







一、yolov8n.yaml文件学习
backbone:
# [from, repeats, module, args]
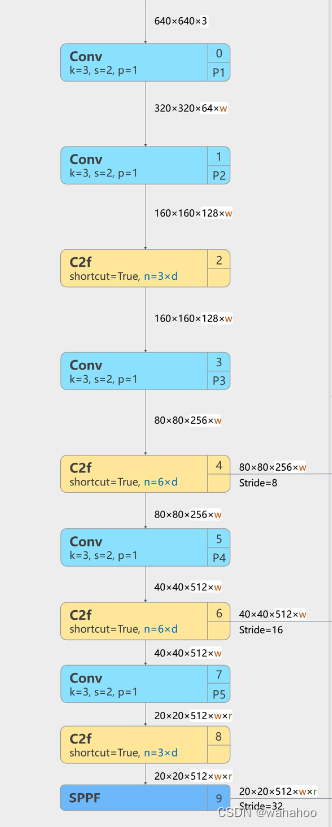
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层:使用64个3x3的卷积核,步幅为2进行卷积,得到P1/2特征图(原来的一半)。
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 1/4的特征图
- [-1, 3, C2f, [128, True]] #第2层:进行3次C2f操作,每次操作使用128个通道,最后一次操作使用降维(TrU).(比如v8n模型,3 * 0.33=1只重复一次)
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]] #第4层:进行6次C2f操作,每次操作使用256个通道,最后一次操作使用降维(True).
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9 使用1024个通道的SPPE(空间金字塔池化)层,使用5个不同大小的池化核进行池化操作
from
-n代表是从前n层获得的输入,
-1表示从前一层获得输入
repeats
表示网络模块的数目
Module
表示网络模块的名称
args
表示向不同模块内传递的参数
[ch out,kernel,stride,padding,groups]
这里没有chin输入通道.
原因:输入都是上层的输出
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #第0层:使用最近邻上采样(nn.Upsample)将特征图尺寸放大两倍。
- [[-1, 6], 1, Concat, [1]] # cat backbone P4 #第1层:将backbone提取的P4特征图与当前特征图进行拼接(Concat),生成新的特征图
- [-1, 3, C2f, [512]] # 12 第2层:进行3次C2f操作,使用512个通道,得到第12个特征图。
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #第3层:使用最近邻上采样将特征由尺寸放大两倍。
- [[-1, 4], 1, Concat, [1]] # cat backbone P3 #第4层:将backbone提取的P3特征图与当前特征图进行拼接,生成新的特征图。
- [-1, 3, C2f, [256]] # 15 (P3/8-small) #第5层:进行3次C2f操作,使用256个通道,得到第15个特征图(P3/8-sma11)。
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4 第7层:将head生成的特征图与backbone提取的P4特征图进行拼接
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
二、一些术语
1、backbone:主干网络,用来提取特征,常用VGG
2、head:获取网络输出,利用提取特征做出预测
3、neck:放在backbone和head之间,进一步提升特征的多样性及鲁棒性
4、bottleneck:瓶颈,通常指网络输入输出数据维度不同,通常输出维度比输入维度小很多
5、GAP:Global Average Pool全局平均池化,将某个通道的特征取平均值
6、Warm up:小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定
FPN(Feature Pyramid Network):FPN(特征金字塔网络):
* FPN是一种自顶向下的特征金字塔结构,通过在网络中不同层次的特征图上建立金字塔,从而获得多尺度的语义信息。
* 自顶向下指的是从高层(小尺寸、卷积次数多、语义信息丰富)传递特征向下,将高层的强语义特征传递到低层的特征图,使得 低层也能包含更丰富的语义信息。
* FPN主要关注增强语义信息,但在这个过程中,并没有传递低层的强定位信息。
PAN(Path Aggregation Network):PAN(路径聚合网络):
* PAN被设计用来解决FPN在语义信息增强的同时忽略了定位信息的问题。
* 在FPN后面添加了一个自底向上的特征金字塔,通过这个金字塔,强调了低层特征的定位信息,将这些信息传递到高层。
* PAN的双塔战术指的是同时使用了自顶向下和自底向上的两个金字塔,以综合考虑不同层次的语义信息和定位信息,从而更全面地捕捉目标的特征。
正常的YOLOv8对象检测模型输出层是P3、P4、P5三个输出层,为了提升对小目标的检测能力,新版本的YOLOv8 已经包含了P2层(P2层做的卷积次数少,特征图的尺寸(分辨率)较大,更加利于小目标识别),有四个输出层。Backbone部分的结果没有改变,但是Neck跟Header部分模型结构做了调整。这就是为什么v8模型yaml文件里面
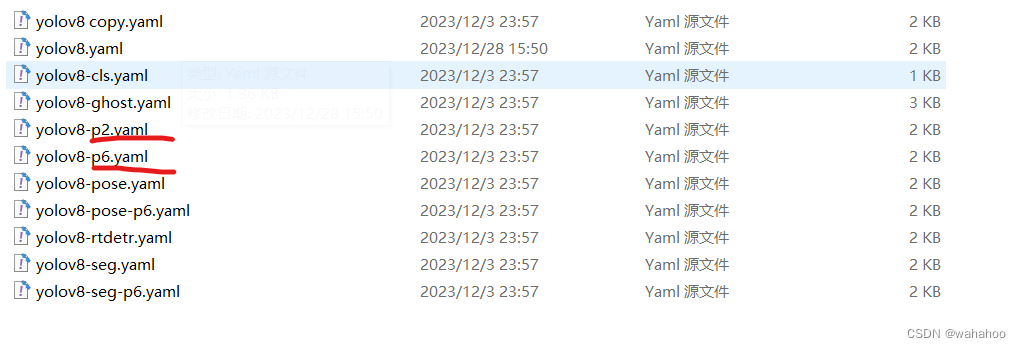
model=yolov8n.ymal 使用正常版本
model=yolov8n-p2.ymal 小目标检测版本
model=yolov8n-p6.ymal 高分辨率版本
三、 backbone
1、cnv卷积块
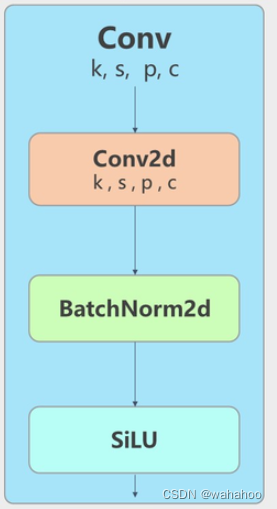
三部分组成(1)一个二维卷积+(2)二维BatchNorm+(3)SiLU激活函数
2、
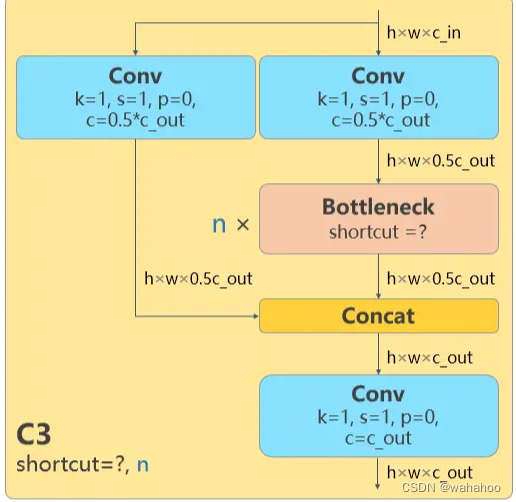
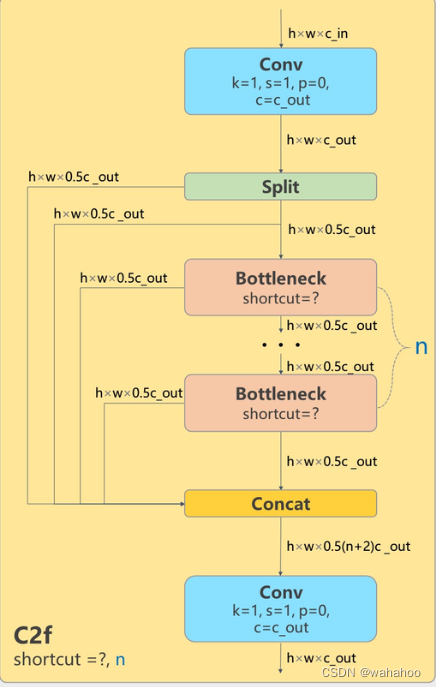
C2f
模块
这个模块是一个具有两个卷积层的 CSP(Cross Stage Partial)Bottleneck。
cross-scale convolutional feature fusion
"跨尺度卷积特征融合"
CSP Bottleneck 是一种用于改进深度神经网络性能的结构。
CSP讲解可以看:
轻量级网络论文-CSPNet 详解 - 知乎
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
其主要思想是在残差块中加入跨
阶段
的连接。
标准Bottleneck结构通常包含3个卷积层,按1x1、3x3、1x1的格式排列,中间有ReLU激活函数。这种结构可以进一步压缩模型并提取更多特征。
CSP Bottleneck结构如下:
-
将输入特征图通道数c1划分为两个部分(如2:1),以此作为两个分支的输入。
-
分别对两个分支应用标准Bottleneck结构进行特征提取,即含有3个卷积层的残差迁移连接。
-
将两个分支的输出特征图concat起来作为残差结构的输出。
而在v8中,使用
split代替
chunk
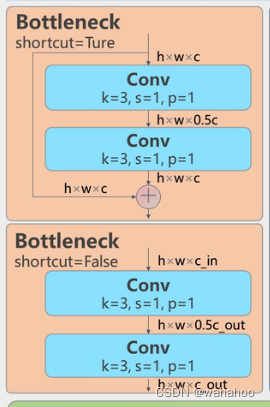
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels int()函数则是对计算结果取整
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
"""1. c1, c2 分别代表Bottleneck块输入和输出的通道数。c_: 是中间层的通道数。
cv1, cv2 是该Bottleneck中的两个卷积层
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
###ultralytics\nn\modules.py
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
-
__init__方法:模块的初始化。接受输入输出通道数c1、c2,中间层数n,shortcut参数等作为输入,计算中间通道数self.c,并根据这些参数创建cv1、cv2卷积层和m模块列表。
-
forward方法:模块的前向传播逻辑。先通过cv1进行卷积和切分,生成两个分支。然后将其中一个分支传入m模块列表,并最终将所有分支在通道维上concat,通过cv2卷积生成输出。
-
forward_split方法:一个forward的VARIANT,使用split代替chunk切分cv1的输出,其余逻辑相同。
-
m模块列表:包含n个Bottleneck模块,每个模块用于特征提取。
chunk()沿着指定维度,将输入tensor划分为多个chunk(块),数量可以不等,但总大小需要与原tensor匹配。
split()沿着指定维度,将输入tensor划分为多个tensor,每份的大小是相等的,数量自动计算。
#假设输入是shape是[h, w, c]
##chunk()的划分机制:
y = x.chunk(3, dim=2)
###结果是c1 + c2 + c3 = c,c1,c2,c3并不相等
y[0].shape = [h, w, c1]
y[1].shape = [h, w, c2]
y[2].shape = [h, w, c3]
##split()的划分机制:
z = x.split([c1, c2], dim=2)#c1, c2可以指定大小,如v8中就是c\2一般是默认平均分配的,但也可以指定
output1.shape = [h, w, c//2]
output2.shape = [h, w, c//2]
torch.split(tensor, split_size_or_sections, dim = 0)
按块大小拆分张量
tensor 为待拆分张量
dim 指定张量拆分的所在维度,即在第几维对张量进行拆分
split_size_or_sections 表示在 dim 维度拆分张量时每一块在该维度的尺寸大小 (int),或各块尺寸大小的列表 (list)
指定每一块的尺寸大小后,如果在该维度无法整除,则最后一块会取余数,尺寸较小一些
如:长度为 10 的张量,按单位长度 3 拆分,则前三块长度为 3,最后一块长度为 1
函数返回:所有拆分后的张量所组成的 tuple
函数并不会改变原 tensor
torch.chunk(input, chunks, dim = 0)
按块数拆分张量
input 为待拆分张量
dim 指定张量拆分的所在维度,即在第几维对张量进行拆分
chunks 表示在 dim 维度拆分张量时最后所分出的总块数 (int),根据该块数进行平均拆分
指定总块数后,如果在该维度无法整除,则每块长度向上取整,最后一块会取余数,尺寸较小一些,若余数恰好为 0,则会只分出 chunks - 1 块
四、SPPF模块
1、SPP (Spatial Pyramid Pooling)、
是何凯明大神在2015年的论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中被提出。
作用:
-
有效 避免了对图像区域的裁剪、缩放操作导致的图像失真等问题。
-
解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本
操作:
1 SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)。
对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍
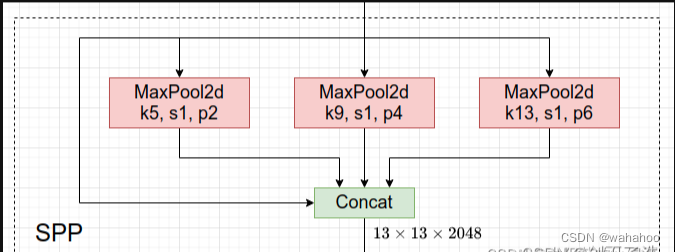
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
2、SPPF
V5的6.0版本后Neck部分将SPP换成成了SPPF(Glenn Jocher自己设计的),两者的作用是一样的,但后者效率更高。SPPF结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
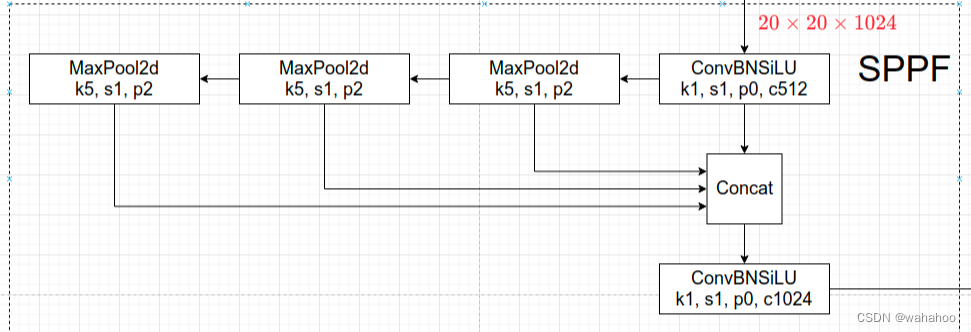
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
3、SimSPPF(美团yolov6)
SimSPPF通过简化SPPF的设计减小了参数量,计算量也更少,同时setFocus在提升小目标的检测效果,这些优化使YOLOv6的检测精度、速度和鲁棒性都有明显的提升。
五、FPN和PAN
1、FPN(
Feature Pyramid Networks for Object Detection
)
如果不讨论传统目标检测算法中的特征提取,深度学习算法流行以来图像金字塔的开端应该是SPPnet。为了解决RCNN中输入图片尺寸必须固定的问题,何凯明大神创新性的提出SPPnet以进行解决。
但FPN作者认为诸如此类算法(SPP、Fast RCNN、Faster RCNN)都是计算的网络的最后一层特征并未考虑多个尺度的特征;又如SDD虽然采用了多尺度融合,但由于没有上采样过程,导致对底层特征的使用不够充分。
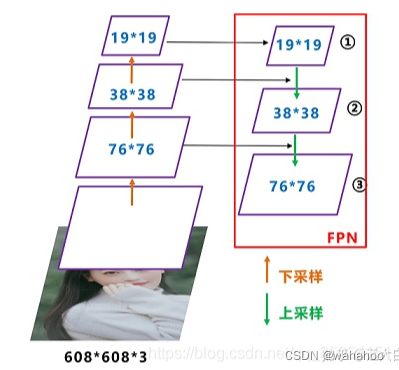
FPN的构建方式是从高分辨率的特征图开始向下采样,同时从低分辨率的特征图开始向上采样,将它们连接起来形成金字塔。在这个过程中,每一层特征图的信息都会与上下相邻层的特征图融合,这样可以使得高层特征图中的目标信息得以保留,同时低层特征图中的背景信息也可以被高层特征图所补充。经过这样的处理,FPN可以提高模型在多尺度检测任务上的精度,同时还可以在不影响检测速度的情况下提高检测 速度 精度。
2、
PAN(
Path Aggregation Network for Instance Segmentation
)
PAN的主要思路是通过聚合来自不同层级的特征图,使得每个特征图中的信息都可以被充分利用,从而提高检测精度。与FPN类似,PAN也是一种金字塔式的特征提取网络,但是它采用的是自下而上的特征传播方式。
PAN的构建方式是从低分辨率的特征图开始向上采样,同时从高分辨率的特征图开始向下采样,将它们连接起来形成一条路径。在这个过程中,每一层特征图的信息都会与上下相邻层的特征图融合,但与FPN不同的是,PAN会将不同层级的特征图融合后的结果进行 加和 级联 ,而不是 级联 加和。这样可以避免在 级联 加和 过程中信息的损失,同时还可以保留更多的细节信息,从而提高检测精度。
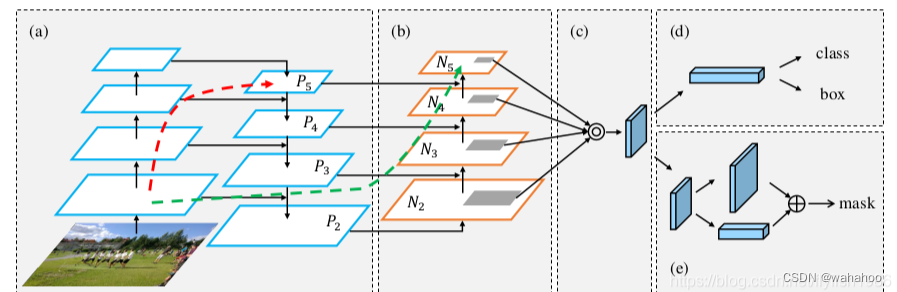
YOLOv8中仅仅在P3、P4、P5三个特征层上构建了FPN和PAN特征金字塔结构,主要有以下几个考虑:
-
计算资源受限。FPN和PAN都会引入额外计算量,作者需要考虑实际部署的速度指标。因此只在最关键的几层特征图上进行多尺度特征融合是一种折中。
-
P3-P5对检测任务影响最大。大量研究表明,在目标检测任务中,P3-P5对代表不同尺度目标的效果最好,因此重点增强这三层特征已能达到很好的效果。
-
高分辨图的语义值有限。YOLOv8中只有P3-P5三层进行下采样,更高分辨率的特征层语义信息有限,因此作者可能认为没必要构建超过三层的金字塔结构。
-
保证实用性。仅在三层特征图上使用FPN和PAN,就足以使YOLOv8在速度和精度上达到最优的平衡,比构建更深的金字塔结构更实用。
3、
YOLOF:You Only Look One-level Feature(CVPR 2021)

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









