









沣沣在昇思25天学习打卡营第25天|cyf515
教程很详细,代码很详细,直接copy一下,即可运行,效果图也有,
从中可以学习到很多新东西,来提升自己,用到老学到老,人生即是如此。
以下是我随便粘贴的几个小案例:
什么是Diffusion Model?
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
-
我们选择的固定(或预定义)正向扩散过程 𝑞� :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
-
一个学习的反向去噪的扩散过程 𝑝𝜃�� :通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像
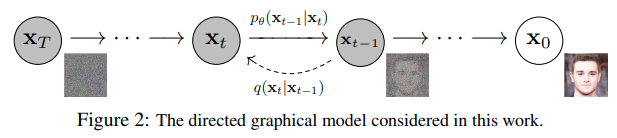
模型简介
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
最初,GAN由Ian J. Goodfellow于2014年发明,并在论文Generative Adversarial Nets中首次进行了描述,其主要由两个不同的模型共同组成——生成器(Generative Model)和判别器(Discriminative Model):
- 生成器的任务是生成看起来像训练图像的“假”图像;
- 判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。
GAN模型的核心在于提出了通过对抗过程来估计生成模型这一全新框架。在这个框架中,将会同时训练两个模型——捕捉数据分布的生成模型 𝐺� 和估计样本是否来自训练数据的判别模型 𝐷� 。
在训练过程中,生成器会不断尝试通过生成更好的假图像来骗过判别器,而判别器在这过程中也会逐步提升判别能力。这种博弈的平衡点是,当生成器生成的假图像和训练数据图像的分布完全一致时,判别器拥有50%的真假判断置信度。
用 𝑥� 代表图像数据,用 𝐷(𝑥)�(�)表示判别器网络给出图像判定为真实图像的概率。在判别过程中,𝐷(𝑥)�(�) 需要处理作为二进制文件的大小为 1×28×281×28×28 的图像数据。当 𝑥� 来自训练数据时,𝐷(𝑥)�(�) 数值应该趋近于 11 ;而当 𝑥� 来自生成器时,𝐷(𝑥)�(�) 数值应该趋近于 00 。因此 𝐷(𝑥)�(�) 也可以被认为是传统的二分类器。
用 𝑧� 代表标准正态分布中提取出的隐码(隐向量),用 𝐺(𝑧)�(�):表示将隐码(隐向量) 𝑧� 映射到数据空间的生成器函数。函数 𝐺(𝑧)�(�) 的目标是将服从高斯分布的随机噪声 𝑧� 通过生成网络变换为近似于真实分布 𝑝𝑑𝑎𝑡𝑎(𝑥)�����(�) 的数据分布,我们希望找到 θθ 使得 𝑝𝐺(𝑥;𝜃)��(�;�) 和 𝑝𝑑𝑎𝑡𝑎(𝑥)�����(�) 尽可能的接近,其中 𝜃� 代表网络参数。
𝐷(𝐺(𝑧))�(�(�)) 表示生成器 𝐺� 生成的假图像被判定为真实图像的概率,如Generative Adversarial Nets中所述,𝐷� 和 𝐺� 在进行一场博弈,𝐷� 想要最大程度的正确分类真图像与假图像,也就是参数 log𝐷(𝑥)log�(�);而 𝐺� 试图欺骗 𝐷� 来最小化假图像被识别到的概率,也就是参数 log(1−𝐷(𝐺(𝑧)))log(1−�(�(�)))。因此GAN的损失函数为:
min𝐺max𝐷𝑉(𝐷,𝐺)=𝐸𝑥∼𝑝𝑑𝑎𝑡𝑎(𝑥)[log𝐷(𝑥)]+𝐸𝑧∼𝑝𝑧(𝑧)[log(1−𝐷(𝐺(𝑧)))]min�max��(�,�)=��∼�����(�)[log�(�)]+��∼��(�)[log(1−�(�(�)))]
从理论上讲,此博弈游戏的平衡点是𝑝𝐺(𝑥;𝜃)=𝑝𝑑𝑎𝑡𝑎(𝑥)��(�;�)=�����(�),此时判别器会随机猜测输入是真图像还是假图像。下面我们简要说明生成器和判别器的博弈过程:
- 在训练刚开始的时候,生成器和判别器的质量都比较差,生成器会随机生成一个数据分布。
- 判别器通过求取梯度和损失函数对网络进行优化,将靠近真实数据分布的数据判定为1,将靠近生成器生成出来数据分布的数据判定为0。
- 生成器通过优化,生成出更加贴近真实数据分布的数据。
- 生成器所生成的数据和真实数据达到相同的分布,此时判别器的输出为1/2。
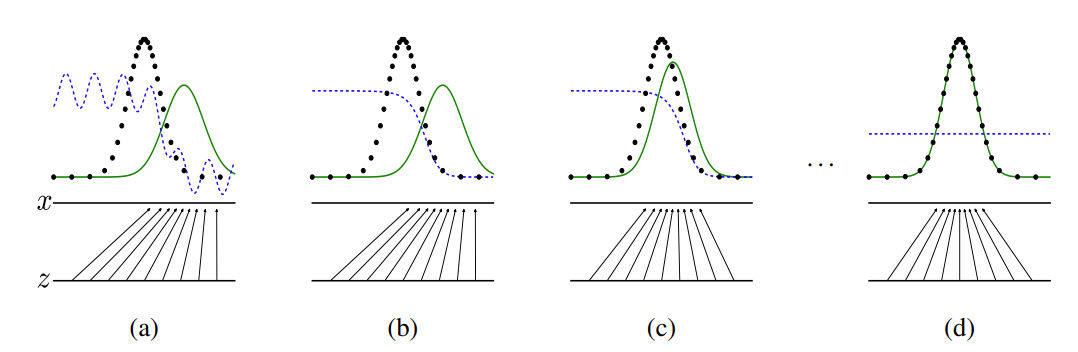
在上图中,蓝色虚线表示判别器,黑色虚线表示真实数据分布,绿色实线表示生成器生成的虚假数据分布,𝑧� 表示隐码,𝑥� 表示生成的虚假图像 𝐺(𝑧)�(�)。该图片来源于Generative Adversarial Nets。详细的训练方法介绍见原论文。
基于MindNLP+MusicGen生成自己的个性化音乐
MusicGen是来自Meta AI的Jade Copet等人提出的基于单个语言模型(LM)的音乐生成模型,能够根据文本描述或音频提示生成高质量的音乐样本,相关研究成果参考论文《Simple and Controllable Music Generation》。
MusicGen模型基于Transformer结构,可以分解为三个不同的阶段:
- 用户输入的文本描述作为输入传递给一个固定的文本编码器模型,以获得一系列隐形状态表示。
- 训练MusicGen解码器来预测离散的隐形状态音频token。
- 对这些音频token使用音频压缩模型(如EnCodec)进行解码,以恢复音频波形。
MusicGen直接使用谷歌的t5-base及其权重作为文本编码器模型,并使用EnCodec 32kHz及其权重作为音频压缩模型。MusicGen解码器是一个语言模型架构,针对音乐生成任务从零开始进行训练。
MusicGen 模型的新颖之处在于音频代码的预测方式。传统上,每个码本都必须由一个单独的模型(即分层)或通过不断优化 Transformer 模型的输出(即上采样)进行预测。与传统方法不同,MusicGen采用单个stage的Transformer LM结合高效的token交织模式,取消了多层级的多个模型结构,例如分层或上采样,这使得MusicGen能够生成单声道和立体声的高质量音乐样本,同时提供更好的生成输出控制。MusicGen不仅能够生成符合文本描述的音乐,还能够通过旋律条件控制生成的音调结构。
案例如下:
可视化
通过 create_dict_iterator 函数将数据转换成字典迭代器,然后使用 matplotlib 模块可视化部分训练数据。
import numpy as np
import matplotlib.pyplot as plt
mean = 0.5 * 255
std = 0.5 * 255
plt.figure(figsize=(12, 5), dpi=60)
for i, data in enumerate(dataset.create_dict_iterator()):
if i < 5:
show_images_a = data["image_A"].asnumpy()
show_images_b = data["image_B"].asnumpy()
plt.subplot(2, 5, i+1)
show_images_a = (show_images_a[0] * std + mean).astype(np.uint8).transpose((1, 2, 0))
plt.imshow(show_images_a)
plt.axis("off")
plt.subplot(2, 5, i+6)
show_images_b = (show_images_b[0] * std + mean).astype(np.uint8).transpose((1, 2, 0))
plt.imshow(show_images_b)
plt.axis("off")
else:
break
plt.show()
数据加载
将PASCAL VOC 2012数据集与SDB数据集进行混合。
import numpy as np
import cv2
import mindspore.dataset as ds
class SegDataset:
def __init__(self,
image_mean,
image_std,
data_file='',
batch_size=32,
crop_size=512,
max_scale=2.0,
min_scale=0.5,
ignore_label=255,
num_classes=21,
num_readers=2,
num_parallel_calls=4):
self.data_file = data_file
self.batch_size = batch_size
self.crop_size = crop_size
self.image_mean = np.array(image_mean, dtype=np.float32)
self.image_std = np.array(image_std, dtype=np.float32)
self.max_scale = max_scale
self.min_scale = min_scale
self.ignore_label = ignore_label
self.num_classes = num_classes
self.num_readers = num_readers
self.num_parallel_calls = num_parallel_calls
max_scale > min_scale
def preprocess_dataset(self, image, label):
image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)
label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
sc = np.random.uniform(self.min_scale, self.max_scale)
new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])
image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)
image_out = (image_out - self.image_mean) / self.image_std
out_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)
pad_h, pad_w = out_h - new_h, out_w - new_w
if pad_h > 0 or pad_w > 0:
image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)
label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)
offset_h = np.random.randint(0, out_h - self.crop_size + 1)
offset_w = np.random.randint(0, out_w - self.crop_size + 1)
image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]
label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]
if np.random.uniform(0.0, 1.0) > 0.5:
image_out = image_out[:, ::-1, :]
label_out = label_out[:, ::-1]
image_out = image_out.transpose((2, 0, 1))
image_out = image_out.copy()
label_out = label_out.copy()
label_out = label_out.astype("int32")
return image_out, label_out
def get_dataset(self):
ds.config.set_numa_enable(True)
dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],
shuffle=True, num_parallel_workers=self.num_readers, num_samples=20)
transforms_list = self.preprocess_dataset
dataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],
output_columns=["data", "label"],
num_parallel_workers=self.num_parallel_calls)
dataset = dataset.shuffle(buffer_size=self.batch_size * 10)
dataset = dataset.batch(self.batch_size, drop_remainder=True)
return dataset
# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,
image_std=IMAGE_STD,
data_file=DATA_FILE,
batch_size=train_batch_size,
crop_size=crop_size,
max_scale=max_scale,
min_scale=min_scale,
ignore_label=ignore_label,
num_classes=num_classes,
num_readers=2,
num_parallel_calls=4)
dataset = dataset.get_dataset()训练集可视化
运行以下代码观察载入的数据集图片(数据处理过程中已做归一化处理)。
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
# 对训练集中的数据进行展示
for i in range(1, 9):
plt.subplot(2, 4, i)
show_data = next(dataset.create_dict_iterator())
show_images = show_data["data"].asnumpy()
show_images = np.clip(show_images, 0, 1)
# 将图片转换HWC格式后进行展示
plt.imshow(show_images[0].transpose(1, 2, 0))
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()
打卡
















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









