






1.detect.py文件阅读
if __name__ == '__main__':
parser.add_argument()
// --weights default="指定的训练好的网络模型,下载好了可以直接用来检测,一般是pt结尾的"<"注意":如果模型下载不下来可以直接去github下载,下载好的.pt模型复制到根目录>
1.// --source default="给模型指定检测哪些图片/视频"
2.// --img-size default="尺寸大小" <这里的尺寸大小会把你的图片resize成这里的尺寸大小然后送到神经网络模型中训练>
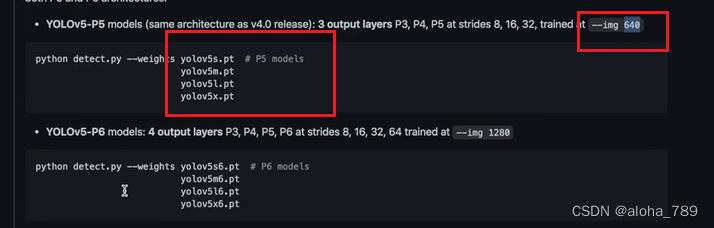
3.// --conf-thres default="0.25" <置信度,default表示图片中概率大于0.25才会把框画出来,具体那个合适需要自己进行调整>
4.// --iou-thres default="0.25",IOU大于设定的值就从多个框中选择一个合适的框,否则不做处理框都在那里.,例如default=1就有很多的框,都不做处理
5.// --view-img action="store_true"
使用步骤:1.命令行python detect.py --view-img,那么输出的图片结果会以弹窗的形式展现
方法二:
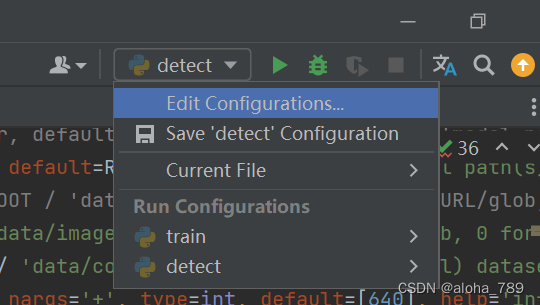
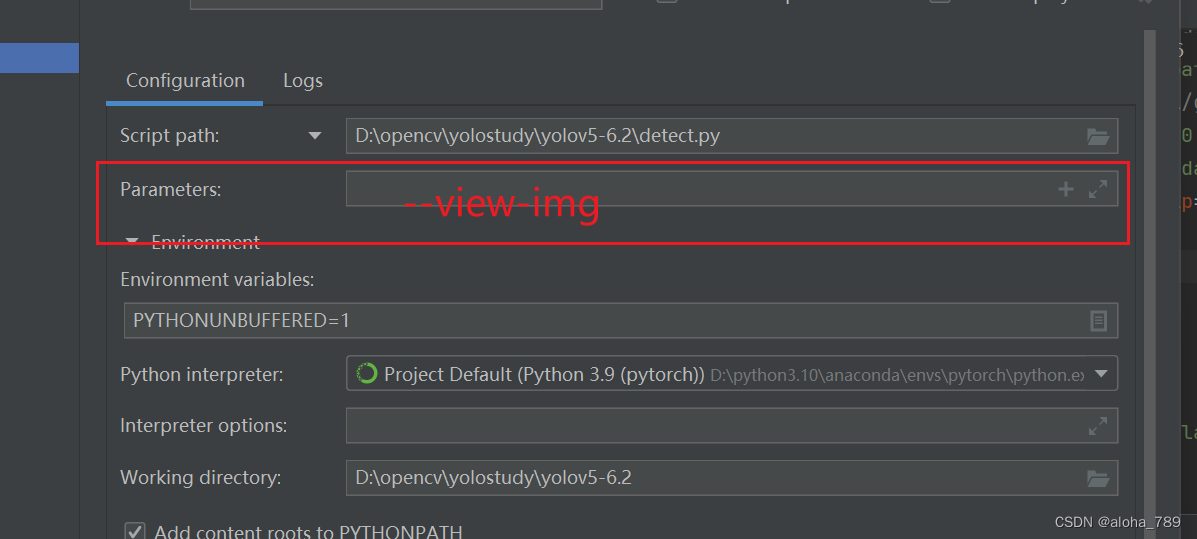
达到一样的效果
6.// --save-txt结果标注的框的位置坐标保存为txt文件
7.// --classes 0 在paramter内部设置,表示自己只需要哪个类别物体,例如只检测人 --classes 0
8.// --agnostic-nms数据增强
9.// --augment数据增强
10.// --project将结果保存到什么位置
2.训练yolov5模型
1.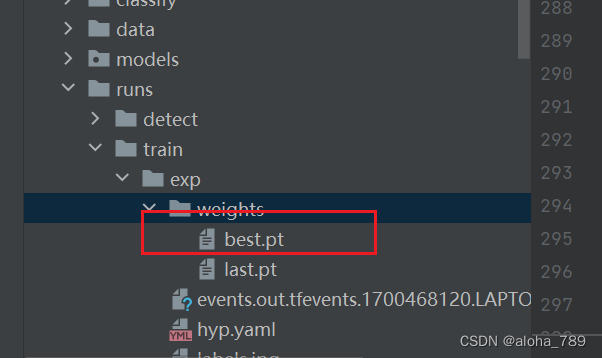
best.pt表示训练过程中最好的一轮网络模型参数,last.pt表示最近的一次网络模型参数
2.2
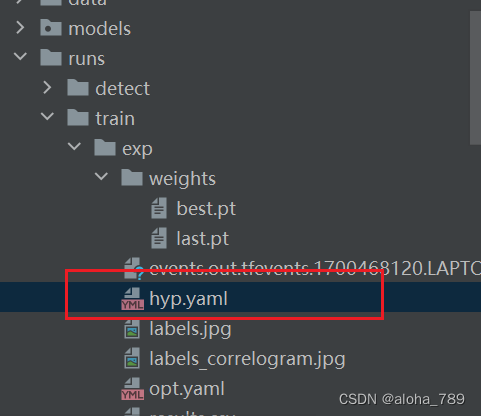
表示训练过程中模型的一些超参数
2.3
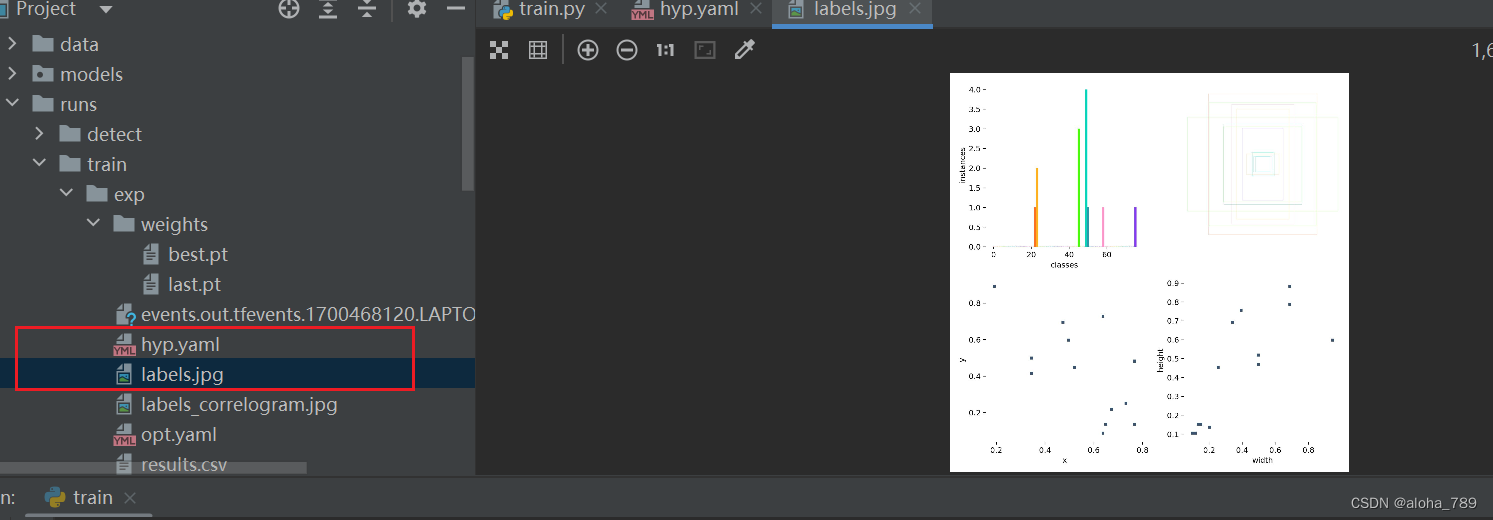
表示标注的一些分布
2.4
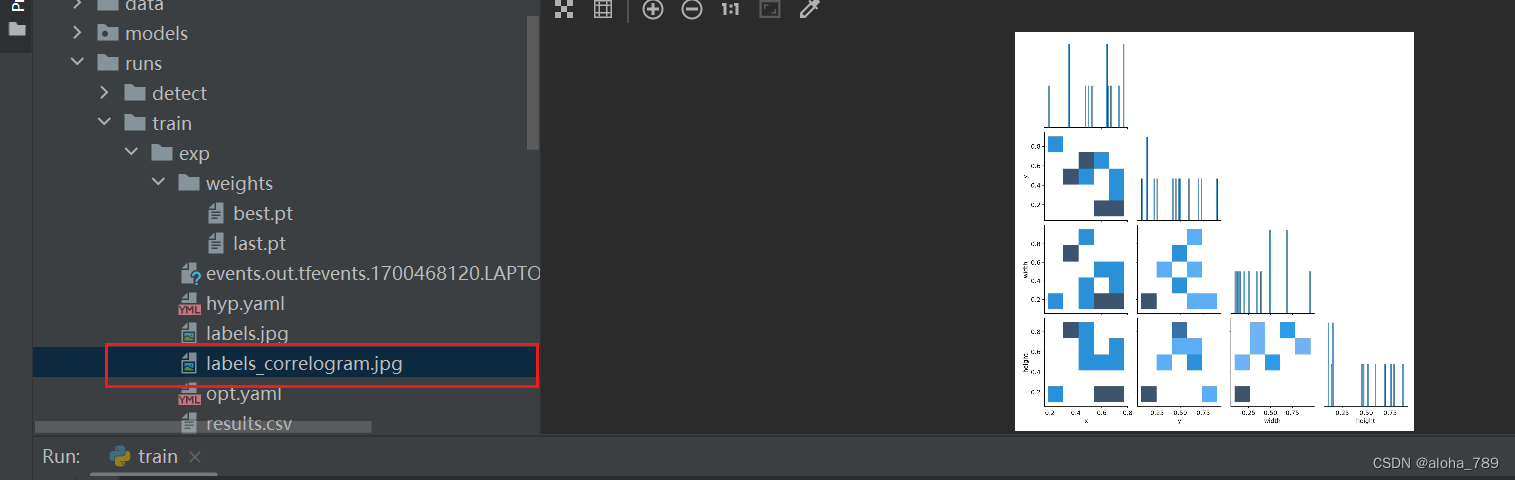
标注的一些相关矩阵
2.5
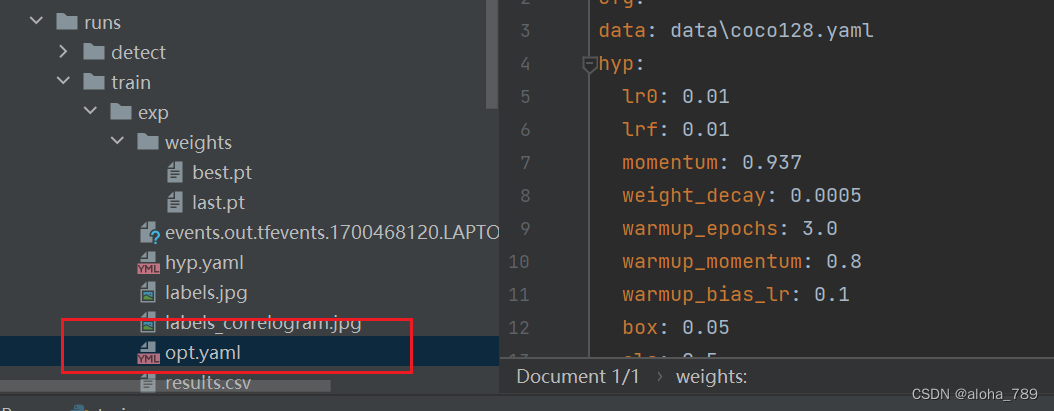
表示训练过程中对一些参数的设置
2.6
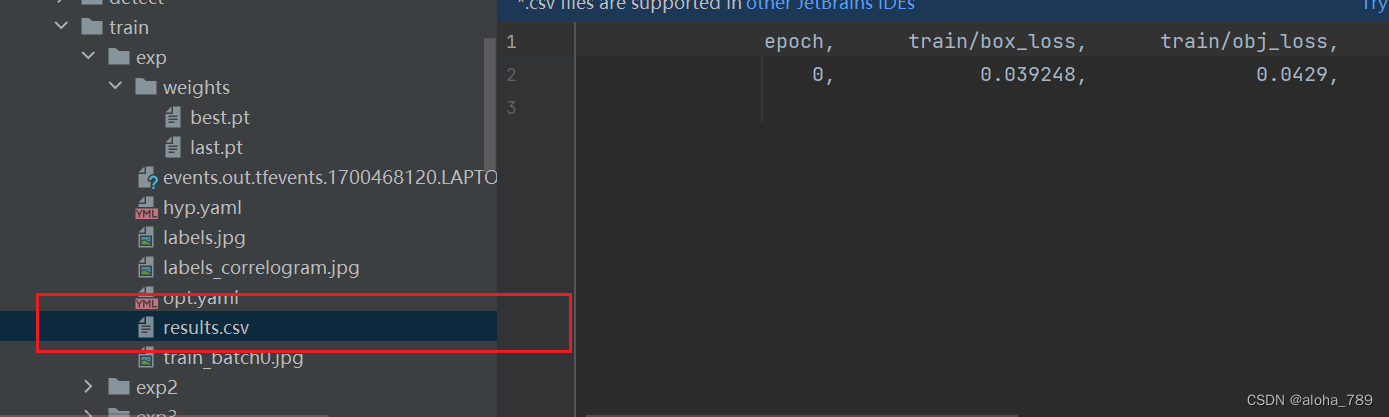
训练结果的一些记录
2.7
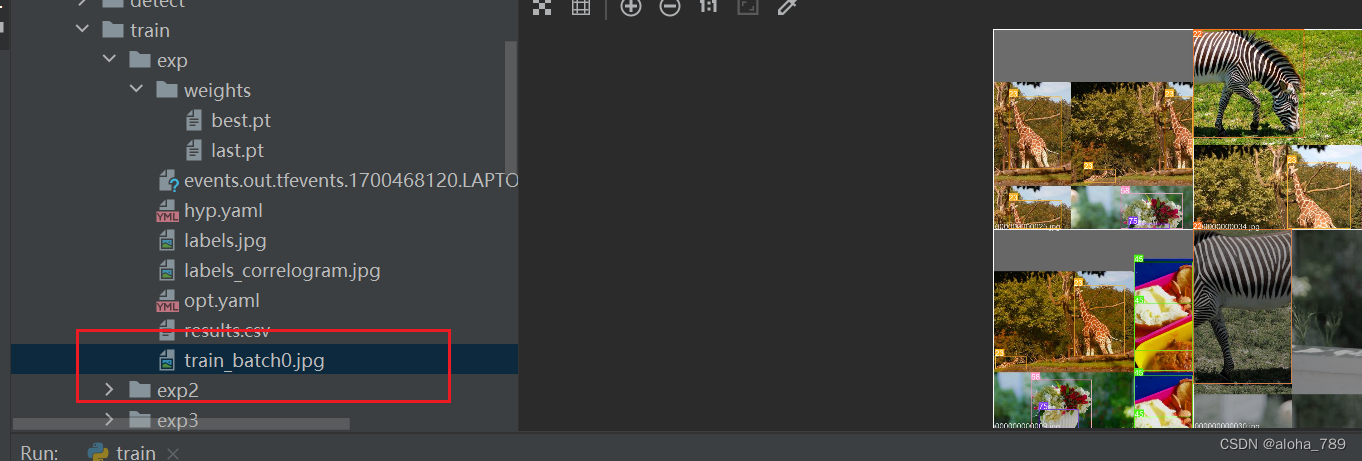
训练的一些图片长什么样子
3.train.py参数解读
def parse_opt(known=False):
// 对应的修改都是对default修改,以下不写defaults
'--weight': 指定一个训练好的模型,用这个模型来初始化网络中的参数
'--cfg': 模型的结构选择选择
'--data':选择的数据集
'--epochs':训练的轮数
'--hyp':对超参数的指定
'batch-size':把多少个数据打包成一组送到网络中进行训练
'img-size':设置训练集和测试集的大小
'--rect':矩阵推理,加速网络模型的训练
'resume':你想在哪个模型的基础上继续训练,一般参数指定是runs/train/exp/weights/last.pt文件夹下
针对–cfg可选参数如下图所示

针对–data可选的数据集
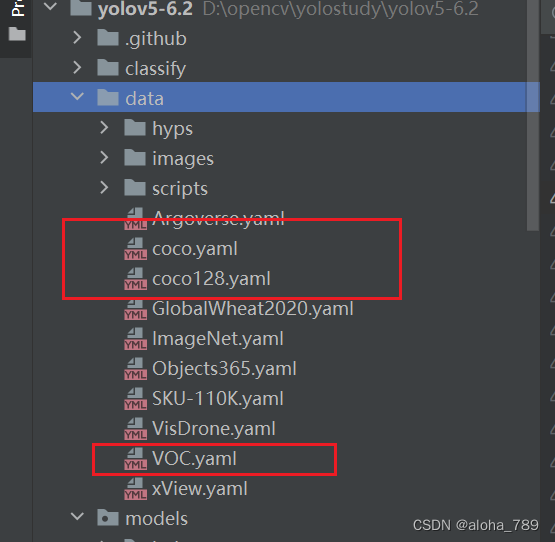















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









