







Enhancing Transferable Adversarial Attacks On Vision Transformers Through Gradient Normalization Scaling And Highfrequency Adaptation

本文 “Enhancing Transferable Adversarial Attacks On Vision Transformers Through Gradient Normalization Scaling And Highfrequency Adaptation” 提出 Gradient Normalization Scaling 和 High-Frequency Adaptation(GNS-HFA)方法,通过对温和梯度进行归一化缩放以及探索高频区域来增强对抗样本对 ViTs 的可转移性。在多种 ViT 和 CNN 模型上的实验表明,该方法优于现有方法。
摘要-Abstract
Vision Transformers (ViTs) have been widely used in various domains. Similar to Convolutional Neural Networks (CNNs), ViTs are prone to the impacts of adversarial samples, raising security concerns in real-world applications. As one of the most effective black-box attack methods, transferable attacks can generate adversarial samples on surrogate models to directly attack the target model without accessing the parameters. However, due to the distinct internal structures of ViTs and CNNs, adversarial samples constructed by traditional transferable attack methods may not be applicable to ViTs. Therefore, it is imperative to propose more effective transferability attack methods to unveil latent vulnerabilities in ViTs. Existing methods have found that applying gradient regularization to extreme gradients across different functional regions in the transformer structure can enhance sample transferability. However, in practice, substantial gradient disparities exist even within the same functional region across different layers. Furthermore, we find that mild gradients therein are the main culprits behind reduced transferability. In this paper, we introduce a novel Gradient Normalization Scaling method for fine-grained gradient editing to enhance the transferability of adversarial attacks on ViTs. More importantly, we highlight that ViTs, unlike traditional CNNs, exhibit distinct attention regions in the frequency domain. Leveraging this insight, we delve into exploring the frequency domain to further enhance the algorithm’s transferability. Through extensive experimentation on various ViT variants and traditional CNN models, we substantiate that the new approach achieves state-of-the-art performance, with an average performance improvement of 33.54% and 42.05% on ViT and CNN models, respectively.
视觉Transformer(ViTs)已在各个领域得到广泛应用。与卷积神经网络(CNNs)类似,ViTs容易受到对抗样本的影响,这在实际应用中引发了安全问题。作为最有效的黑盒攻击方法之一,可迁移性攻击可以在代理模型上生成对抗样本,无需访问参数即可直接攻击目标模型。然而,由于 ViTs 和 CNNs 的内部结构不同,传统可迁移攻击方法构建的对抗样本可能不适用于 ViTs。因此,提出更有效的可迁移性攻击方法以揭示 ViTs 中的潜在漏洞至关重要。现有方法发现,在 Transformer 结构的不同功能区域对极端梯度应用梯度正则化可以提高样本的可迁移性。然而,在实践中,即使在不同层的同一功能区域内也存在很大的梯度差异。此外,我们发现其中的温和梯度是可迁移性降低的主要原因。在本文中,我们引入了一种新颖的梯度归一化缩放方法,用于细粒度梯度编辑,以提高对 ViTs 的对抗攻击的可迁移性。更重要的是,我们强调 ViTs 与传统 CNN 不同,在频域中表现出不同的注意力区域。利用这一见解,我们深入探索频域以进一步提高算法的可迁移性。通过对各种 ViT 变体和传统 CNN 模型进行广泛的实验,我们证实了新方法实现了最先进的性能,在 ViT 和 CNN 模型上分别平均提高了 33.54%和 42.05%的性能。
引言-Introduction
该部分主要阐述了研究的背景和动机,强调了视觉Transformer(ViTs)的安全问题以及当前可转移对抗攻击方法的局限性,引出了本文的研究重点,具体内容如下:
- ViTs的广泛应用与安全隐患:ViTs在图像分类、语义分割和跨模态任务等领域取得显著进展,但容易受到对抗样本的影响,导致错误预测。目前针对对抗攻击的研究主要集中在卷积神经网络(CNNs)上,应用于ViTs时效果不佳。考虑到对抗攻击在模型鲁棒性评估和防御开发中的重要性,有必要为ViT模型制定有效的对抗攻击方法,以检测其在安全关键应用中的漏洞。
- 对抗攻击的分类与可迁移攻击的重要性:对抗攻击分为白盒攻击和黑盒攻击。白盒攻击中攻击者可获取目标模型的架构或梯度信息,而黑盒攻击中攻击者只能依赖模型的输入和输出构建对抗样本。可迁移对抗攻击作为一种有效的黑盒攻击方法,能在本地代理模型上生成对抗样本并直接用于攻击目标模型。鉴于基于ViT的应用多为黑盒性质,本文重点研究针对ViT模型的黑盒攻击,尤其是可迁移对抗攻击。
- 可迁移攻击应用于ViTs面临的挑战:一方面,由于ViTs和传统CNNs的固有结构差异,针对CNNs的攻击方法(如基于频谱显著性图的攻击(SSA)和基于神经元归因的攻击(NAA))在ViTs上效果较差。另一方面,当前针对ViTs的可迁移攻击方法主要通过微调梯度和在 Transformer 结构的不同功能区域应用梯度正则化来提高样本可迁移性,但存在问题。同一功能区域内不同通道的梯度对样本可迁移性的影响存在差异,而现有方法通常针对整个功能区域进行处理,导致可转移性有限。例如,Token Gradient Regularization方法(TGR)通过正则化同一层内的极端梯度来增强可迁移性,Pay No Attention方法(PNA)通过丢弃同一层内的一定数量梯度来优化对抗样本,但这些操作可能导致信息丢失,使算法更容易受到数据扰动或噪声的影响,进而影响攻击的鲁棒性。
- 本文的解决方案与贡献:为解决上述挑战,本文提出了一种新颖的梯度归一化缩放(GNS)方法,用于对梯度进行细粒度编辑。在反向传播过程中对温和梯度进行缩放,以防止在对抗样本训练过程中出现过拟合。同时,受SSA的启发,观察到ViTs对高频特征有显著关注,因此提出高频适应(HFA)方法,通过构建掩码来探索ViTs在不同频率区域对对抗攻击的敏感性,优化梯度更新方向。通过在各种ViT变体和CNN模型上进行实验,验证了GNS - HFA方法的有效性,与现有方法相比,该方法在ViT和CNN模型上的平均性能分别提高了33.54%和42.05%。本文的主要贡献包括:发现温和梯度对样本可迁移性的显著影响,并通过准确归一化和缩放缓解过拟合;提出高频适应方法,稳定梯度更新方向;提出GNS-HFA方法,增强对抗样本对ViTs的可迁移性;通过大量实验展示了该方法在多种模型上的优越性。
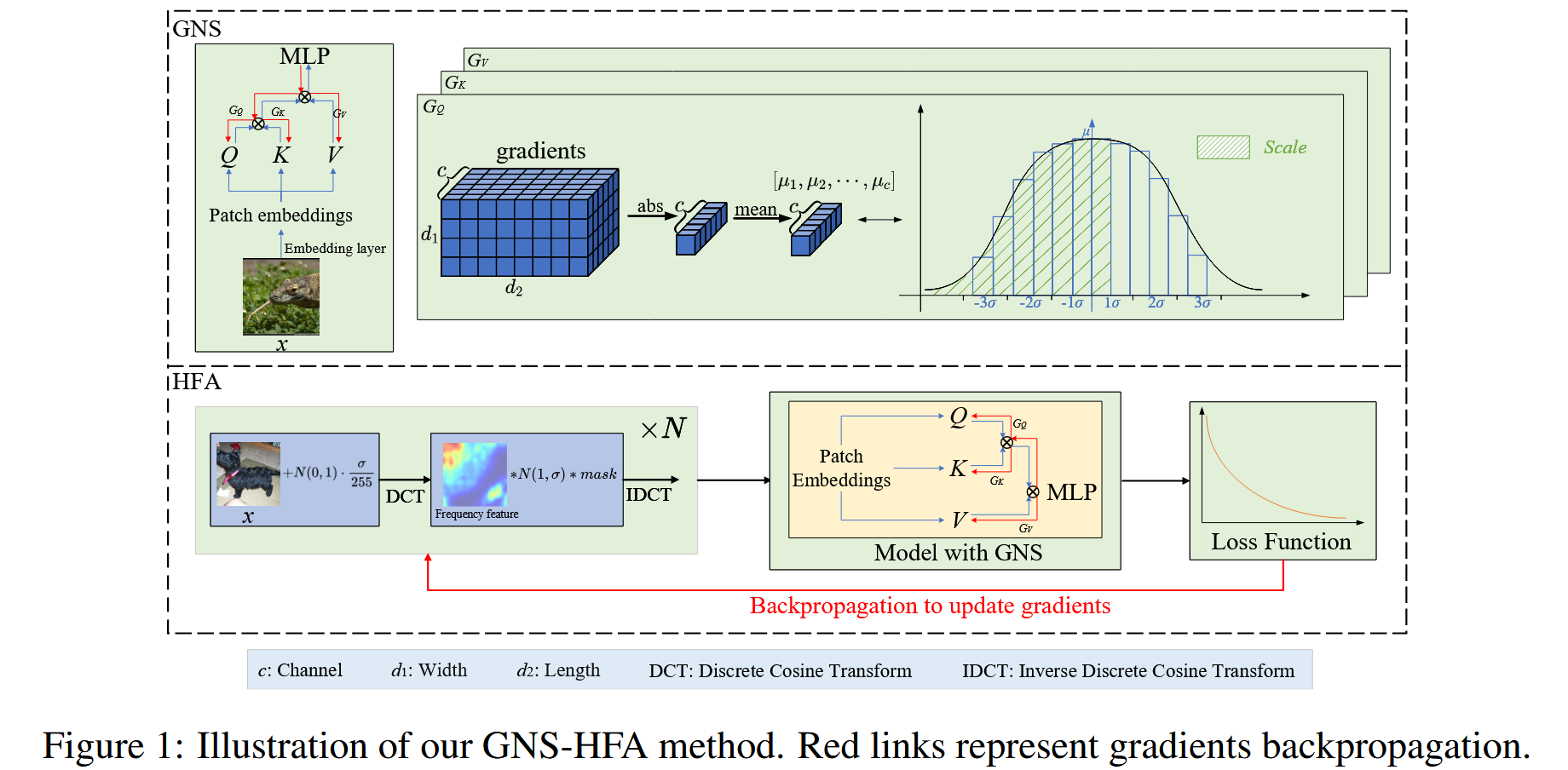
图1:我们的GNS-HFA方法示意图。红色线条表示梯度反向传播。
相关工作-Related Work
该部分主要介绍了与本文研究相关的两方面工作,即视觉Transformer(ViT)和可迁移黑盒对抗攻击,具体内容如下:
- 视觉Transformer(ViT):ViT是一种基于自注意力机制的深度神经网络架构,最初用于自然语言处理,现已广泛应用于计算机视觉领域。与传统的卷积神经网络(CNNs)和循环神经网络(RNNs)相比,ViT具有更高的表示能力和更少的视觉特定偏差,在视觉基准测试中表现相似或更优,这促使众多ViT模型的提出。文中列举了多种ViT模型:
- ViT-B/16:专为图像分类设计,将图像以固定大小的块作为顺序输入进行处理。
- PiT-B:采用池化操作增强能力,通过减少空间维度、增加通道维度来改进信息处理。
- CaiT-S/24:加深Transformer结构并引入分类标签,以提升图像分类性能。
- Visformer - S:将Transformer转变为基于卷积的模型,结合了两者的优势。
- DeiT-B:另一种用于图像分类的Transformer模型,能有效处理图像数据,提高性能。
- TNT-S:利用“十字形窗口自注意力”高效分析图像不同部分,可快速处理大规模图像并保持高性能。
- LeViT-256:一种轻量级ViT,具有较高的分类准确率和较低的计算成本,适用于资源受限的环境。
- ConViT-B:结合卷积和Transformer的优势进行图像分类,采用混合模型结构提升性能。
- 可转移黑盒对抗攻击:当前可迁移黑盒对抗攻击主要分为三类:
- 特征级攻击方法:包括基于神经元归因的攻击(NAA)、特征重要性感知攻击(FIA)和特征破坏攻击(FDA)等。这类方法旨在准确估计中间层神经元的重要性,以进行可迁移攻击。
- 输入变换方法:通过对输入图像样本进行变换来增强其可迁移性。例如,多样输入方法(DIM)引入多个随机生成的梯度方向,沿不同方向扰动样本以增加对抗样本的多样性;平移不变方法(TIM)引入平移不变性,在不同位置和尺度生成具有相似扰动的对抗样本;频谱显著性攻击(SSA)探索梯度在频域对深度神经网络(DNNs)的影响,以制作更具可迁移性的样本,解决仅在空间域进行模型增强的局限性。
- 梯度方法:通过采用梯度更新技术来增强样本可迁移性。例如,动量迭代方法(MIM)在迭代扰动更新中引入动量以稳定梯度更新方向;尺度不变和Nesterov迭代方法(SINIFGSM)利用Nesterov加速梯度技术更新扰动,并结合尺度不变攻击方法,有效针对不同尺度的图像;TGR和PNA分别通过对同一层的梯度进行缩放或去除,来评估对抗样本在ViT模型上的可迁移性,但这两种方法在准确定位和正则化梯度方面存在不足,可能导致反向传播过程中的过拟合。
预备知识-Preliminaries
该部分主要介绍了可迁移攻击的问题定义以及ViT中的多头自注意力机制,为后续理解本文提出的方法和实验奠定基础,具体内容如下:
- 可转移攻击的问题定义:在对抗攻击中,给定源模型 f θ f_{\theta} fθ、初始样本 x x x 和目标类 y y y,目标是找到一个扰动 η ∗ \eta^{*} η∗,使得目标函数 L ( f θ ( x + η ) , y ) L(f_{\theta}(x + \eta), y) L(fθ(x+η),y) 最大化,同时满足约束 ∥ η ∥ p ≤ ϵ \|\eta\|_{p} \leq \epsilon ∥η∥p≤ϵ。通过对扰动 η \eta η 使用 L p L_{p} Lp 范数进行约束,以防止对抗操作导致明显的视觉失真, ϵ \epsilon ϵ 为预定义的最大扰动大小上界,此时攻击目标可表示为优化问题 η ∗ = a r g m a x η L ( f θ ( x + η ) , y ) s . t . ∥ η ∥ p ≤ ϵ \eta^{*}=\underset{\eta}{arg max } L\left(f_{\theta}(x+\eta), y\right) \ \ s.t. \| \eta\| _{p} \leq \epsilon η∗=ηargmaxL(fθ(x+η),y) s.t.∥η∥p≤ϵ. 在可迁移攻击场景下,当通过上述优化问题确定扰动率 η ∗ \eta^{*} η∗ 后,目标是将在 f θ f_{\theta} fθ 上生成的扰动引入到其他黑盒模型中,放大其损失函数。这里的 f θ i f_{\theta_{i}} fθi( i = 1 , 2 , ⋯ , n i = 1,2,\cdots,n i=1,2,⋯,n)代表不同的黑盒模型,与源模型 f θ f_{\theta} fθ 结构不同,通过在代理模型 f θ f_{\theta} fθ 上生成对抗样本,实现对其他黑盒模型的有效攻击,增强对抗攻击在所有黑盒模型间的可转移性。
- ViT中的多头自注意力机制(MSA):在ViT模型中,MSA机制使模型能在不同的表示空间中同时关注序列的不同部分,从而提升性能。其主要步骤包括:
- 初始投影:将输入序列映射到多个子空间,每个子空间都有各自的权重矩阵,通常表示为 Q Q Q(查询)、 K K K(键)和 V V V(值)。
- 注意力计算:在每个子空间中进行自注意力计算,即计算查询和键之间的相似性分数,并将这些分数作为权重对值向量进行加权平均,得到每个子空间的注意力输出。
- 多头组合:将多个子空间的注意力输出进行组合,常见方式是沿着特定维度进行连接或相加。
- 最终投影:将合并后的注意力输出再次通过投影层进行投影,得到最终的多头自注意力输出。
方法-Method
该部分主要介绍了为提升对抗样本对视觉Transformer(ViTs)可迁移性而提出的两种方法——梯度归一化缩放(GNS)和高频适应(HFA),具体内容如下:
-
梯度归一化缩放(GNS)
- 梯度细粒度编辑的可行性:对于CNN模型,代理模型和目标模型的特征具有相似性,可据此生成可迁移样本。但针对ViT模型的可迁移攻击常出现过拟合现象,即攻击在代理模型上成功率高,在目标模型上却很低。Token Gradient Regularization(TGR)方法认为这种现象是由反向传播中的极端梯度导致的,去除极端梯度可增强样本可迁移性。然而,本文研究发现,极端梯度并非导致样本可迁移性降低的主要原因,相对较小的温和梯度才是关键。由于ViTs采用自注意力机制,对输入的细微扰动敏感,温和梯度更新步长小,会使模型对训练数据的微小变化过度敏感,易引发过拟合,影响对抗样本质量。对于更深的ViT模型,温和梯度还可能导致梯度消失问题,影响对抗样本训练。
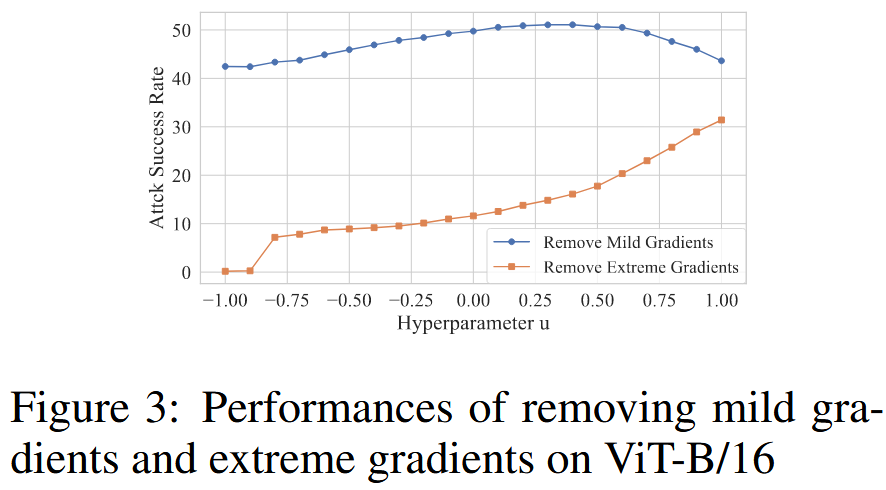
图3:在ViT-B/16模型上去除温和梯度和极端梯度的性能表现 - 温和梯度的精确缩放:ViTs处理特征的主要机制是多头自注意力(MSA)结构。本文对MSA结构中关键参数
W
Q
W^{Q}
WQ、
W
K
W^{K}
WK 和
W
V
W^{V}
WV 产生的梯度信息进行细粒度编辑。因为梯度信息与参数维度相同,将梯度分解为
G
=
{
g
1
,
g
2
,
⋯
,
g
C
}
G = \{g_{1}, g_{2}, \cdots, g_{C}\}
G={g1,g2,⋯,gC},其中
C
C
C 表示通道数。为确定需要缩放的梯度,先计算每个通道梯度的绝对值均值
g
a
b
s
_
m
e
a
n
=
[
μ
1
,
μ
2
,
⋯
,
μ
c
]
=
[
m
e
a
n
(
a
b
s
(
g
1
)
)
,
m
e
a
n
(
a
b
s
(
g
2
)
)
,
⋯
,
m
e
a
n
(
a
b
s
(
g
C
)
)
]
g_{abs\_mean} = [\mu_{1}, \mu_{2}, \cdots, \mu_{c}] = [mean(abs(g_{1})), mean(abs(g_{2})), \cdots, mean(abs(g_{C}))]
gabs_mean=[μ1,μ2,⋯,μc]=[mean(abs(g1)),mean(abs(g2)),⋯,mean(abs(gC))]. 然后,定义梯度绝对值均值小于
μ
+
u
∗
σ
\mu + u * \sigma
μ+u∗σ 的为温和梯度,其中
μ
\mu
μ 是所有通道梯度绝对值均值的平均值,
σ
\sigma
σ 是标准差,
u
u
u 是超参数,可调整温和梯度的范围。实验证明
u
=
2
u = 2
u=2 在多数情况下效果良好,无需调整超参数。为区分选定通道中哪些梯度需要缩放,计算温和梯度与平均梯度的偏差
a
b
s
(
g
l
−
μ
σ
)
abs(\frac{g_{l}-\mu}{\sigma})
abs(σgl−μ),并使用双曲正切函数对温和梯度进行缩放,即
g
l
=
g
l
∗
t
a
n
h
(
a
b
s
(
g
l
−
μ
σ
)
)
g_{l}=g_{l} * tanh(abs(\frac{g_{l}-\mu}{\sigma}))
gl=gl∗tanh(abs(σgl−μ)),这样能自适应地缩放梯度,保留具有攻击能力的较大梯度。算法1展示了GNS方法的具体过程。

- 梯度细粒度编辑的可行性:对于CNN模型,代理模型和目标模型的特征具有相似性,可据此生成可迁移样本。但针对ViT模型的可迁移攻击常出现过拟合现象,即攻击在代理模型上成功率高,在目标模型上却很低。Token Gradient Regularization(TGR)方法认为这种现象是由反向传播中的极端梯度导致的,去除极端梯度可增强样本可迁移性。然而,本文研究发现,极端梯度并非导致样本可迁移性降低的主要原因,相对较小的温和梯度才是关键。由于ViTs采用自注意力机制,对输入的细微扰动敏感,温和梯度更新步长小,会使模型对训练数据的微小变化过度敏感,易引发过拟合,影响对抗样本质量。对于更深的ViT模型,温和梯度还可能导致梯度消失问题,影响对抗样本训练。
-
高频适应(HFA)
- 通过掩码探索高频特征:受Spectrum Saliency Attack(SSA)启发,为进一步提升对抗样本对ViTs的可迁移性,采用频率探索优化ViTs中的梯度更新方向。通过归因可视化发现,与传统CNN模型相比,ViTs更关注高频特征,因此需在高频区域进行针对性探索。构建掩码
m
a
s
k
i
j
k
=
(
W
+
i
2
)
⋅
(
H
+
j
2
)
W
×
H
mask_{ij}^{k}=\frac{(\frac{W + i}{2}) \cdot (\frac{H + j}{2})}{W \times H}
maskijk=W×H(2W+i)⋅(2H+j)(
k
=
0
,
1
,
2
k = 0,1,2
k=0,1,2,
m
a
s
k
∈
R
W
×
H
×
3
mask \in R^{W \times H \times 3}
mask∈RW×H×3)来区分不同频率区域的图像特征,其中
W
W
W 和
H
H
H 分别表示图像的宽度和高度。
在图像的频率表示中,左上角附近的特征代表低频特征,右下角附近的特征代表高频特征。通过与相应噪声相乘得到频域特征表达式 x f = I D C T ( D C T ( x + N ( 0 , 1 ) ⋅ ϵ 255 ) ∗ N ( 1 , σ ) ∗ m a s k ) x_{f}=IDCT(DCT(x + N(0,1) \cdot \frac{\epsilon}{255}) * N(1, \sigma) * mask) xf=IDCT(DCT(x+N(0,1)⋅255ϵ)∗N(1,σ)∗mask),其中 D C T DCT DCT 是离散余弦变换, I D C T IDCT IDCT 是逆离散余弦变换, ϵ \epsilon ϵ 是扰动幅度。若原始模型高频信息有限,需添加并归一化额外噪声 N ( 0 , 1 ) ⋅ ϵ 255 N(0,1) \cdot \frac{\epsilon}{255} N(0,1)⋅255ϵ 来引入基本高频信息。

图2:不同模型在频域中的归因可视化(Pan等人,2021年) - 可迁移攻击方向适应:利用GNS训练的模型计算
∂
L
(
x
f
,
y
)
∂
x
f
\frac{\partial L(x_{f}, y)}{\partial x_{f}}
∂xf∂L(xf,y),多个频率特征可生成更具可迁移性的梯度更新方向。随机选择
N
N
N 个反向传播频率梯度,用其平均值更新当前迭代的对抗样本,即
x
t
+
1
=
x
t
+
η
⋅
s
i
g
n
(
1
N
∑
i
=
1
N
P
i
)
x^{t + 1}=x^{t}+\eta \cdot sign(\frac{1}{N} \sum_{i = 1}^{N} P_{i})
xt+1=xt+η⋅sign(N1∑i=1NPi),其中
P
i
P_{i}
Pi 是GNS训练模型相对于频率特征
x
f
x_{f}
xf 的梯度,
y
y
y 是原始标签,
η
\eta
η 是学习率,
s
i
g
n
(
⋅
)
sign(\cdot)
sign(⋅) 用于确定梯度更新方向。HFA利用获取的高频信息调整对抗样本的更新过程,使生成的对抗样本更符合ViTs结构,能更稳定地跨越目标模型的决策边界。算法2展示了HFA方法的具体过程。

- 通过掩码探索高频特征:受Spectrum Saliency Attack(SSA)启发,为进一步提升对抗样本对ViTs的可迁移性,采用频率探索优化ViTs中的梯度更新方向。通过归因可视化发现,与传统CNN模型相比,ViTs更关注高频特征,因此需在高频区域进行针对性探索。构建掩码
m
a
s
k
i
j
k
=
(
W
+
i
2
)
⋅
(
H
+
j
2
)
W
×
H
mask_{ij}^{k}=\frac{(\frac{W + i}{2}) \cdot (\frac{H + j}{2})}{W \times H}
maskijk=W×H(2W+i)⋅(2H+j)(
k
=
0
,
1
,
2
k = 0,1,2
k=0,1,2,
m
a
s
k
∈
R
W
×
H
×
3
mask \in R^{W \times H \times 3}
mask∈RW×H×3)来区分不同频率区域的图像特征,其中
W
W
W 和
H
H
H 分别表示图像的宽度和高度。
实验-Experiments
该部分通过一系列实验验证了GNS-HFA方法的有效性,主要包括实验设置、实验结果和消融研究三个方面,具体内容如下:
-
实验设置
- 基线方法:选取9种方法作为竞争基线,其中TGR和PNA是专门针对ViT模型改进的可迁移对抗攻击方法,其余7种(SSA、BIM、PGD、DI-FGSM、TIFGSM、MI-FGSM和SINI-FGSM )是针对CNN模型优化的方法,TGR作为主要竞争基线与本文方法对比。
- 数据集:采用与主要竞争基线TGR以及当前CNN模型上表现最佳的可迁移攻击方法SSA完全一致的数据集,即从ILSVRC 2012验证集中随机选取的1000张图像。
- 模型:选择大量模型与TGR保持完全一致,包括8种ViT模型(LeViT-256、PiT-B、DeiT-B、ViT-B/16、TNT-S、ConViT-B、Visformer-S和CaiT-S/24 )和7种CNN模型(Inception-v3、Inception-v4、InceptionResNet-v2、ResNet-101以及通过集成训练增强对抗鲁棒性的3种模型:Inc-v3-adv-3、Inc-v3-adv-4和IncRes-v2-adv )。其中,ViT-B/16、Visformer-S、PiT-B和CaiT-S/24用作代理模型训练可转移样本。
- 评估指标:选择攻击成功率(ASR)作为评估不同攻击方法的指标,ASR计算数据集中被对抗攻击方法成功误导模型进行错误分类的样本比例,ASR值越高表明方法的攻击能力越强。
- 参数设置:将允许偏差水平 u u u 设置为1,探索的频率样本数 N N N 设置为20,迭代次数 T T T 设置为10,扰动幅度 ϵ \epsilon ϵ 设置为16,并将扰动幅度归一化处理为 ϵ / 255 \epsilon / 255 ϵ/255.
-
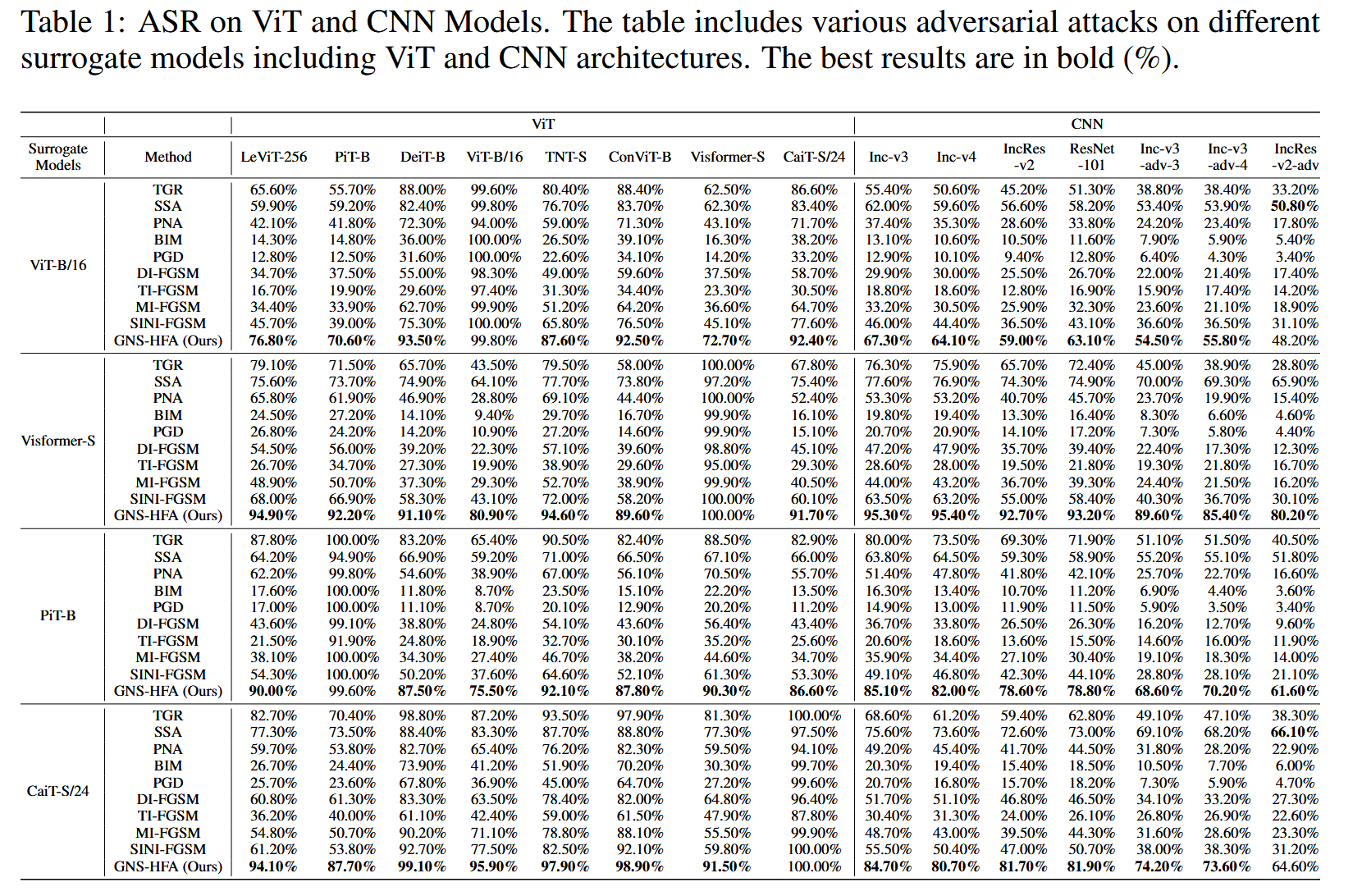
实验结果:本文的GNS-HFA方法在ViT和CNN模型上均优于现有方法。与所有竞争基线相比,整体性能提升37.80%;在ViT模型上平均提升33.54%,在CNN模型上平均提升42.05%。与主要竞争模型TGR相比,平均提升15.04%,其中在ViT模型上提升9.72%,在CNN模型上提升20.35%。与CNNs上表现最佳的可转移攻击方法SSA相比,平均提升12.32%,在ViT模型上提升13.94%,在CNN模型上提升10.71%。
表1:ViT和CNN模型的攻击成功率(ASR)。该表包含了对不同代理模型(包括ViT和CNN架构)的各种对抗攻击结果。最佳结果以粗体显示(%)。
-
消融研究
-
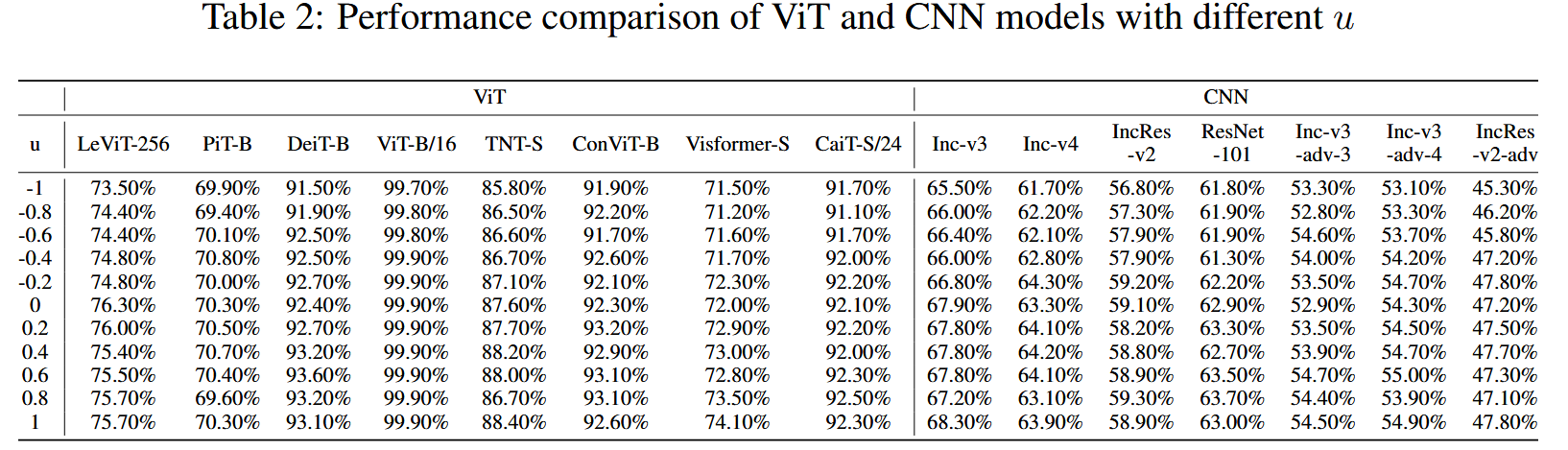
参数 u u u 对GNS-HFA的影响:固定 N = 20 N = 20 N=20 和 ϵ = 16 \epsilon = 16 ϵ=16,将参数 u u u 在 -1到1之间以0.2的增量系统变化。结果表明,随着 u u u 接近1,GNS-HFA性能最优,但整体影响相对较小。同时发现,无论 u u u 取何值,去除温和梯度的攻击成功率始终高于去除极端梯度,说明去除温和梯度可缓解局部代理ViT模型训练对抗样本时的过拟合问题,提高对抗样本的可转移性。
-
参数 N N N 对GNS-HFA的影响:设置 u = 1 u = 1 u=1 和 ϵ = 16 \epsilon = 16 ϵ=16,将 N N N 分别设置为5、10、15和20。结果显示,随着 N N N 的增加,GNS-HFA的性能持续提升,当 N = 20 N = 20 N=20 时达到最佳性能。
表3:不同 N N N 值下视觉Transformer(ViT)和卷积神经网络(CNN)模型的性能对比
-
参数 ϵ \epsilon ϵ 对GNS-HFA的影响:设置 u = 1 u = 1 u=1 和 N = 20 N = 20 N=20,将 ϵ \epsilon ϵ 分别设置为8、16、24和32。结果表明,随着 ϵ \epsilon ϵ 的增加,GNS-HFA的性能显著提升,在ViT模型上,当 ϵ = 32 \epsilon = 32 ϵ=32 时ASR超过90%,但此时图像扰动明显。而当 ϵ = 16 \epsilon = 16 ϵ=16 时,扰动相对不明显且仍能实现较为有效的对抗攻击,因此可根据实际需求选择合适的 ϵ \epsilon ϵ 值以平衡攻击效果和图像扰动程度。
表4:不同 ϵ ϵ ϵ 值下ViT和CNN模型的性能对比


图4:不同 ϵ ϵ ϵ 值下的对抗攻击样本
-
结论-Conclusion
该部分总结了研究成果、强调了方法优势,并对未来研究提供了方向,具体如下:
- 现有可转移攻击的问题:现有针对视觉Transformer(ViTs)的可迁移攻击存在挑战,在反向传播过程中,难以精准定位和正则化梯度,容易导致过拟合,影响攻击效果。
- GNS-HFA方法的优势:提出的梯度归一化缩放和高频适应(GNS-HFA)方法,能对梯度进行细粒度编辑,调整可迁移攻击方向。在多种ViT和传统CNN模型上进行的大量实验表明,该方法显著提升了对抗样本对ViTs的可迁移性,性能优于现有方法。
- 研究展望:该研究成果为后续相关研究提供了思路。论文公开了复现研究的代码包,期望能推动该领域的进一步探索和发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











