






🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,前三年专注于Java领域学习,擅长web应用开发,目前专注于人工智能领域相关知识🌹
🦅个人主页:@逐梦苍穹(5600粉丝;60万访问量)
✈ 您的一键三连,是我创作的最大动力🌹
前言
先介绍一下二者:
- AutoDL是一个算力租赁平台,可以在上面租A100和4090等一众GPU;
- HuggingFace是一个开源社区,提供了很多开源模型,同时也提供了很多相关的python库,供开发者更好的训练/微调模型。
那么在AutoDL上使用HuggingFace相关库最大的问题是什么呢,是HuggingFace是国外网站,下载需要科学上网,但是AutoDL是国内的
解决方法
解决方法有三种,直接参考镜像网站的方法:
方法一:网页下载
在https://hf-mirror.com/搜索,并在模型主页的Files and Version中下载文件
方法二:huggingface-cli
-
安装依赖:pip install -U huggingface_hub -
设置环境变量:- Linux:export HF_ENDPOINT=https://hf-mirror.com
- Windows Powershell:$env:HF_ENDPOINT = “https://hf-mirror.com”
-
下载:- 下载模型: huggingface-cli download --resume-download gpt2 --local-dir gpt2
- 下载数据集:huggingface-cli download --repo-type dataset --resume-download wikitext --local-dir wikitext
- 可以添加 –local-dir-use-symlinks False 参数禁用文件软链接,这样下载路径下所见即所得
方法三:使用 hfd✨
hfd 是这个镜像站开发的 huggingface 专用下载工具,基于成熟工具 aria2,可以做到稳定高速下载不断线。
下载hfd:- wget https://hf-mirror.com/hfd/hfd.sh
- chmod a+x hfd.sh
安装aria2:- sudo apt update
- sudo apt install aria2
设置环境变量:- Linux:export HF_ENDPOINT=https://hf-mirror.com
- Windows Powershell:$env:HF_ENDPOINT = “https://hf-mirror.com”
下载:- 下载模型:./hfd.sh dreamingInTheSky-xzl2211/llama3.1-8B-BilingualTranslation
- 下载数据集:./hfd.sh dreamingInTheSky-xzl2211/BilingualData --dataset
哪个好用
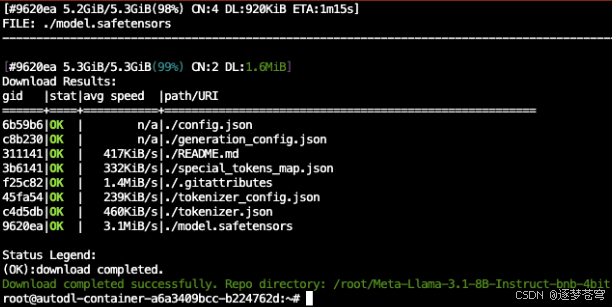
亲测”方法三:使用hfd“最稳定最有效,使用方法二也可以下载完成,但是不能中断。
所以建议使用hdf的方式:


















 6698
6698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











