








ABSTRACT
在线社交网络为信息共享提供了便捷的平台,假新闻和谣言的传播盛行,对美国和雅加达选举等重大事件造成严重后果。现有的工作已经设计了方法来找到一组前k名用户来发起真相活动并减轻错误信息的负面影响。假设这些排名前 k 的用户是开放的并且愿意传播经过事实核查的内容。此外,这些方法假设随着错误信息和反消息在网络中传播,用户意见一旦形成就不会改变。在这项工作中,我们解决了一个更现实的场景,即用户的意见可能会在某个截止日期之前波动,目标是从一组揭穿者中找到一组好的种子用户,以最大程度地减少错误信息的影响。我们提出了一种新的意见模型,该模型考虑了用户的偏见及其社交邻居的意见。基于这个模型,我们设计了一个缓解解决方案来识别揭穿者的子集,从而最大限度地增加暴露于错误信息但选择相信反驳消息的用户数量。 Facebook 和 Twitter 数据集上的实验表明,我们提出的解决方案可以有效减轻错误信息的负面影响。
1 INTRODUCTION
Twitter、Facebook、微博等在线社交网络 (OSN) 是促进联系和互动的平台用户之间是核心目标,这是通过允许用户与其他用户形成链接并向其关注者传播信息来实现的。 OSN 是用户超越地理限制建立、维护和扩展社交网络的一种手段。个人通过个性化的个人资料页面、帖子(例如状态更新、链接和上传的媒体)以及对其他用户内容的公开认可/拒绝(通过回复、点赞和转发)向他人表明自己的身份、兴趣和意图。用户通常将自己组织成反映成员共同点的社区,其中可能包括共同的友谊、文化背景、政治意识形态、兴趣等。
随着社交媒体成为大多数人获取和分享信息/观点的主要场所,人们越来越担心共享内容的准确性和真实性的传播,特别是极端意识形态的传播。这种负面影响不仅对平台用户构成威胁,还对企业和政府构成威胁,包括影响选举结果[2, 6]。因此,需要制定策略来应对和限制 OSN 负面影响的蔓延。现有的研究重点是检测错误信息 [18, 23],开发自动检查信息可信度的系统 [4, 7, 12] 并验证社交媒体内容 [14, 30]。尽管做出了这些努力,假新闻仍然在社交媒体上像野火一样传播。
另一个研究分支已经认识到假新闻将永远是社交媒体现象的一部分,并已指导努力寻找方法,通过识别一组传播反信息的用户来减轻和最小化假新闻的负面影响 [20, 22 ,25]。这些工作假设除了谣言发起者之外的任何用户都愿意在收到请求时传播反消息。然而,研究表明,并非所有用户都是开放的并愿意向其他用户传播经过事实核查的内容[24]。更现实的场景是拥有一组被称为揭穿者的用户,只要谣言流传,他们就愿意并且可以被激活来传播反消息。
此外,这些作品采用的传播机制假设用户的意见一旦形成就不会改变。然而,在实践中情况并非如此,用户的意见可能会根据他们的社交邻居的意见和他们自己固有的偏见而波动[8]。因此,我们提出了一种新的用户意见模型来捕获此类波动。
根据我们的意见模型,我们开发了一种名为 MIST(最小化虚假信息)的缓解解决方案,该解决方案可识别揭穿者的子集,以对抗在线社交网络中负面影响的传播。在 Facebook 和 Twitter 上进行的实验表明,我们的解决方案始终优于最先进的方法和启发式方法,并且导致听过谣言但选择相信反驳消息的用户比例最高,在 Facebook 和 Twitter 上达到了 50% 以上。 Twitter 上的关注度超过 30%。
2 RELATED WORK
在假新闻传播中,重点是找到最小的节点集,这些节点的免疫将最大限度地减少假新闻在网络上的传播。这被称为 NP 困难的影响阻塞问题。
阿莫鲁索等人。 [1]提出了一种两步启发式方法,首先识别一组最可能的错误信息来源,然后在网络中放置监视器以阻止错误信息的传播。杨等人。 [29]研究影响阻塞问题的两个版本,称为“中断损失最小化”和“保证目标扩散最小化”。前者专注于寻找具有最小程度或PageRank的top-k节点集合,而后者旨在找到最小节点集合,使得目标集合中的所有节点都受到影响,同时传播到网络的其余部分被最小化。
范等人。 [16] 研究了有针对性的错误信息阻止问题,其目标是找到最小的节点集,将其删除将减少错误信息影响至少某个给定的阈值 γ。作者提出了一种可扩展的算法,该算法生成 η 个样本图,并通过深度优先搜索计算每个样本图中节点的影响力降低。选择平均影响力降低最高的前 k 个节点来阻止传播。
[19, 27] 中的工作研究了自适应影响阻止问题,其中在每个时间步骤,选择一组不同的 k 节点来阻止负面影响传播。王等人。 [26]提出了一种动态谣言影响最小化模型,其中每个节点都被分配了一个容忍时间阈值,如果用户的阻塞时间超过其阈值,网络的效用就会降低。
多项研究表明,减轻社交网络中错误信息负面影响的更有效、可行的方法是发起“真相活动”,为用户提供不同的观点。Budak 等人[3]表明,选择最少的用户群体在网络中传播正面信息是 NP 困难的,并且为贪婪解决方案提供近似保证 Nguyen 等人[15]提出了一种称为 Greedy Viral Stopper 的贪婪算法,其中他们迭代地选择一个节点来净化和传播好的信息。 Tong等人[22]研究了启动具有不同级联优先级的多个扩散级联的问题,并提出了一种数据相关的近似算法,并通过实验证明了近似率接近恒定。所有数据集。
宋等人。 [20] 观察到存在一个最后期限,在此之后错误信息的影响很小或没有影响。作者提出了一个两步解决方案来识别前 k 个真相活动者,他们可以在给定的截止日期之前拯救最大数量的节点免受谣言的影响。他们引入了节点威胁级别的概念,并利用加权反向可达树[21]贪婪地选择前k个节点来发起真相活动。
法拉吉塔巴尔等人。 [5]使用强化学习框架设计基于点过程的干预技术。他们将错误信息和反信息的时间随机性建模为多元点过程,并构建奖励函数来衡量预算约束下缓解活动的有效性。 Wilder 和 Vorobeychik [28] 采用博弈论方法,攻击者防御策略使用零和博弈,攻击者试图通过传播错误信息来颠覆选举,而防御者的目标是尽量减少攻击者的影响。他们提出了多项式时间近似算法来计算防御者的极小极大最优策略,并表明他们的策略提供了接近最优的回报。
上述所有工作都假设用户对错误信息或反新闻的看法一旦形成,就不会改变。相比之下,我们提出的解决方案允许灵活地改变用户意见。
3 PROBLEM FORMULATION
在线社交网络可以建模为一个带权有向图 G = V, E,其中 V 中的节点是用户,E 中的边 u, v 表示用户 u 和 v 之间的关系。扩散是信息在网络中传播的过程。来自种子用户的网络。给定一组传播一些错误信息的种子用户 M 和一组候选揭穿者 D,我们希望识别一组用户 D* ⊂ D 来发起反驳消息来揭穿错误信息。
每个用户u都有一个在离散时间t内演化的状态,描述了用户对M传播的错误信息和D*发起的反消息的总体信念或意见。我们将在 M 的攻击和 D* 的反击下的用户状态表示为向量 πuG,其中每个元素 πuGM, D*, t ∈ −1, 0, 1。−1 值表示 u 相信错误信息,0表示你是中立的,1表示你相信反驳消息。在没有歧义的情况下,我们将符号简化为 πut。此外,每个用户 u 都有两种源自其认知和社会偏见的内部偏见,一种是错误信息 m,另一种是反消息 d,分别用 bum 和 bdu 表示。
与每条边 u 相关联,v 是一个实数 pu,v ∈ 0, 1 表示从 u 到 v 的影响概率。根据 u 的置信度,无论 πut = 1(或 −1),u 都会传播计数器消息(或错误信息)并尝试以概率 pu,v 影响 v。如果 πut = 0,则 u 不会向 v 传播任何信息.
t 每次 t ≥ 0 时,我们区分两种类型的节点:持久节点和常规节点。持久节点是永不改变信念的用户,而常规节点是用户他们根据 G 中邻居的状态定期更新自己的信念。传播错误信息的种子用户集 M 和候选揭穿者集 D 是持久节点。换句话说,对于所有 t ε 0, α, u ε M , v ε D,我们有 πut = −1 和 πvt = 1。不持久的节点是常规节点,用 R 表示。然后G 为 V = M ∪ D ∪ R。
令 y 为一个节点,使得 πyα = 1,并且存在某个时间 β < α,其中 πyβ = -1。我们说 y 在截止日期是一个已保存的节点,因为它在某个时刻相信了错误信息,但最终接受了针对错误信息的反消息。
问题定义:给定一个图 G = V,E,一个截止日期 α,一组传播错误信息的种子用户 M,以及一组候选揭穿者 D。令 S ⊆ R 为状态为 1 的节点集合t = α,并且 I ⊆ R 是在某个 t < α 时状态为 -1 的节点的集合。我们想要找到一个给定大小 k 的集合 D* ⊂ D,使得保存的节点数量最大化,如下所示:
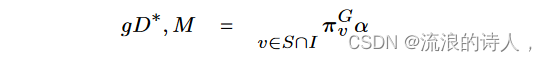
4 USER OPINION MODEL IN MIST
在本节中,我们将描述当错误信息和反消息传播时,如何对社交网络中用户的信念进行建模和更新。
回想一下,我们有一组传播错误信息的种子用户 M 和一组候选揭穿者 D。这些是其信念永远不会改变的持久节点。常规节点集 R 是用户,其信念取决于网络中邻居的状态。最初,我们有 πvεM 0 = −1,πvεD0 = 1,πvεR0 = 0。
在时间 t,每个常规节点 v 将根据其邻居在时间 t − 1 时的信念接收反消息和错误信息。现有的计算社会科学方法将 v' 信念更新为其邻居个体影响的总和。然而,在Facebook和Twitter等社交网站上,错误信息和反信息的帖子持续存在,它们对用户的集体影响不仅仅是个人影响的总和。我们使用概率计算来捕获这一点,其中 v 对反消息 d 的信念取决于 v 自身的固有偏差和 v 邻居的状态,使得 v 不相信其邻居中的 d 的概率由下式给出:你| πut−1=1} 1 − pu,v * bvd 。那么v相信反新闻的概率是
![]()
类似地,v 在时间 t 对错误信息的信念由下式给出

其中 sgn(.) 是实数的符号,ε 是一些小值,用于描述用户对改变状态的抵制。
这个过程一直持续到到达最后期限α。算法 1 给出了详细信息。第 1 行到第 10 行初始化持久节点和常规节点的状态。第 11 至 25 行计算规则节点在不同时间点的置信度。第 26 至 36 行更新这些节点的状态。
5 TOP-𝑘 DEBUNKERS IN MIST
当谣言和真相同时开始传播时,在给定一组谣言发起者的情况下找到 k 个节点作为真相活动者是 NP 困难的 [3]。一个简单的解决方案是从候选集 C 的列表中枚举 k 个揭穿者的所有可能子集,并评估可以保存

最多的节点数。然而,这种强力方法的计算成本很高,因为存在 C|D| k 个子集,每个子集评估需要在截止日期 α 内运行意见模型。这种方法的时间复杂度为 Oα * |E| * C|D| k.
前 k 个揭穿者的识别与信息和观点在网络中的传播方式密切相关。给定上一节中描述的用户意见模型,我们设计了一种方法,从候选节点集合 D 中选择前 k 个节点来传播反新闻。给定一组传播错误信息的用户 M,我们首先计算 D 中每个揭穿者保存的节点数,然后选择保存最大节点数的前 k 个揭穿者。算法 2 给出了详细信息。第 1 行调用算法 1 来计算错误信息传播时网络中每个节点的信念。第 2 行到第 7 行找到在时间 = α 时受到错误信息影响的节点集 S∅。对于每个候选揭穿者 u,如果 u 被激活以启动计数器消息(第 9 行),我们调用算法 1 来计算每个节点的置信度。第 10 至 16 行找到了在看到 u 发起的计数器消息后不再相信错误信息的节点 Su 的集合。第 18 行返回保存节点数最多的前 k 个揭秘者。
6 PERFORMANCE STUDY
我们进行实验来验证意见模型并评估 top-k debunkers 算法的有效性。
6.1 Validation of MIST User Opinion Model
我们使用[11]中的 Twitter 数据集并提取 5 个具有大量推文的事件:
(1)乔治·蒂勒。此事件包含 14,495 条关于乔治·蒂勒博士在他的教堂开枪的新闻的推文。
(2) 伊朗抗议视频。此事件包含 22,653 条有关伊朗抗议视频的推文。
(3) 掌上电脑。这是关于掌上电脑 palm pre 的评论的 7,345 条推文的集合。
(4) PspGo。它有 13,458 条关于移动设备 psp go 的信息和评论的推文。
(5SwinePork.。它有 25,974 条关于猪流感可以通过猪肉传播的谣言的推文。
我们使用 TextBlob [13] 为每条推文分配极性,如果其极性 > 0,则认为推文为正,如果其极性 < 0,则认为推文为负,否则为中性。如果用户发布的正面推文多于负面推文,则其真实状态为 1,反之亦然。如果用户仅发布中性推文或相同数量的正面和负面推文,则用户的真实状态为 0。
用户 v 对错误信息的偏差 bvm 由负面推文与 v 发布的推文总数的比率给出。类似地,v 对反消息的偏差 bvd 是正面推文与发布的推文总数的比率边 u, v 的影响概率是 u 和 v 在每个类别(正面、负面和中性)中发布的推文数量中的最小值与 v 发布的推文总数的最小值之和。
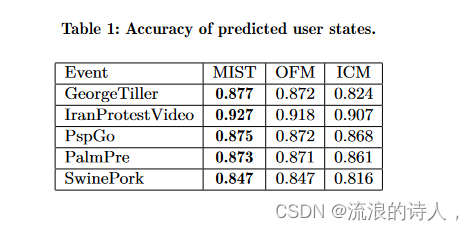
我们按时间对推文进行排序,并使用前半部分来估计用户的初始状态,并使用 MIST 中的意见模型来预测用户的最终状态。为了进行比较,我们还实现了意见形成模型(OFM)[9]以及广泛使用的独立级联模型(ICM)[10]。在 OFM 中,节点的意见由其邻居意见的平均加权和决定。如果节点 v 在时间 t 对错误信息(反消息)的意见比对反消息(错误信息)的意见大 ε = 0.1 以上,我们认为 v 在 t 的状态为 -1 (1),否则为 0。在 ICM 中,如果节点 v 尚未被激活,则它会以概率 pu,v 受到其邻居的影响。一旦激活,节点将不会改变其状态。结果如表1所示。我们看到所提出的模型在所有 5 个事件中具有最高的预测准确性。
6.2 Effectiveness of Top-𝑘 Debunkers
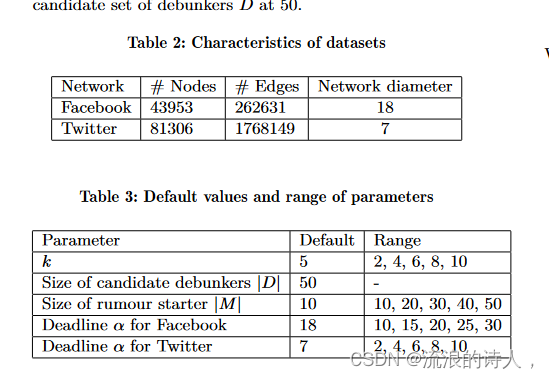
接下来,我们在两个现实世界数据集 Facebook 和 Twitter 上评估我们的 top-k debunker 算法的有效性。与 Facebook 相比,Twitter 的节点数量是 Facebook 的两倍,边数是 Facebook 的 7 倍。然而,Twitter 网络的直径比 Facebook 网络小 2.5 倍。表 1 总结了这两个数据集的特征,表 3 显示了我们实验中测试的默认值和参数范围。请注意,我们将揭穿者 D 的候选集的大小固定为 50。
每条边 v, u 的影响概率由 1 indegu 给出,其中 indegu 是节点 u 的传入边的数量 [20]。网络中的每个节点都有两个偏差值,一个用于错误信息,另一个用于反消息。在我们的实验中,我们假设网络中 x% 的节点对于错误信息 bm 有较高的偏差。我们随机分配一个 [0.7, 1] 之间的实际值 a 作为这 x% 节点的偏差。对于这些节点,它们对计数器消息的偏差 bd = 1−a。我们分别对剩余节点的 x% 进行采样,并将它们的 bd 设置为 [0.7, 1] 之间的随机值 a′。对于这些节点,它们的 bm = 1 − a′。
我们迭代地计算网络中剩余节点对错误信息的偏差,作为其父母基于相似性的偏差的加权平均值:
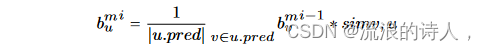
其中 i 的范围是从 1 到截止时间 α
以类似的方式获得计数器消息的节点的偏差值。我们在实验中使用 i = α 处节点的偏差值。我们分别为 Facebook 和 Twitter 设置 x = 10 和 x = 20。
我们将查找 top-k debunker 节点的方法与以下节点选择方法进行比较:
∙ 随机:这是一种基线方法,从 D 中随机选择 k 个节点。
∙ 最高出度:此方法选择 D 中出度最高的前 k 个节点。
∙ 最高加权出度:该方法选择 D 中具有最高出度的节点,并按其在 D 中的影响概率进行加权。
∙ 最小距离:该方法选择 D 中距离谣言发起者最近的前 k 个节点。节点 u 与 M 的紧密度计算如下:
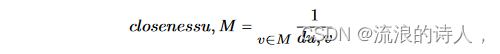
其中 d(u,v) 是从 u 到 v 的最短距离。我们还与两个最先进的解决方案进行了比较:
∙ 时间影响阻断 (TIB) [20]。 TIB首先识别在截止日期之前某些谣言可以到达的节点集合,并计算可以受这些节点影响的潜在节点数量。然后,TIB 生成加权反向可达(WRR)树来估计可达节点的数量,并选择最能在截止日期前阻止谣言的前 k 个节点作为揭穿者。
∙ 有针对性的错误信息拦截(TMB)[17]。 TMB 将节点 v 的影响力降低计算为 hv = N G−N G∖v,其中 N G 和 N G∖v 分别表示图 G 和 G ∖ v 中受谣言发起者影响的节点数量。我们选择影响力降低最高的前 k 个节点作为揭秘者
令 S 为在 t = α 时状态为 1 的节点集合,I 为在某个 t < α 时状态为 -1 的节点集合。我们根据保存的节点百分比评估各种方法的性能,计算如下:
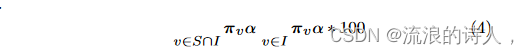
每组实验重复30次,记录保存节点的平均百分比。
我们首先检查 k 从 2 到 10 变化时各种方法的性能。截止日期由网络直径给出,即 Facebook 的 α = 18,Twitter 的 α = 7。 M 的大小为 10,ε = 0.02。
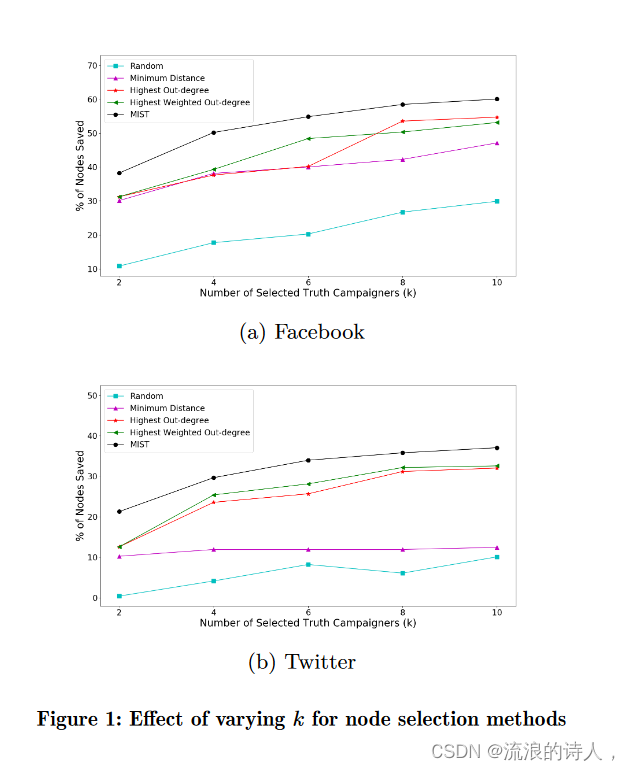
图 1 显示,我们提出的查找前 k 个揭穿者的方法始终能够实现最高比例的节点保存,在 Facebook 上达到 50% 以上,在 Twitter 上达到 30% 以上。当 k 小于 6 时,最高加权出度优于最高出度。随着 k 的增加,差距缩小,最高出度在 Facebook 上超过加权出度。使用最小距离方法来查找前 k 个揭穿者在两个网络上的结果都很差,特别是在较大的 Twitter 网络上,因为它没有考虑谣言发起者的可达性。
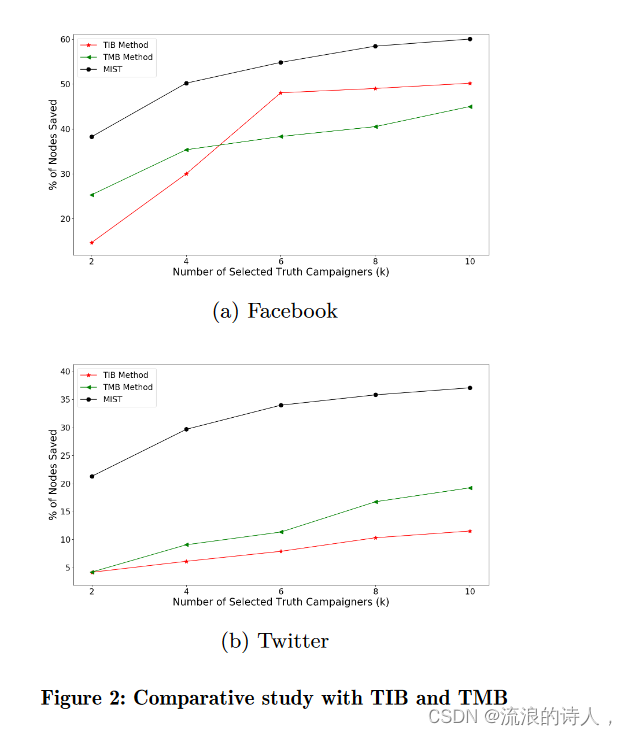
图 2 比较了 MIST 与 TIB 和 TMB 的性能,后者旨在从网络中的任何节点全局查找揭穿者。我们通过要求揭穿者必须来自揭穿者候选集 D 来调整这些解决方案。在此限制下,我们发现我们提出的方法显着优于 TIB 和 TMB。
6.3 Sensitivity Experiments
在这组实验中,我们检查了各种参数对各种方法性能的影响。改变 |M| 的效果。我们固定 k = 5,并将 M 的大小从 10 增加到 50。
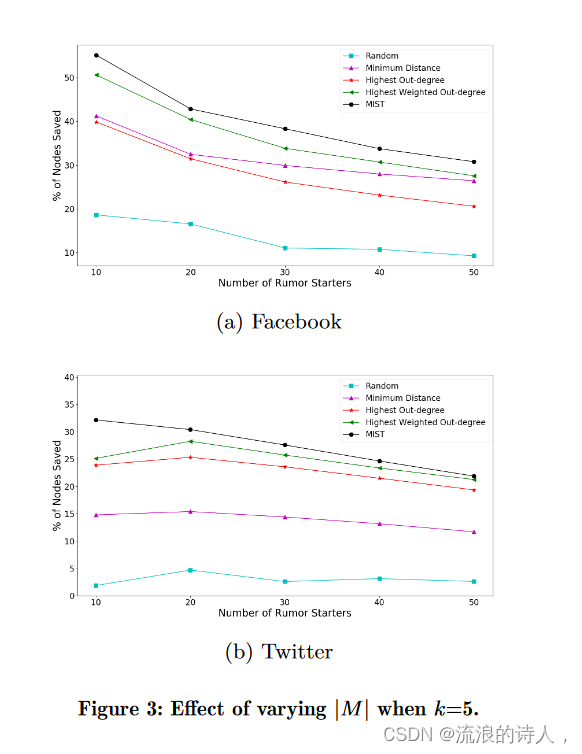
图 3 给出了结果。我们观察到,随着 Facebook 和 Twitter 上种子用户数量的增加,保存的节点百分比有所下降。然而,所提出的方法仍然优于最小距离、最高加权出度和最高出度。
改变 α 的影响。我们还研究了不同截止时间对 |M | 时保存的节点百分比的影响。 = 10 且 k = 5。
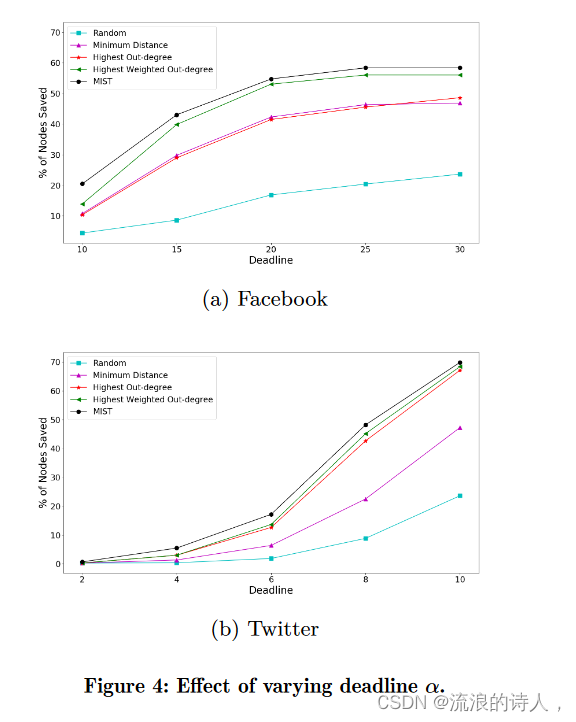
图 4 显示,保存节点的百分比随着 α 的增加而增加,而所提出的方法仍然是获胜者。我们观察到,当截止日期小于网络直径时,所提出的方法在更大程度上优于最接近的启发式加权出度。保存的节点数量随着截止时间的增加而受影响的节点数量随着截止时间的增加而增加。然而,当截止日期达到网络直径时,保存的节点数量开始稳定。
不同影响概率的影响。在这组实验中,我们从高斯分布 (μ, σ) 中采样影响概率,其中 μ = 1indegv,σ 范围从 0 到 0.1。
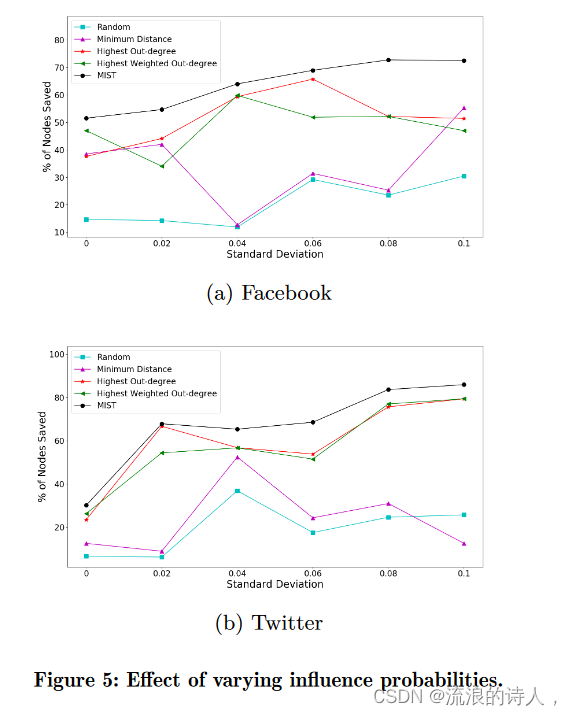
图 5 显示了各种方法的性能。我们观察到,我们提出的方法相对稳定并且始终提供最佳性能,而其他方法的性能随着我们改变 σ 而波动。
6.4 Robustness Experiments
最后,我们检查揭穿者发现即使在初始影响概率和用户偏差估计存在噪声的情况下,是否仍然能够稳健地对抗错误信息。我们模拟这个场景如下。我们首先在网络中找到具有这些初始估计的前 k 个揭穿者。然后,我们通过向从 [-η, η] 均匀采样的边缘影响概率添加一些随机数来向网络注入噪声。
图 6 显示了我们将 η 从 0.005 更改为 0.025 时的结果。我们看到,我们提出的方法识别出的前 k 个揭穿者集合继续优于现有方法。当我们向用户偏差注入噪声时,会得到类似的结果(见图 7)。
7 CONCLUSION
在这项工作中,我们研究了减轻 OSN 中错误信息的负面影响的问题,其中我们有一组已知的揭穿者,可以激活他们来传播反信息。我们提出了一种名为 MIST 的资源感知缓解解决方案,该解决方案考虑了用户意见的波动,具体取决于他们的个人偏见和社会影响力。我们提出了一种解决方案,从一组给定的揭穿者中识别出前 k 个有影响力的用户,以最大限度地增加那些接触过错误信息但在给定截止日期前选择相信反信息的用户数量。 Facebook 上的广泛实验结果和 Twitter 也证明了我们对抗错误信息负面影响的方法的有效性。我们的方法识别出的前 k 个揭穿者始终导致保存的节点百分比最高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









