






Paddle3D & Apollo部署(目前所有资料的汇总)
Apollo是由百度开源的开放、完整、安全的自动驾驶平台,助力开发者快速搭建自动驾驶系统。
- Apollo官方仓库:
https://github.com/ApolloAuto/apollo
Paddle3D和Apollo在持续性的进行合作开发,目前已提供视觉感知模型SMOKE、CaDDN,点云感知模型PointPillars、CenterPoint,BEV感知模型PETR的训推打通。用户可以在Paddle3D进行模型的训练、测试、导出,然后部署集成到Apollo的感知算法部分,和下游的跟踪算法、多传感器融合算法、预测算法、规划控制算法全栈运行。同时,用户可以通过Apollo的DreamView平台联合定位、预测、规划控制模块进行仿真调试,找出Badcase指导模型的优化开发。
https://github.com/PaddlePaddle/Paddle3D

Paddle3D&Apollo集成开发,蓝色部分在Paddle3D完成,黄色部分在Apollo完成
支持模型效果快速验证、多模态模型高性能融合,实现自动驾驶全栈式技术方案的高效搭建
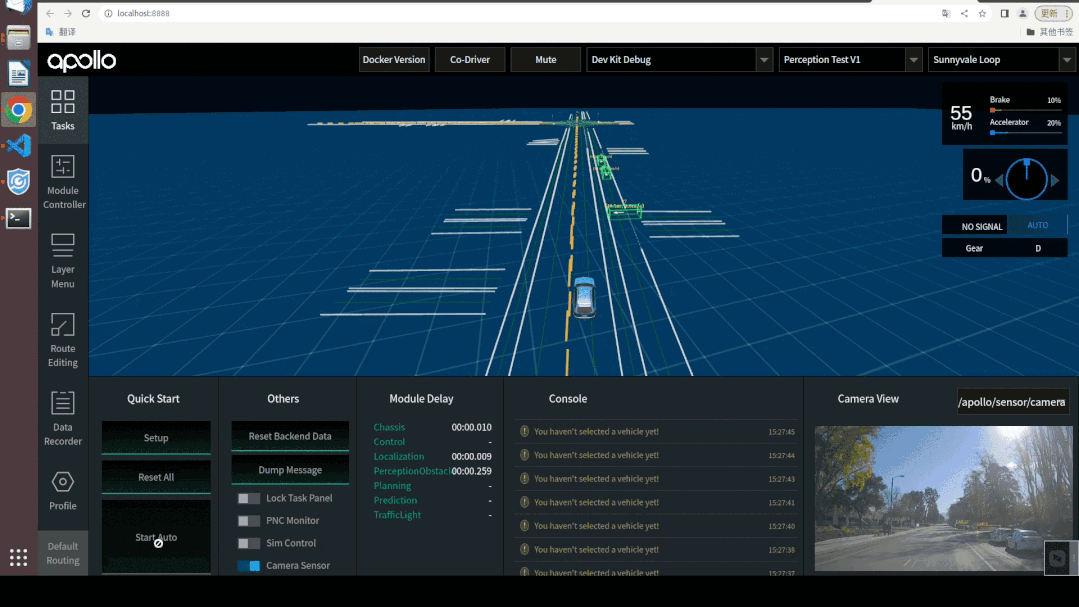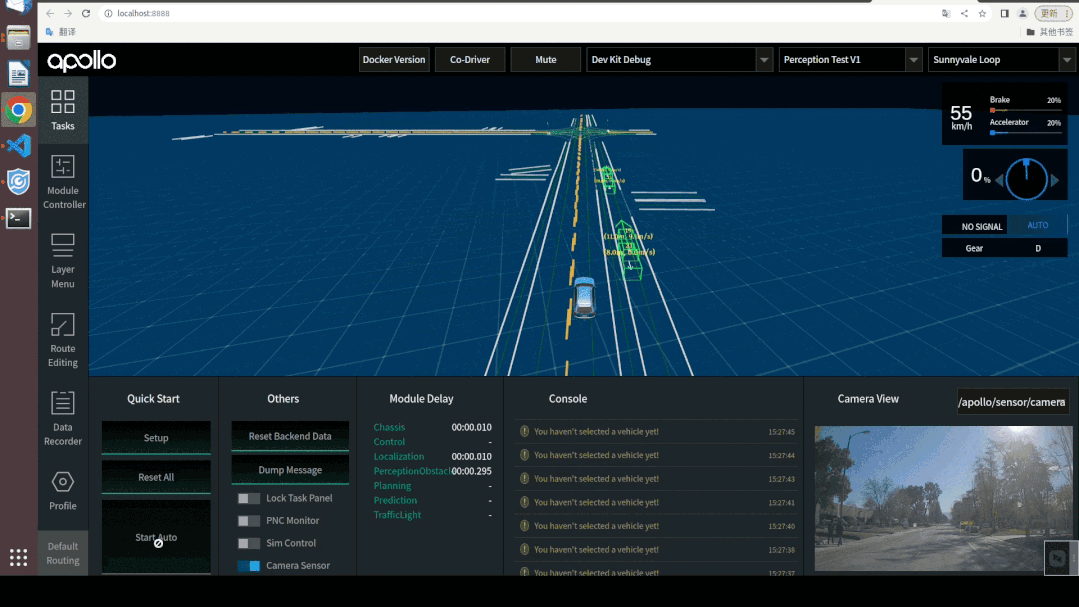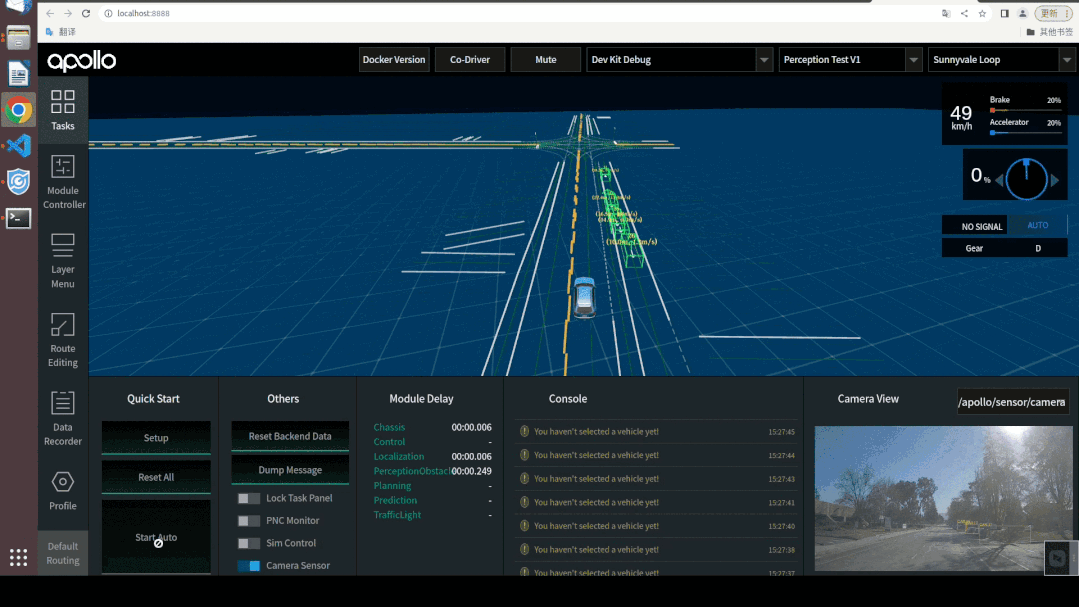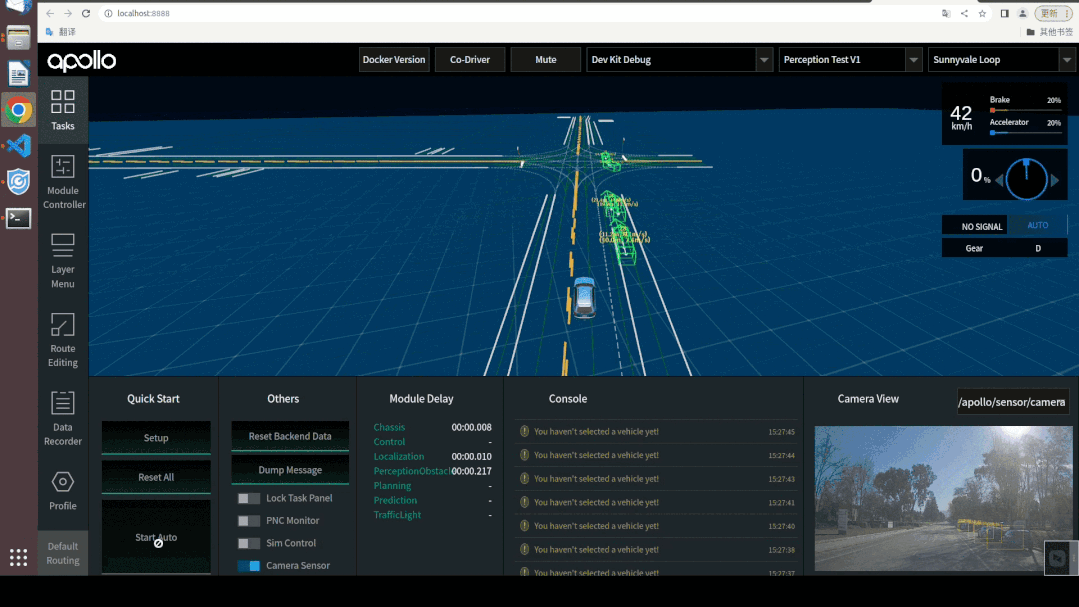
通过DreamView进行视觉感知模型仿真调试

通过DreamView进行激光雷达感知模型仿真调试
paddle3D 概览
Paddle3D是百度飞桨官方开源的端到端3D感知开发套件,套件整体结构分为框架层、基础层、算法层、工具层4层
接下来具体介绍一下Paddle3D这几部分的内容
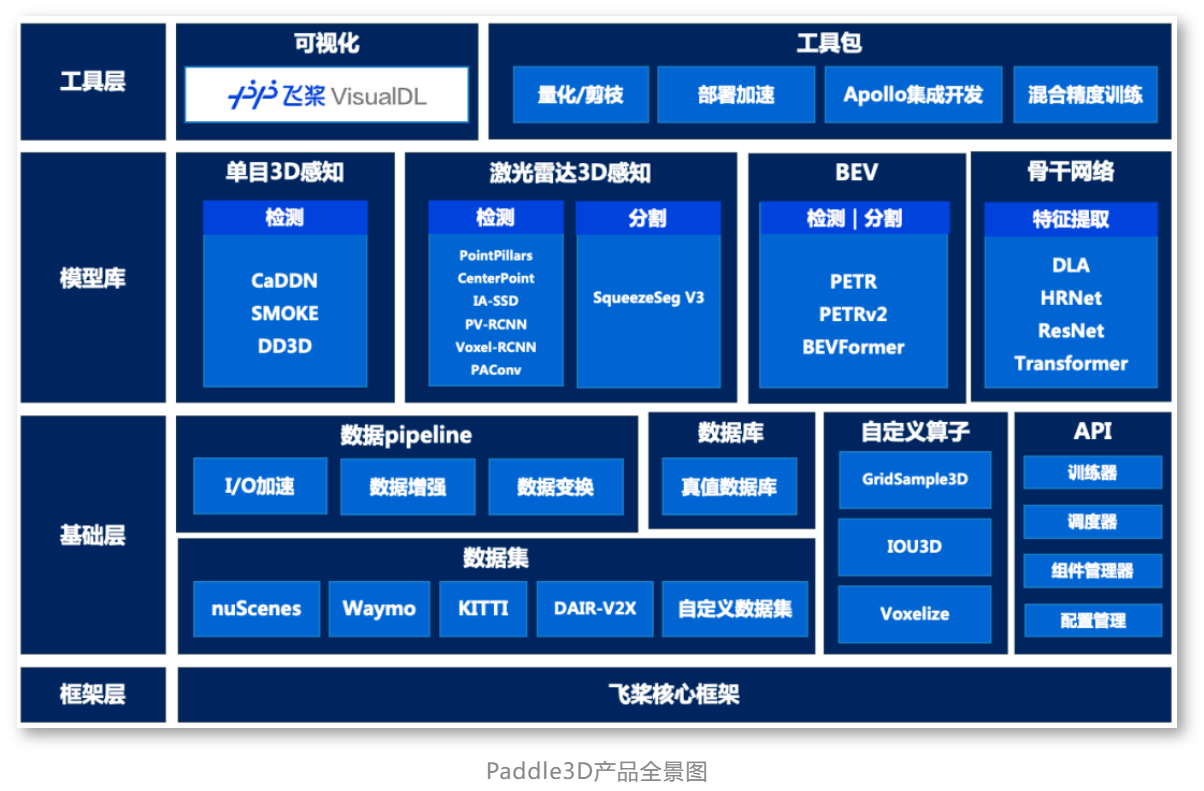
(1)基础层
基础层主要提供了数据处理管道、数据集的基础支持、自定义算子的开发支持、高级API支持。
数据处理通道
提供数据处理的I/O加速能力,提高训练阶段数据吞吐速度。同时提供多种数据变换、数据增强能力,满足3D模型的快速开发。
真值库
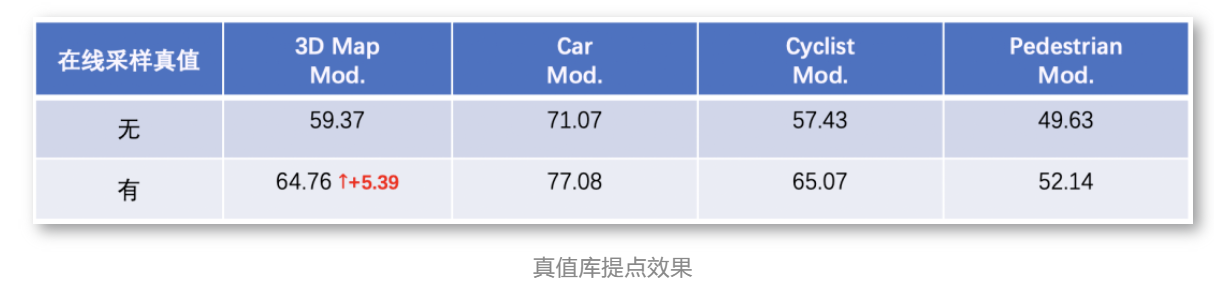
在模型精度优化方面,除了模型层面的一些优化策略,Paddle3D在数据层面也提供了基于真值库的在线优化策略。在做自动驾驶感知任务时,采集和标注点云数据所耗费的人力成本偏高,我们希望可以充分利用已有的数据来拓展训练数据的多样性。基于真值库的在线优化策略是先根据已有的训练数据离线地生成真值库,训练的过程中在线地从真值库里面随机采样一些真值目标,放到当前帧中来合成一帧新的点云,从而提升模型的泛化能力
下图是使用这个优化策略前后的精度对比情况,整体精度有5.39%的提升。

自定义算子即训即推
3D感知模型在训练过程中会遇到需要开发特色的自定义算子的情况,例如用于过滤重叠三维框的非极大值抑制操作(3D IoU NMS)、PointNet++中聚合和采样点云的操作、点云体素化操作等等。Paddle3D的模型均可基于飞桨的原生推理库Paddle Inference完成服务器端和云端的模型部署,且不需要在部署阶段重新开发自定义算子,完全做到即训即用
(2)算法层
算法层主要提供了开箱即用的单目3D感知、点云3D感知、BEV 3D感知、多模态3D感知等算法,同时提供了主流的骨干网络实现参考

在和自动驾驶开源框架Apollo的合作过程中,完成SMOKE、CaDDN这两个经典的单目3D感知模型,激光雷达3D感知模型PointPillars、CenterPoint,且已作为Apollo的原生激光雷达支持模型

在自动驾驶任务中,对周围场景的视觉感知非常重要,这一工作可以通过多个摄像头给出的二维图像完成对3D检测框或语义图的检测。
当前,最直接的解决方案是使用单目相机框架和跨相机后处理,该框架的缺点是其需要单独处理不同的视图,无法跨相机捕获信息,导致性能和效率低下。作为单目相机框架的替代方案,一种更统一的框架是从多目相机图像中提取整体表示。鸟瞰图 (Bird’s Eye-View,BEV) 是一种常用的周围场景表示方法,它能清晰地呈现物体的位置和规模,适用于各种自动驾驶任务。
而最近以BEV为基础的3D检测方案席卷自动驾驶届,目前已在Paddle3D的模型库中补充BEV经典模型PETR、PETRv2、BEVFormer

(3)工具层
工具层主要提供了基于VisualDL的训练、推理效果可视化,同时提供了模型的量化部署加速能力、Apollo的集成开发能力以及混合精度训练能力
自动混合精度训练支持
自动混合精度训练(Auto Mixed Precision, AMP)是指通过混合使用单精度和半精度数据格式,加速深度神经网络训练的过程,同时保持了单精度训练所能达到的网络精度。混合精度训练能够加速计算过程,同时减少内存使用和存取,并使得在特定的硬件上可以训练更大的模型或batch size。
Paddle3D目前全面支持混合精度训练,从而进一步优化3D感知算法开发对硬件的需求,加速训练速度。
量化部署支持
模型量化是一种将浮点计算转成低比特定点计算的技术,可以有效地降低模型参数大小,降低算力、内存等资源消耗,从而提升模型在端侧硬件上的运行效果。
3D感知模型相比传统的2D检测模型往往模型更复杂,参数更多,在服务器上可能会达到不错的推理速度和精度的平衡。但是实际部署时,帧率往往达不到要求。对此,Paddle3D目前支持SMOKE、CenterPoint的量化部署,同时Paddle3D将结合飞桨团队的另一个部署神器FastDeploy对3D感知模型通过量化压缩等手段在端侧硬件进行端到端的优化,支持更多模型的量化部署
稀疏卷积支持
在基于点云的3D检测任务中,主流的解决思路会把无序的点云表示成有序的三维体素空间,精准地学习到几何结构特征的最佳方法莫过于采取3D卷积。但是3D卷积耗费非常大的显存和计算量,使得面向实时端侧场景的应用须以损失部分检测精度作为代价,将三维空间压缩至二维空间后采用2D卷积来换取速度的提升和计算量的减小。
然而,室外场景中数量高达100k的点云经过体素化后,三维体素空间的稀疏性低至0.5%,采用3D卷积会有大量零元素的计算浪费。在稀疏3D卷积中,会预先建立一个规则表,表中仅记录与卷积核相乘的非零输入元素及其输出元素在密集特征层上的位置,基于规则表完成卷积计算可避免零元素的无效运算。飞桨框架v2.4已经全面支持稀疏计算,Paddle3D也集成了许多使用稀疏3D卷积的前沿模型,如PV-RCNN、VoxelRCNN、CenterPoint。
以CenterPoint为例,基于飞桨原生推理库Paddle Inference在一块RTX 3080显卡上的推理速度可达到21.20毫秒每帧,nuScenes验证集上精度NDS(NuScenes Detection Score)可达到66.74%。

两种常用的稀疏卷积示例图
实时单目检测模型SMOKE
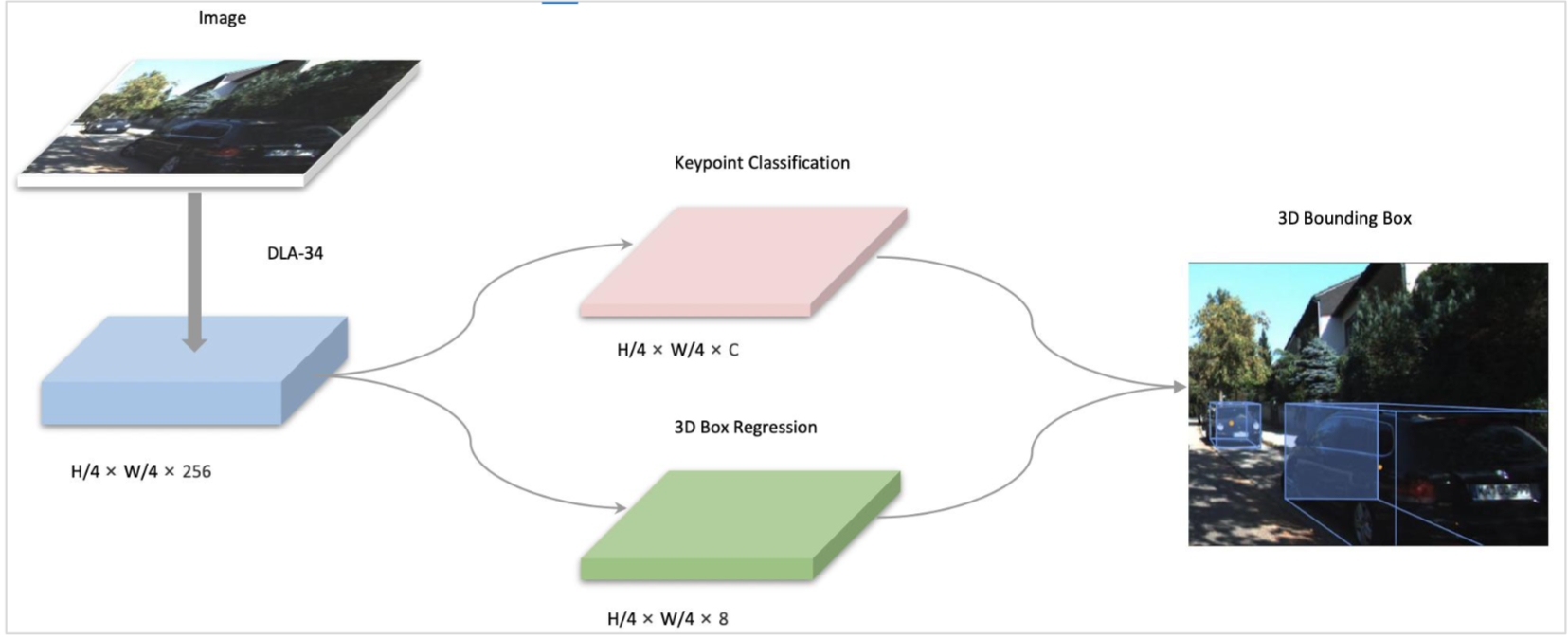
SMOKE模型结构简单,性能高效
简介
SMOKE是一个单阶段的单目3D检测模型,该论文创新性地提出了预测物体中心点投影来间接预测物体3D检测框的方法。我们参照了Apollo项目对于该模型的修改:
-
使用普通卷积替代了原论文中使用的可形变卷积
-
添加了一个头部来预测 2D 中心点和 3D 中心点之间的偏移
-
添加了另一个头部来预测 2D 边界框的宽度和高度。可以通过预测的二维中心、宽度和高度直接获得二维边界框
模型库
| 模型 | 骨干网络 | 3DmAP Mod. | Car Easy Mod. Hard | Pedestrian Easy Mod. Hard | Cyclist Easy Mod. Hard | 模型下载 | 配置文件 | 日志 |
|---|---|---|---|---|---|---|---|---|
| SMOKE | DLA34 | 2.94 | 6.26 5.16 4.54 | 3.04 2.73 2.23 | 1.69 0.95 0.94 | model | config | log | vdl |
| SMOKE | HRNet18 | 4.05 | 8.48 6.44 5.74 | 5.02 4.23 3.06 | 2.59 1.49 1.37 | model | config | log | vdl |
注意: KITTI benchmark使用4张V100 GPU训练得出。
使用教程
下面的教程将从数据准备开始,说明如何训练SMOKE模型
数据准备
目前Paddle3D中提供的SMOKE模型支持在KITTI数据集上训练,因此需要先准备KITTI数据集,请在官网进行下载:
-
left color images of object data set (12 GB)
-
training labels of object data set (5 MB)
-
camera calibration matrices of object data set (16 MB)
并下载数据集的划分文件列表:
wget https://bj.bcebos.com/paddle3d/datasets/KITTI/ImageSets.tar.gz
将数据解压后按照下方的目录结构进行组织
$ tree KITTI
KITTI
├── ImageSets
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
└── training
├── calib
├── image_2
└── label_2
在Paddle3D的目录下创建软链接 datasets/KITTI,指向到上面的数据集目录
训练
使用如下命令启动4卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3
# 每隔50步打印一次训练进度
# 每隔5000步保存一次模型,模型参数将被保存在output目录下
fleetrun tools/train.py --config configs/smoke/smoke_dla34_no_dcn_kitti.yml --num_workers 2 --log_interval 50 --save_interval 5000
评估
使用如下命令启动评估
export CUDA_VISIBLE_DEVICES=0
# 使用Paddle3D提供的预训练模型进行评估
python tools/evaluate.py --config configs/smoke/smoke_dla34_no_dcn_kitti.yml --num_workers 2 --model output/iter_70000/model.pdparams
导出部署
使用如下命令导出训练完成的模型
# 导出Paddle3D提供的预训练模型
python tools/export.py --config configs/smoke/smoke_dla34_no_dcn_kitti.yml --model output/iter_70000/model.pdparams
执行预测
命令参数说明如下:
| 参数 | 说明 |
|---|---|
| model_file | 导出模型的结构文件smoke.pdmodel所在路径 |
| params_file | 导出模型的参数文件smoke.pdiparams所在路径 |
| image | 待预测的图片路径 |
| use_gpu | 是否使用GPU进行预测,默认为False |
| use_trt | 是否使用TensorRT进行加速,默认为False |
| trt_precision | 当use_trt设置为1时,模型精度可设置0/1/2,0表示fp32,1表示int8,2表示fp16。默认0 |
| collect_dynamic_shape_info | 是否收集模型动态shape信息。默认为False。只需首次运行,下次运行时直接加载生成的shape信息文件即可进行TensorRT加速推理 |
| dynamic_shape_file | 保存收集到的模型动态shape信息的文件路径。默认为dynamic_shape_info.txt |
Python部署
进入代码目录 deploy/smoke/python,运行以下命令,执行预测:
-
执行CPU预测
python infer.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image -
执行GPU预测
python infer.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image --use_gpu -
执行CPU预测并显示3d框
python vis.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image -
执行GPU预测并显示3d框
python vis.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image --use_gpu -
执行TRT预测
注意:需要下载支持TRT版本的paddlepaddle以及nvidia对应版本的TensorRT库
-
首次运行TensorRT,收集模型动态shape信息,并保存至
--dynamic_shape_file指定的文件中python infer.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image --collect_shape_info --dynamic_shape_file /path/to/shape_info.txt -
加载
--dynamic_shape_file指定的模型动态shape信息,使用FP32精度进行预测python infer.py --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image --use_trt --dynamic_shape_file /path/to/shape_info.txt
-
C++部署
编译步骤
- step 1: 进入部署代码所在路径
cd deploy/smoke/cpp
- step 2: 下载Paddle Inference C++预编译库
Paddle Inference针对是否使用GPU、是否支持TensorRT、以及不同的CUDA/cuDNN/GCC版本均提供已经编译好的库文件,请至Paddle Inference C++预编译库下载列表选择符合的版本。
-
step 3: 下载OpenCV
-
step 4: 修改
compile.sh中的编译参数
主要修改编译脚本compile.sh中的以下参数:
| 参数 | 说明 |
|---|---|
| WITH_GPU | 是否使用gpu。ON或OFF, OFF表示使用CPU,默认ON |
| USE_TENSORRT | 是否使用TensorRT加速。ON或OFF,默认OFF |
| LIB_DIR | Paddle Inference C++预编译包所在路径,该路径下的内容应有:CMakeCache.txt、paddle、third_party和version.txt |
| CUDNN_LIB | cuDNNlibcudnn.so所在路径 |
| CUDA_LIB | CUDAlibcudart.so 所在路径 |
| TENSORRT_ROOT | TensorRT所在路径。非必须,如果USE_TENSORRT设置为ON时,需要填写该路径,该路径下的内容应有bin、lib和include等 |
- step 5: 开始编译
sh compile.sh
- step 6: 执行预测
./build/infer --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image
注意:如果要使用TRT预测,请根据编译步骤的step 3,修改compile.sh中TensorRT相关的编译参数,并重新编译。
该路径,该路径下的内容应有bin、lib和include等 |
- step 5: 开始编译
sh compile.sh
- step 6: 执行预测
./build/infer --model_file /path/to/smoke.pdmodel --params_file /path/to/smoke.pdiparams --image /path/to/image
注意:如果要使用TRT预测,请根据编译步骤的step 3,修改compile.sh中TensorRT相关的编译参数,并重新编译。















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









