







 本文介绍了DETR,一种革新性的目标检测方法,它采用Transformer架构,直接预测目标集合,避免了传统方法中的锚点设计和后处理步骤。文章详细探讨了集合预测的概念,以及DETR与传统锚点和锚点自由方法的区别,包括Q、K、V的来源和处理方式的改变。
本文介绍了DETR,一种革新性的目标检测方法,它采用Transformer架构,直接预测目标集合,避免了传统方法中的锚点设计和后处理步骤。文章详细探讨了集合预测的概念,以及DETR与传统锚点和锚点自由方法的区别,包括Q、K、V的来源和处理方式的改变。
大佬的讲解视频:【DETR | 1、算法概述】 DETR | 1、算法概述_哔哩哔哩_bilibili
Enzo_Mi的个人空间-Enzo_Mi个人主页-哔哩哔哩视频,这个感觉是讲得最详细的

背景
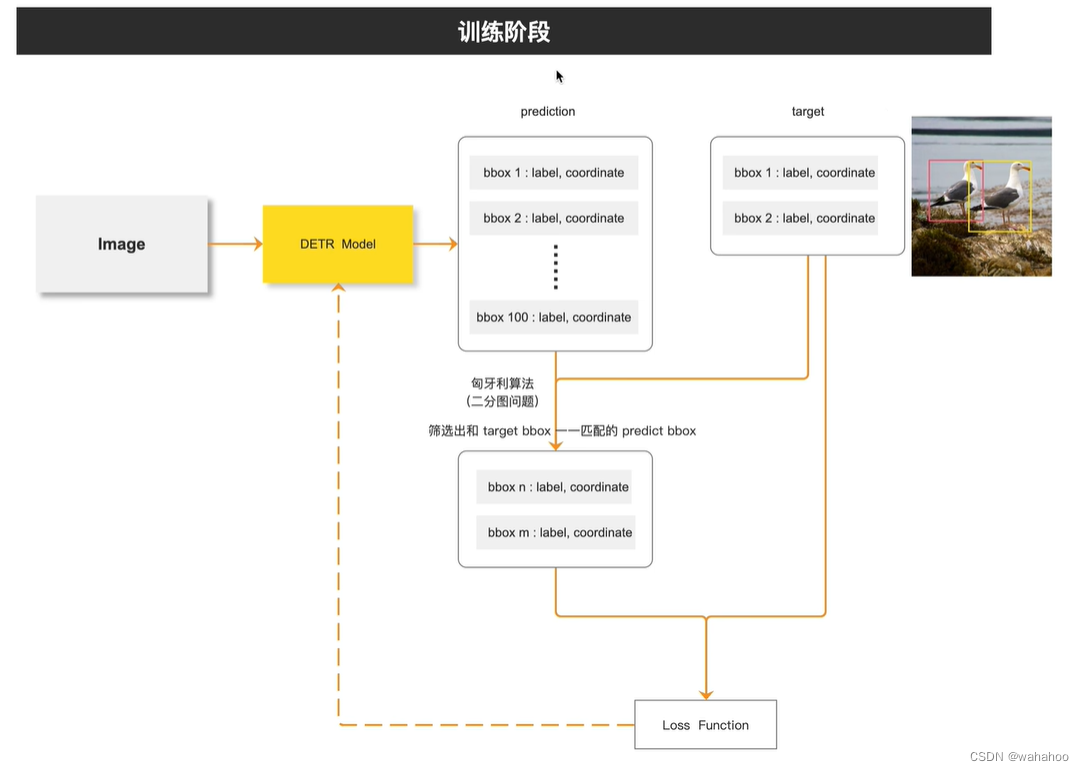
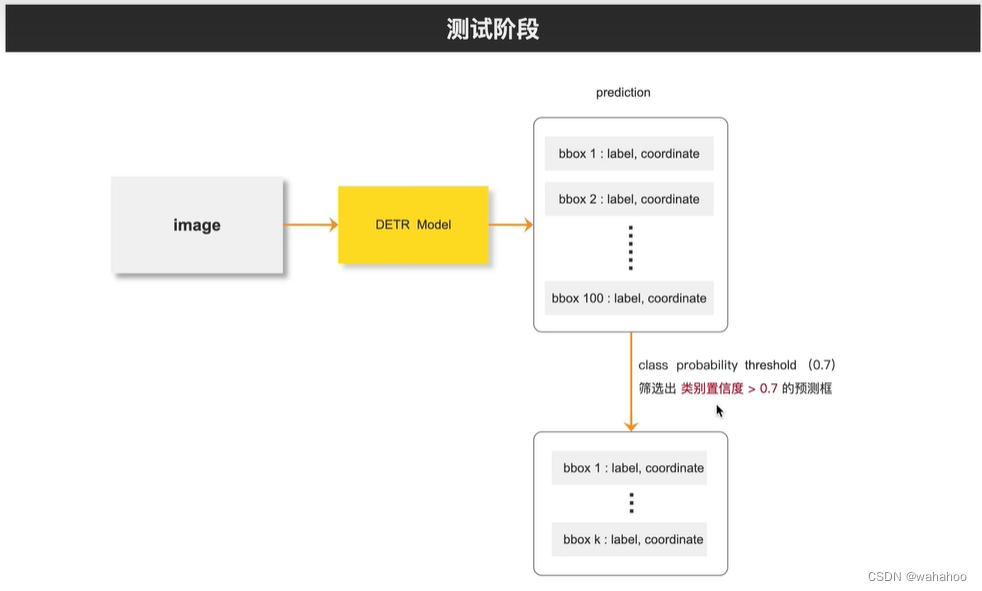
论文提出了一种新的目标检测方法,将目标检测视为一个直接的集合预测问题,而不是传统的间接方式。这种方法的核心是DEtection TRansformer(DETR),它是一个基于Transformer的编码器-解码器架构,通过一个全局损失函数和二分图匹配来强制进行唯一的预测。
目标检测的传统方法通常通过定义代理回归和分类问题来解决集合预测任务,这些方法受到锚点集设计、非极大值抑制(NMS)等后处理步骤的影响。为了简化这些流程,作者提出了一种直接的集合预测方法,即DETR,它通过端到端的方式直接输出最终的预测集合,无需手设计的组件。
什么是集合预测?
直接预测一个目标集合,而不是单独预测集合中的每个元素。在目标检测任务中,集合预测问题可以被理解为直接预测图像中所有感兴趣物体的边界框和类别标签的集合。
在传统的目标检测方法中,集合预测通常是通过间接的方式来实现的,这些方法首先生成大量的候选区域( 锚点(anchors)或提议(proposals)),然后对这些候选区域进行分类和边界框回归。这些方法通常需要额外的后处理步骤(如非极大值抑制,NMS)来消除重复的检测结果。
集合预测方法试图直接从输入数据(图像)中预测出一个不包含重复元素的目标集合。这种方法的优势在于它可以避免复杂的后处理步骤,简化模型的推理过程,并可能提高模型对目标之间关系的理解。
anchor base和anchor free
-
Anchor-based 方法
依赖于预定义的锚点(anchors)或提议(proposals)来生成目标的候选区域。这些锚点是在不同尺度、长宽比和位置上预先定义好的框,它们均匀地分布在图像中。在目标检测过程中,模型会评估这些锚点与实际目标的匹配程度,并调整它们的位置和大小以更好地拟合目标。
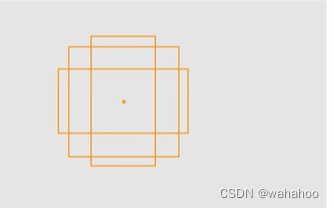
这种方法的代表是Faster R-CNN,它使用区域提议网络(Region Proposal Network, RPN)来生成高质量的锚点,然后通过RoI(Region of Interest)池化层和后续的分类器和边界框回归器来预测目标的类别和精确位置。
-
Anchor-free 方法
不依赖于预定义的锚点。相反,它直接在图像的特征图上预测目标的位置和大小。这意味着模型需要自行学习如何从原始图像特征中推断出目标的存在和它们的确切位置。
Anchor-free方法的一个例子是CornerNet,它使用关键点预测来确定目标的角点,从而推断出目标的边界框。另一个例子是FCOS(Fully Convolutional One-Stage Object Detection),它直接在特征图上预测目标的类别和边界框,而无需任何锚点。
模型结构:
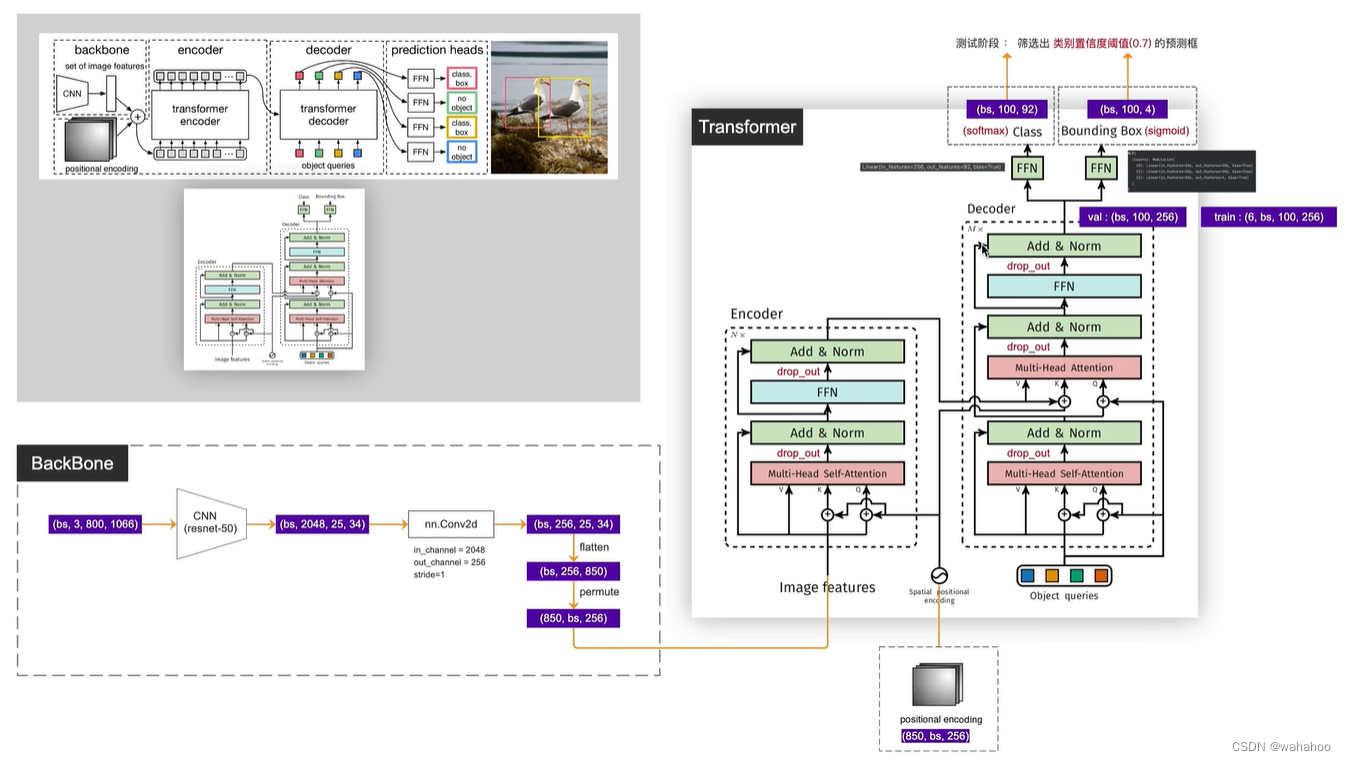
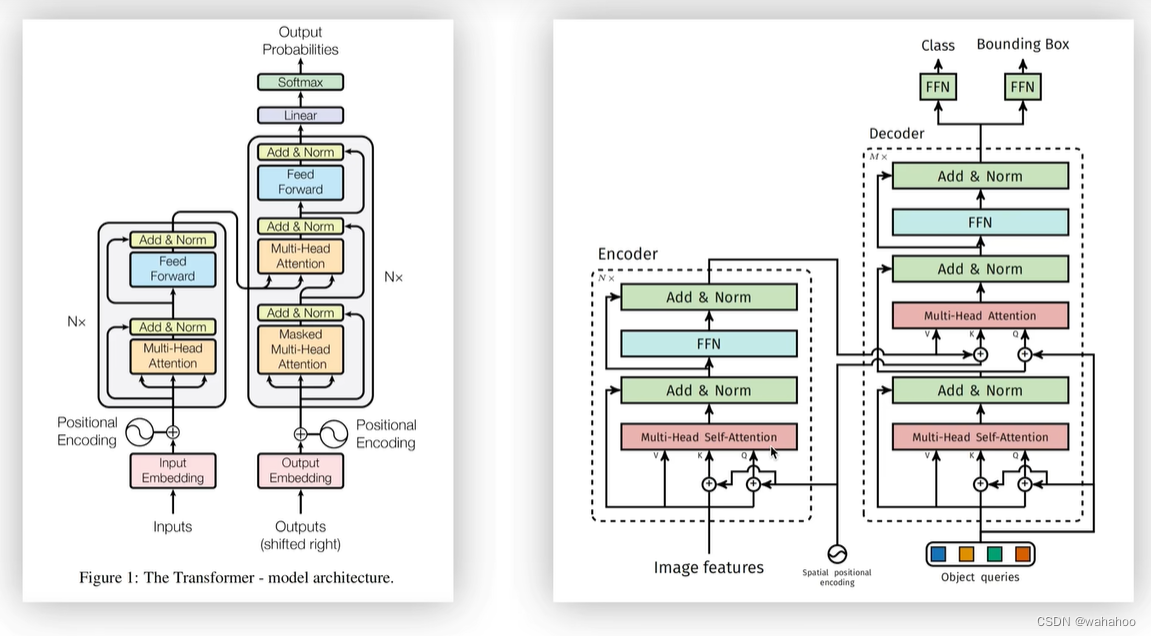 回顾一下Transformer:
回顾一下Transformer:
-
X是输入一句话,权重W,
-
Query是查询向量,代表了当前元素想要从序列中的其他元素中获取的信息。
-
Key是键向量,代表了序列中每个元素的信息。
-
Value是值向量,代表了序列中每个元素的实际内容。一旦Query与Key的匹配程度确定,Value将根据这个匹配程度被加权,以生成最终的输出。
换个说法:
有一个人叫x,他在一系列评判标准W中,计算得到,他的择偶标准是Q,自身条件是K,相亲对象为V,V就是由择偶标准是Q和自身条件是K得到的。
encode
Multi-head attention 通过n个线性变换来计算Q K V.
计算 attention 到Z1.....Zh (h个矩阵)
h个矩阵拼接起来,和Wo相乘. Z1.....Zh拼接 多个子空间结果映射到原空间
Add-Norm 残差输入X add Z, 对向量进行标准化,达到加快收敛的效果
feed forword 两个线性变换,中间有一个激活函数
decode 与encode类似
Mask. 舍去或填充长度. 确保每个位置只能关注到它之前的位置 padding mask: 填充负无穷,softmax 后为0
由于padding的区域是无效的,因此就需要一个额外的mask,其中0表示原图区域,而1对应padding区域,这部分的计算都会被mask掉,相当于告诉网络这些是无用的,不需要计算和回传梯度等。它的作用就是记录训练时的图像哪一部分是有效的,哪一部分是无效的,
注意力 Q来自上一层的 mask attention K,V来自 encoder.
差别:
什么是集合预测
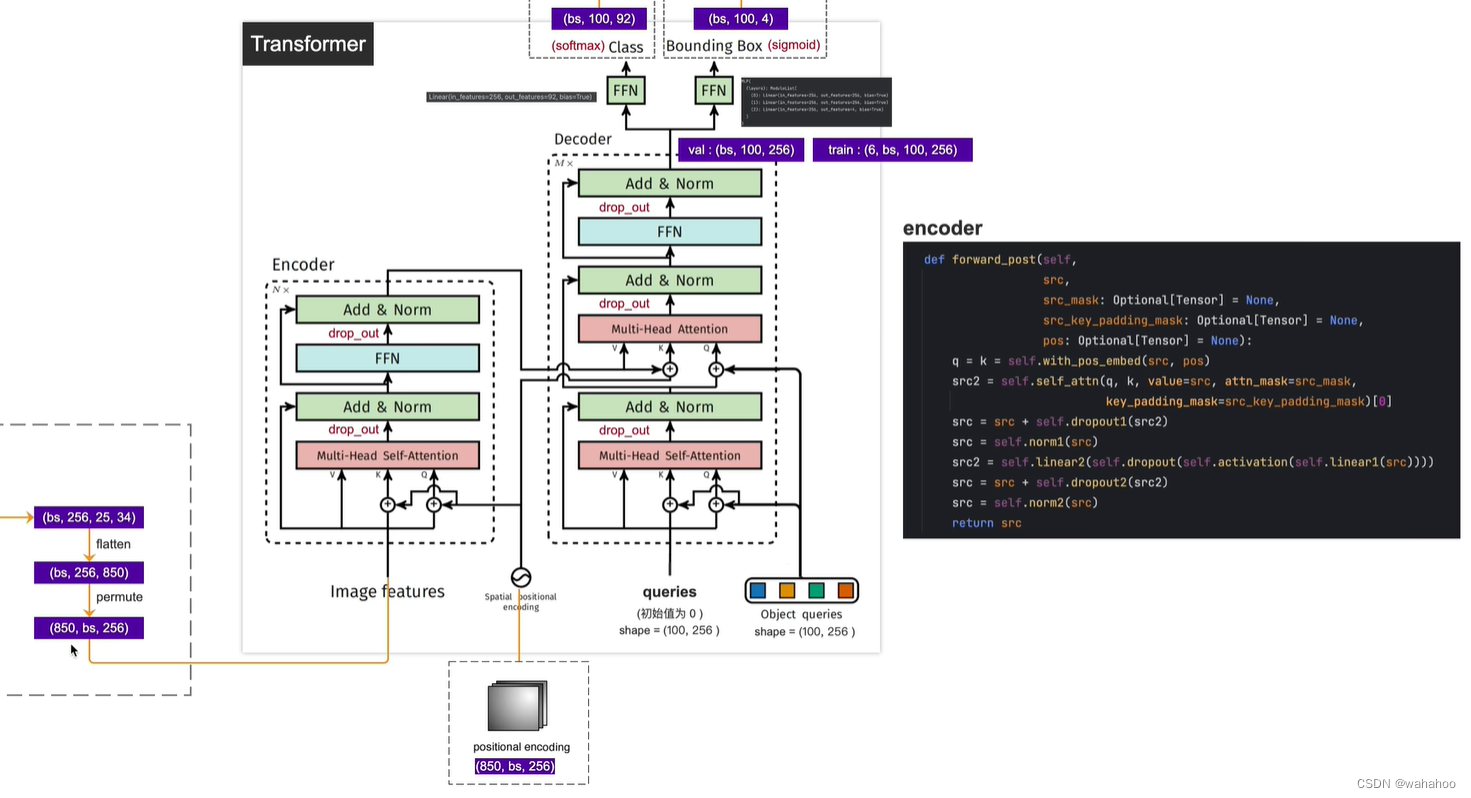
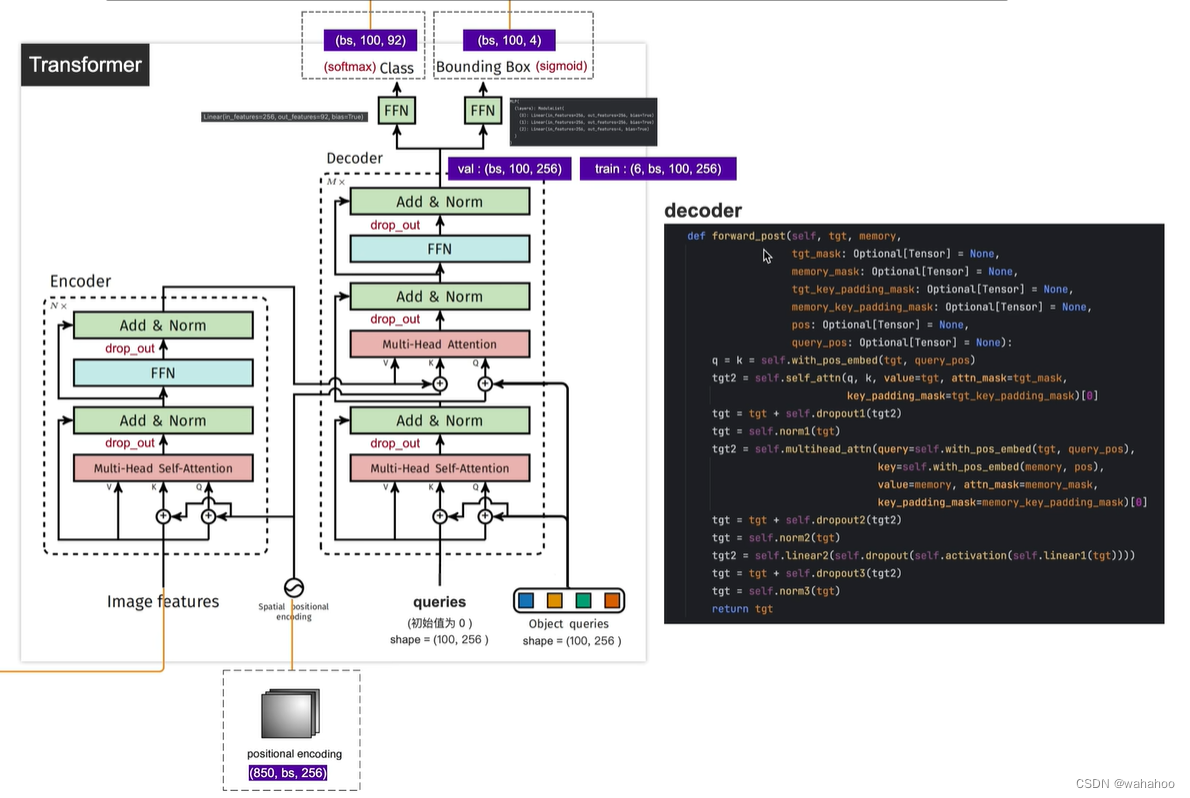
1. Q的来源不同
* Transformer中Q直接来自输入序列embedding
* DETR中Q是一组需要学习的目标先验框编码, 随机初始化
2. K和V的来源不同
* Transformer中K和V来自同一输入序列
* DETR中K和V来自输入图像的特征图
3. 维度的处理
* Transformer中Q,K,V维度是一致的
* DETR中需要将图像特征图的展平,并做线性映射到模型维度
4. 添加位置编码
* Transformer在序列embedding上添加位置编码,Query(Q)、Key(K)和Value(V)都包含了位置编码信,一次位置编码
* DETR只在Q和K上添加位置编码,而不在V上添加,而且在每一个encode中,都要加上位置编码一次,N次
因为q和k是用来计算图像特征中各个位置之间计算相似度/相关性的,加上位置编码后计算出来的全局特征相关性更强,而v代表原图像,所以并不需要加位置编码

















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









