






首先,这个模型是huggingface上开源的re-trained 3-layer RoBERTa-wwm-ext model,参数较少。参数文件仅有150mb。
另外,由于这个项目一开始做的并不是文本分类,而是完形填空。因而这里的部分将是迁移学习。
需要用的库为torch(>=1.10)、transformers、pandas。
数据集、模型、代码的目录结构如图所示:

1.加载数据
import pandas as pd
data=pd.read_csv("ChnSentiCorp_htl_all.csv")
data=data.dropna()
data

2.创建Dataset
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self,data_a) -> None:
super().__init__()
self.data = data_a
def __getitem__(self, index): #调用时返回元组
return self.data.iloc[index]["review"], self.data.iloc[index]["label"]
def __len__(self):
return len(self.data)
dataset = MyDataset(data)
for i in range(5):
print(dataset[i])

3.划分数据集
from torch.utils.data import random_split
trainset, validset = random_split(dataset, lengths=[0.9, 0.1])
print(len(trainset), len(validset))
print('-'*100)
for i in range(5):
print(trainset[i])

4.创建Dataloader
从Dataset中取出的数据是一条一条的,但训练时需要一个batch的数据来提高效率,所以需要创建Dataloader。
另外Dataset中并没有对原始数据进行词向量的映射,这一步将在这里完成。利用trasnformers的Tokenizer进行数据的预处理。
import torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("rbt3/")
def collate_func(batch):
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
#超过128长度的输入将被截断,默认返回一个列表,return_tensors=pt表示返回一个pytorch向量
inputs["labels"] = torch.tensor(labels)#将标签映射为tensor
return inputs
trainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
Dataloader说明
为了演示清晰,让batch_size=2。
trainloader和validloader需要用enumerate方法遍历。
len(DataLoader)*batch_size = 数据总条数
若不添加collate_fn参数,默认情况下:
用for循环遍历,每个单元 i 将返回一个二元组,第一个存放目前的索引,第二个存放数据部分。
i[0]是DataLoader中的数据条数,即与len(DataLoader)对应的索引。
i[1]返回一个列表,包含两个元素:i[1][0]是对应batch_size条数据组成的元组,i[1][1]是i[1][0]中每条数据对应的标签。
tst = DataLoader(trainset, batch_size=2, shuffle=True)
for i in enumerate(tst):
print(i)
print("Dataloader的长度为:",len(tst))
break

若添加collate_fn参数,则会依据collate_fn修改数据部分,即之前提到的i[1]。
这里的collate_func规定返回的是字典,tokenizer中包含input_idx, token_type_ids, attention_mask键,而后增加了一个labels的键。
tst1 = DataLoader(trainset, batch_size=2, shuffle=True,collate_fn=collate_func)
for i in enumerate(tst1):
print(i)
print("Dataloader的长度为:",len(tst1))
break

5.创建模型以及优化器
模型采用预训练的中文robert模型,因而用transformers实现引用模型
from torch.optim import Adam
model = AutoModelForSequenceClassification.from_pretrained("rbt3/")
if torch.cuda.is_available():#将模型放到GPU上
model = model.cuda()
optimizer = Adam(model.parameters(), lr=2e-5)
6.训练与验证
训练3个epoch,每个epoch训练100步输出一次结果,每一步训练一个batch也就是32条数据。(每个epoch均训练全部数据)
def evaluate():
model.eval()
acc_num = 0
with torch.inference_mode():
for batch in validloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)#将字典中的键值对全部传入模型
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
return acc_num / len(validset)
def train(epoch=3, log_step=100):#训练3个epoch,每个epoch训练100步输出一次结果,每一步训练一个batch也就是32条数据
global_step = 0
for ep in range(epoch):
model.train()
for batch in trainloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
optimizer.zero_grad()#每个循环将优化器中的梯度置0
output = model(**batch)#将字典中的键值对全部传入模型
output.loss.backward()#loss反向传播
optimizer.step()
if global_step % log_step == 0:
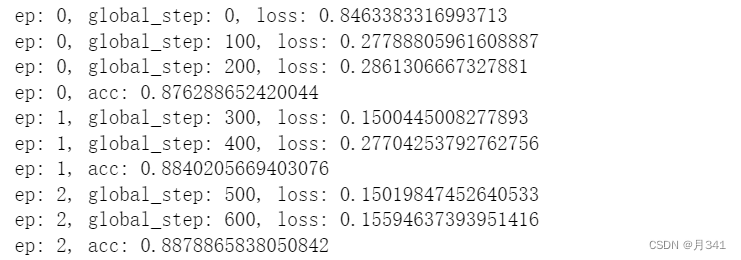
print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")
global_step += 1
acc = evaluate()
print(f"ep: {ep}, acc: {acc}")
train()
7.模型预测
基于原生pytorch的实现。
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}#由标签到答案的映射
model.eval()
with torch.inference_mode():
inputs = tokenizer(sen, return_tensors="pt")
inputs = {k: v.cuda() for k, v in inputs.items()}
logits = model(**inputs).logits
pred = torch.argmax(logits, dim=-1)
print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")

由于使用了预训练模型,那么也可以用transformers的Pipeline实现。
from transformers import pipeline
model.config.id2label = id2_label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
print(pipe(sen))
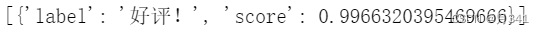















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









