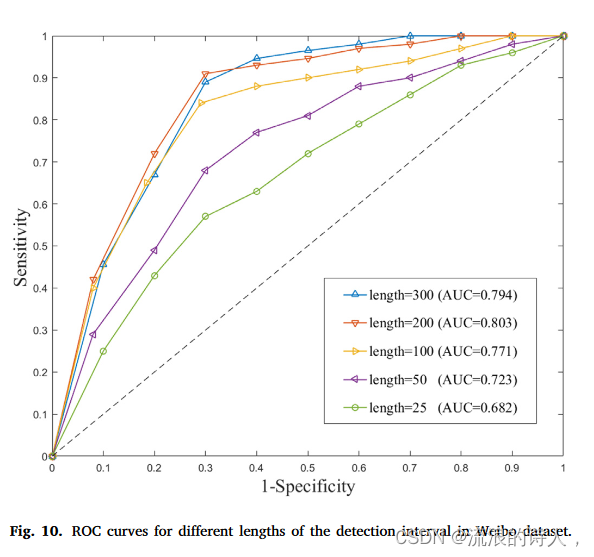
图 10. 微博数据集中不同检测间隔长度的 ROC 曲线。
不同检测间隔长度的ROC曲线如图10所示。灵敏度值越大,模型对真阳性样本的检测效果越好; 1-特异性的值越小,模型对假阳性样本的检测效果越好。我们注意到,随着长度的增加,其 ROC 曲线更接近 (1, 0),表明模型的性能也在提高。当length=100、length=200、length=300时,不再可以直接通过ROC曲线来判断。我们计算ROC曲线下面积(AUC),并注意到当长度= 200时,AUC达到最大值0.803,所提出模型的性能最好。
5.5.3. The early detection
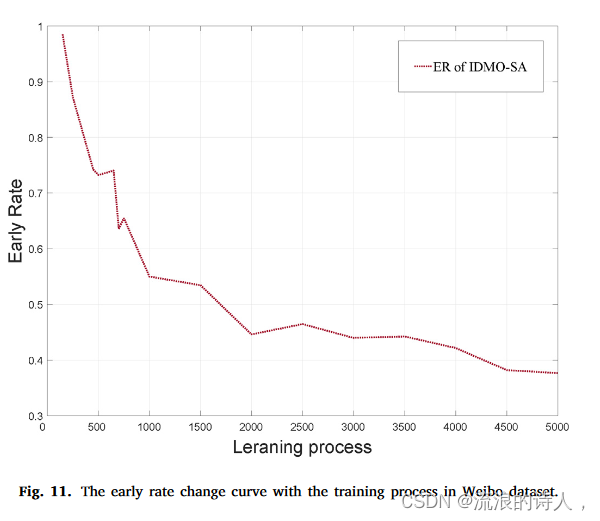
图11.微博数据集中训练过程的早期速率变化曲线。
早期率是为了评估当预测结果大于某个固定值(该值设置为0.875)时所花费的时间。 ER值越小,意味着预测结果可以在更短的时间内达到0.875。图11展示了微博数据集训练过程中ER值变化的详细趋势。在训练过程初期,虽然部分区域ER略有上升,但总体上仍保持快速下降的趋势。随着训练过程的继续,多目标损失函数不断调整预测结果。随着预测结果不断增加,检测区间不断移动调整,最终收敛到0.376。
5.5.4. The stability analysis
(34)中的稳定性测度用于评估预测结果的波动程度。当预测值大于固定值(0.875)时,我们以该时刻为初始点,构造一个固定长度(100)的区间,然后计算每个预测值与该区间内平均值的差值。因此,MS越小,预测结果越稳定。
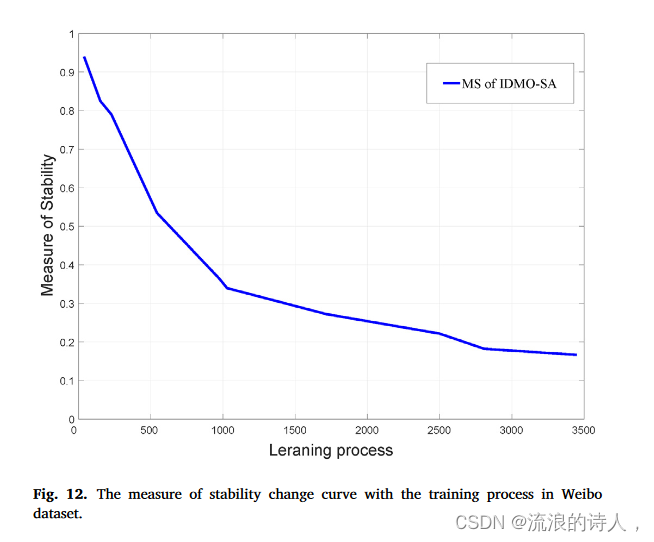
图12.微博数据集中训练过程稳定性变化曲线的测量。
图12展示了微博数据集训练过程中MS值变化的详细趋势。在训练过程的早期,MS值急剧下降,这意味着在这个阶段,在多目标损失函数的不断调整下,预测结果之间的差距不断缩小。在训练过程的中后期,MS值收敛到0.187,预测结果变得稳定,这无疑说明了多目标损失函数的有效性。
6. Conclusion
在本文中,我们提出了一种新的 OSN 中谣言检测方法(IDMO-SA)。我们利用源微博的文本内容和时间戳以及相应的报道序列作为输入,通过具有空间注意力机制的CNN网络提取关键特征图,解决了丢失局部重要信息的问题。然后,这些特征图被输入到GRU模块中,以进一步探索谣言在传播过程中的更多特征。为了实现早期检测,我们将检测点作为训练目标,在训练过程中不断调整和优化,而不是使用预设值,从而增强其适应性和通用性。同时,将准确性和稳定性作为另外两个训练目标,以保证检测的可靠性。由于在聚合多目标时引入了影响最终结果的超参数,我们利用基于凸优化技术的简洁有效的方法对它们进行参数化,以便它们能够在整个模型学习过程中自适应变化。与传统方法需要整个序列数据集作为测试样本不同,为了降低计算成本,我们提出了滑动区间检测方法,只需找到检测点并在检测区间内进行检测。通过不断学习特征,自适应调整检测点,使其更具普适性。通过实验,我们系统地验证了所提出方法的有效性,结果表明所提出的方法优于state-of-art方法。
值得注意的是,我们认为更重要的是谣言是否是故意制造的。很多科学发现后来被发现是错误的,但我们并不认为它们是谣言。在本文中,我们主要关注在线社交网络中的文本谣言。然而,近年来,谣言开始出现一些新的形式:图片谣言、图片与文字混合的谣言、视频谣言以及视频与文字混合的谣言,不仅限于文字形式。未来我们将研究多媒体谣言(如图片、视频等)的检测,并从用户关系(如关系网络结构)的角度进一步探索。

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









