






作者官方的介绍文章:
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式,本文主要是我个人对这篇文章的学习。
自 ViT 时代到来之后,由一叠 blocks 堆起来构成的基础模型已经成为了广泛遵循的基础模型设计范式,一个神经网络的宏观架构由width宽度(channel 数)和 depth 深度(block 数)来决定。有没有想过,一个神经网络未必是一叠 blocks 组成的?可能是 2 叠,4 叠,或者…16 叠?
ViT介绍,熟悉的可以跳过
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
Vision Transformer详解
Vision Transformer详解-CSDN博客
ViT 模型的整个流程:
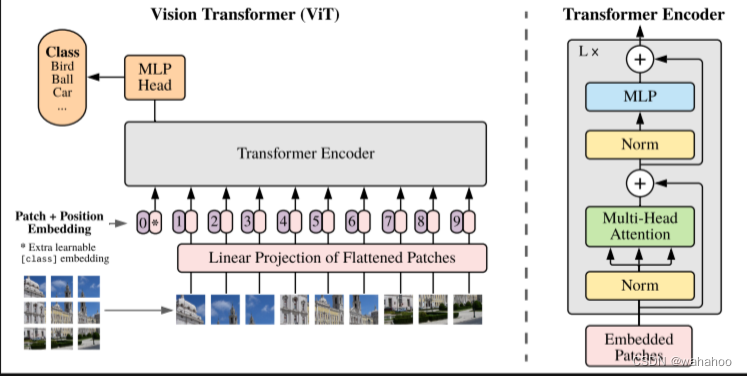
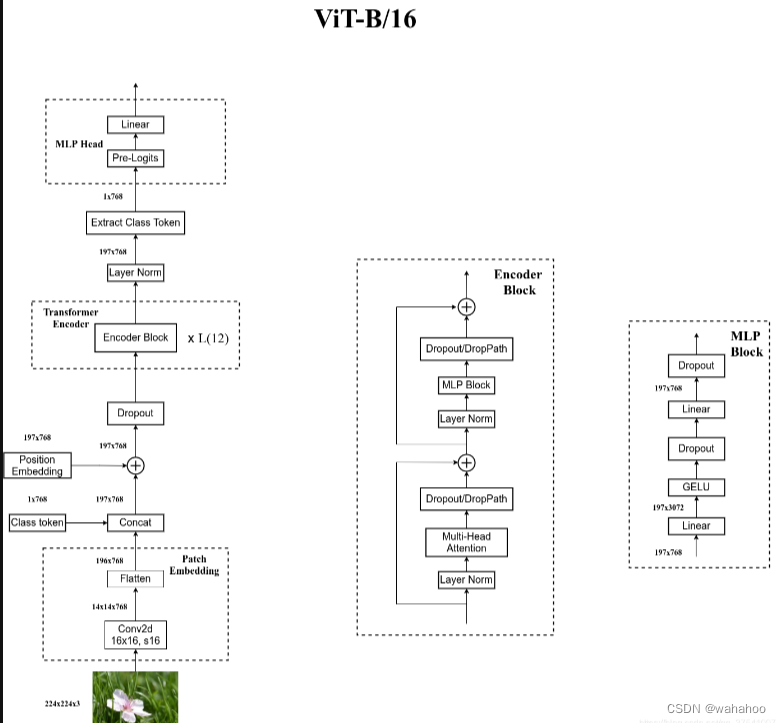
1、Patch Embedding: 将输入图像划分为固定大小的图像块(patch),每个 patch 被视为一个 token,并通过线性投射层映射为固定维度的向量。这创建了一个输入序列,其中包含图像中的所有 patch 和一个特殊字符 "cls"(表示类别(classification))。
例如输入图片大小为224x224,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为
196
,每个patch维度16x16x3=
768
的向量(后面都直接称为token)
,
直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。
embeding层(线性投射层)的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。
这里还需要加上一个特殊字符cls,
这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,
因此最终的维度是
197x768
。
2、Positional Encoding: 添加位置编码以捕捉序列中 token 的相对位置信息,使用可学习的 1D 位置嵌入。位置编码和输入序列相加。
3、Transformer Encoder: 通过多头自注意力机制,每个注意力头分别映射为 q、k、v,并将它们组合。这一过程在每个头中独立进行,然后将所有头的输出连接在一起。接着应用 Layer Normalization。
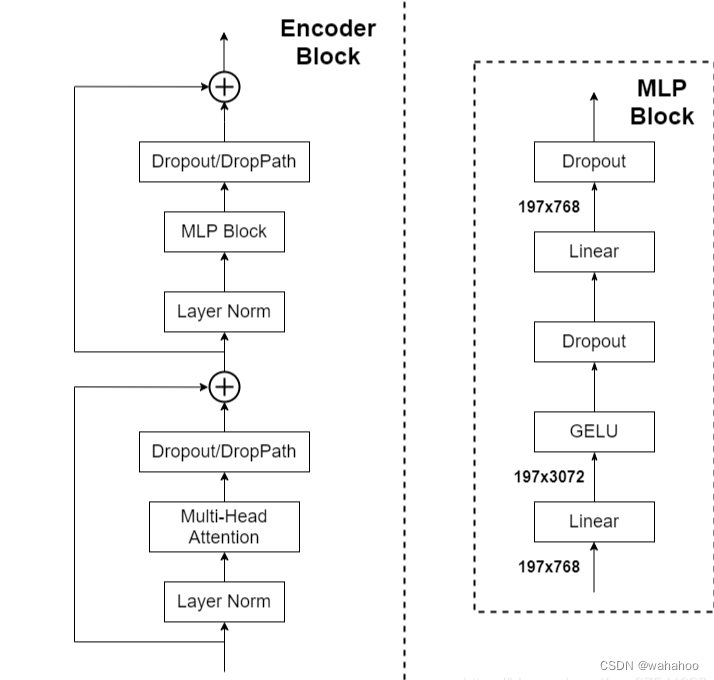
-
Layer Norm(层归一化): Layer Norm 是一种归一化方法,用于规范输入数据。在 Transformer 中,它被应用于每个 token 的向量,确保每个维度的数值都接近标准正态分布。这有助于提高训练的稳定性。
-
Multi-Head Attention(多头自注意力): Multi-Head Attention 是 Transformer 中的关键组件,它允许模型在不同表示空间的不同位置分别关注输入序列的不同部分。通过将自注意力机制应用多次(多个头),模型能够捕捉输入序列中不同位置的关系。这有助于处理长距离依赖关系。
-
Dropout/DropPath: Dropout 是一种正则化技术,用于在训练过程中随机丢弃一些神经元,防止过拟合。DropPath 是一种类似的方法,但是对整个层进行随机丢弃。这有助于训练更深层次的网络。这些方法可以用于减轻过拟合风险。
-
MLP Block(多层感知机块): MLP Block 由两个全连接层和 GELU激活函数组成。第一个全连接层将输入节点的数量翻了4倍,然后应用 GELU 激活函数和 Dropout。第二个全连接层将节点数量还原回原始值。这个结构有助于引入非线性变换,提高模型的表示能力。
4、MLP Head: 通过全连接的多层感知机,将维度放大再缩小回来,引入非线性变换。最后再次应用 Layer Normalization。
一、背景
1. 单纯的分类网络(如ResNet)作为backbone使用效果不佳,因为在训练过程中过滤掉了很多低层级特征(比如纹理、边缘等),这些特征对下游任务很重要。
2. 而HRNet、FPN等多尺度特征融合结构效果好,因为保留了不同尺度的特征,包括低层级特征,对下游任务有帮助。但如果只考虑分类任务,这些结构的效果反而不如ResNet。
3. 信息瓶颈(Information Bottleneck)解释了这一现象。分类网络在训练中主要保留对分类有帮助的语义特征,而过滤掉无关的低层级特征。这对下游任务是不利的。
4. 理想的backbone应该能够分离(disentangle)语义特征和低层级特征,并同时保留两者,这就需要一种新的结构设计。
5. RevCol采用了多分支的设计,每个分支(column)保留不同级别的特征。通过可逆连接实现特征的无损传递。同时使用中间监督迫使每个分支学习语义特征。这样实现了特征的解耦和保留。
-
常规的直连网络,浅层特征包含更多低层信息,深层特征则更加语义化。信息在网络中的传递会逐步丢失低层信息。
-
RevCol采用多分支输入的设计,每个分支(column)的起始位置连接低层特征,这样不同分支都保存了输入的低层信息。
-
通过分支的迭代传递,每个分支末端的特征被逐步提取出更多的语义信息。
-
分支之间采用可逆连接,可以互相反向推断,实现信息的无损传递。
-
加入中间监督,迫使每个分支学习提取语义信息。
-
通过这种结构设计,成功实现了低层特征和语义特征的解耦,同时保证信息在网络中不受损失地传递,这是本文的关键创新。
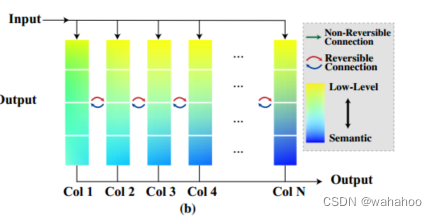
黄色表示低级信息,蓝色表示语义信息。
二、方法
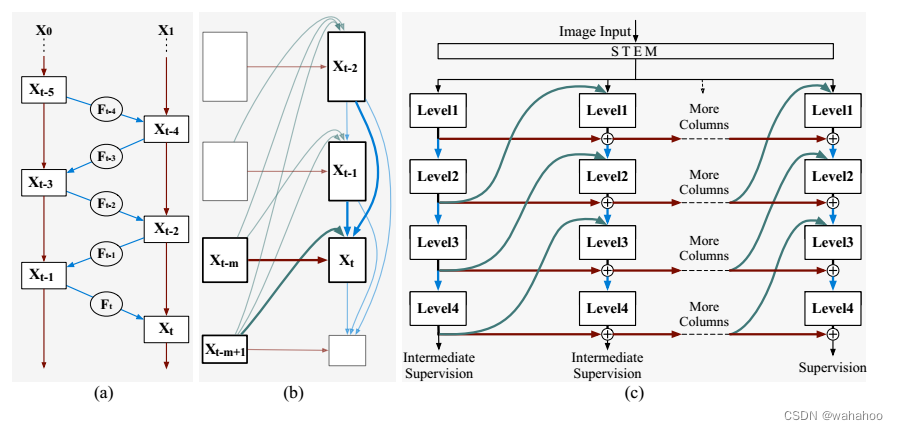
图2:(a) RevNet中的可逆单元(Gomez等,2017)。(b)多级可逆装置。级别t的所有输入都突出显示。(c)简化多级可逆单元的整个可逆柱网体系结构概述。
先解释RevNet的原理:RevNet的代表性著作(Gomez et al, 2017)。如图 (a) 所示,RevNet 首先将输入 x 分为两组,x0 和 x1。然后对于后面的块,例如块 t,它采用两个前块的输出 xt−1 和 xt−2 作为输入并生成输出 xt。块 t 的映射是可逆的,即 xt−2 可以由两个后验块 xt−1 和 xt 重建。从形式上讲,正向和逆向计算遵循以下方程†:
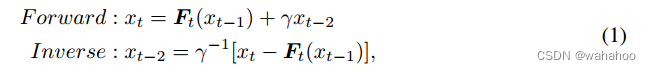
RevNet 的前传和
反推的公式,其中xi
表示当前的 block,xi-1
表示上一个block,xi-2
表示上上一个。当前 block 的输入由两个部分构成,第一部分来源于上一个block 的输出
xi-1
,过一个 N
on-linear Function F(·)(可以是 Conv/BN/Relu/Residual Block)。第二部分是上两个 block 的输出
xi-2
经过一个
可逆操作
,比如
全通道缩放
。然后这两个部分加和。这样的约束保证了在倒推的时候
可以通过重新把更先前一步已推得的
重新输入 Ft(·)中计算出结果,然后把 forward 的式子反过来。加变减,乘变除,反推出来。
基本结构:
首先通过补丁嵌入模块将输入图像分割成不重叠的小块。
之后,补丁被馈送到每个子网(列)。列可以用任何传统的单列架构实现,如ViT、ConvNeXt。
从每一列中提取四层特征映射,在列之间传播信息。
对于分类任务,我们只使用最后一列中最后一层(level 4)的feature map来获语义信息。对于目标检测和语义分割,使用最后一列中所有四个级别的特征映射,因为它们既包含低级信息,也包含语义信息
具体简化的公式为:
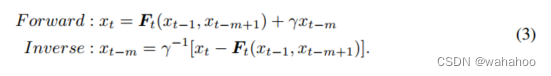
优势:
1、
Feature disentangling
每个列的低级别维护低级特征(保留细节信息例如纹理、边缘等,低级特征在不同列之间传播时是可逆的,不会引起信息损失。)
高级别增强高级特征(高级特征通常包含更抽象、语义上更高级的信息;例如物体的形状、类别等,支持下游任务目标检测,语义分割等)
而在其它一些方法中,使用特征金字塔结构来实现提取多尺度、多层次特征, 特征金字塔通常将低级特征(在网络较早的层次中)与高级特征(在网络较深的层次中)进行融合。
2、
Memory saving.
由于梯度计算的需要,传统网络的训练需要占用大量内存来存储前向传播过程中的激活。而在我们的RevCol中,由于列之间的连接是显式可逆的,因此在反向传播期间,我们可以动态地从最后一列到第一列重建所需的激活,这意味着我们只需要在训练期间在内存中维护来自一列的激活。
在传统的神经网络中,反向传播过程中,需要保存前向传播期间的激活值,以便计算梯度。具体而言,激活值是神经网络中每一层的输出,而这些输出将用于计算损失函数对相应层权重的梯度。梯度计算涉及到对激活值的导数,而这些导数是通过链式法则从最终损失函数反向传播到网络的每一层得到的。
RevCol模型提到的优势在于它的连接是显式可逆的,在反向传播过程中,可以从最后一列到第一列重新构建所需的激活值,这样可以节省显存,特别是在训练大型网络时,减轻了对内存的要求。
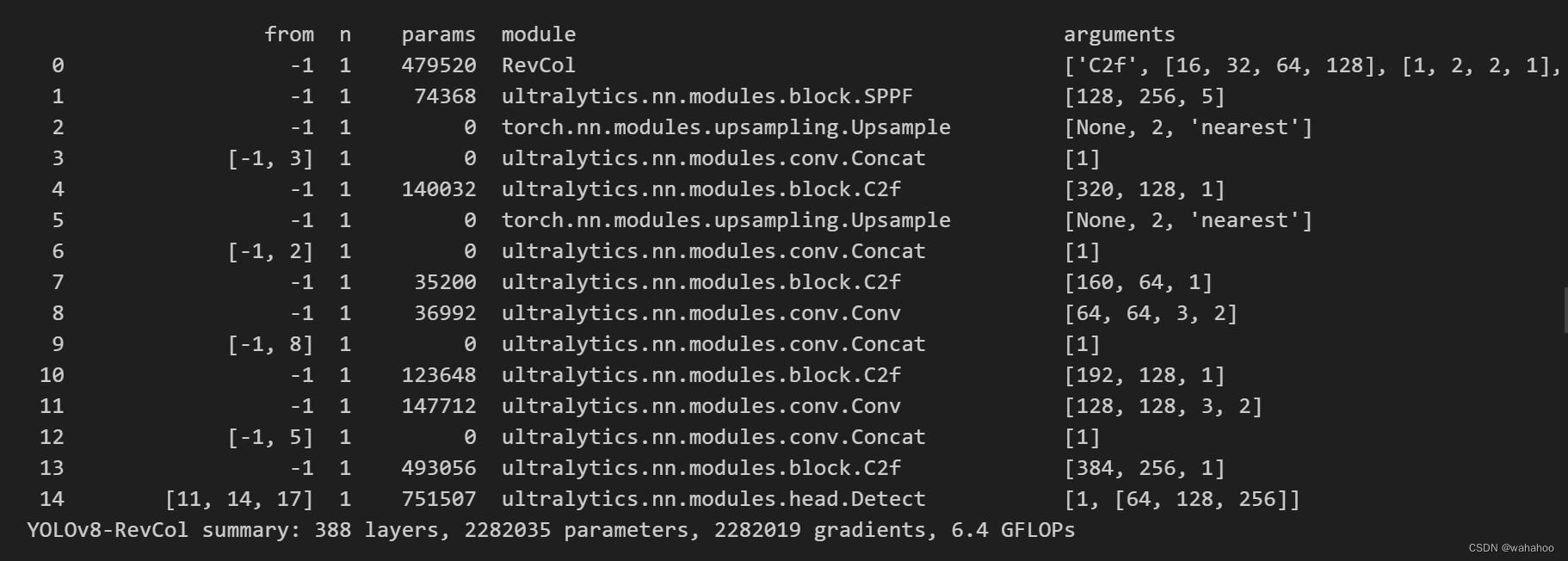
理论上是节省了内存,但增加了计算量,但我在yolov8中使用RevCol代替原来的主干网络,发现层数增加了,参数量和计算量还减少了20%多。

3、
New scaling factor for big models
在RevCol架构中,除了深度(块的数量)(层数)
和宽度(每个块的通道)(通道数)
之外,列数作为一个新的维度在普通的单列cnn或vit中。在一定范围内,增加列数与增加宽度和深度的收益相似。
在RevCol中,引入了列数这一新的维度,这使得网络的结构更加丰富。在传统网络中,常常只考虑了深度和宽度这两个维度,而RevCol通过增加列数,引入了对网络结构更细粒度的控制。且增加列数有类似于增加宽度和深度的效果。
微观结构
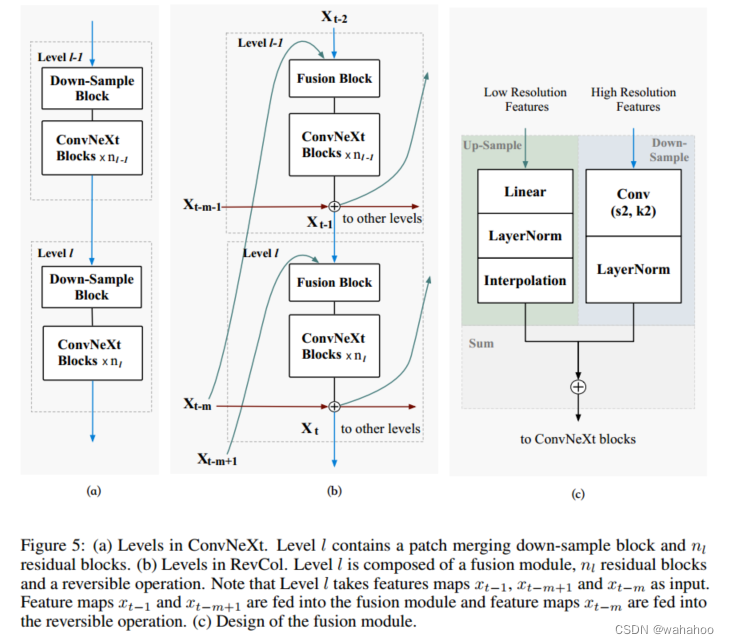
RevCol的架构设计细节。RevCol包含多个具有可逆连接的列。
图5 (a) 显示了ConvNeXt的架构。将ConvNeXt中的7×7深度卷积替换为3×3。
在图5 (b) 中,展示了如何在ConvNeXt的基础上扩展到RevCol。首先,将下采样块替换为融合块,以融合当前列中的低级表示和前一列中的高级表示。
图5 (c) 显示了融合块的详细信息,其中包含上采样和下采样操作,以处理不同分辨率。其次,对于每个层次,来自前一列的相同层次表示被添加到当前层次的输出中,并准备整体传播。由于这两个修改,来自不同层次的特征图汇聚在一起形成中间表示。使用Linear-LayerNorm后跟最近邻插值来上采样低分辨率特征。使用步幅2的2×2核Conv2d下采样高分辨率特征,然后进行LayerNorm以平衡两个输入的贡献。
实验结果
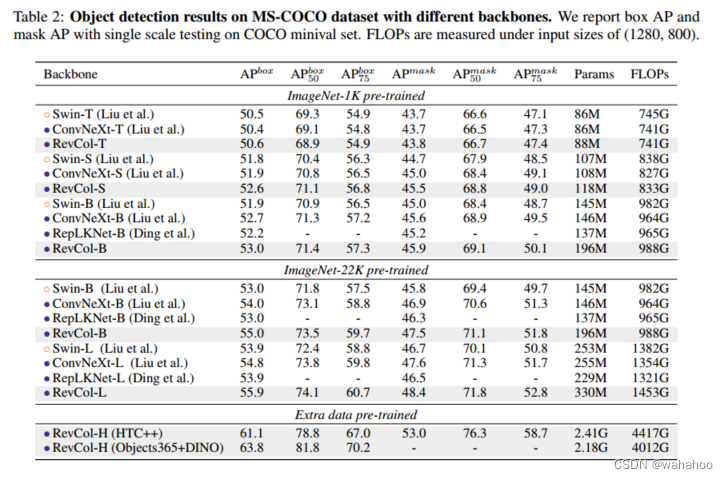
在表2中,作者将APbox和APmask与Swin/ConvNeXt在COCO验证集上的不同大小进行了比较。发现RevCol模型超越了其他具有类似计算复杂性的模型。
保留在预训练中的信息有助于RevCol模型在下游任务中获得更好的结果。当模型尺寸增大时,这种优势变得更加显著。在Objects365数据集和DINO框架下进行微调后,最大的模型revcoll-h在COCO检测最小集上实现了63.8%的APbox。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









