






目录
4.MSCM:Multi-Scale Counting Module
5.CCAD:Counting-Combined Attentional Decoder
1.前言
最近在学习手写数学表达式的识别,crnn是入门之作,本篇是该领域的顶会文章。作了较为充足的准备,代码可以跑通但需要稍高的单显卡显存配置。
github代码地址:
CAN 整体框架是很清晰的:
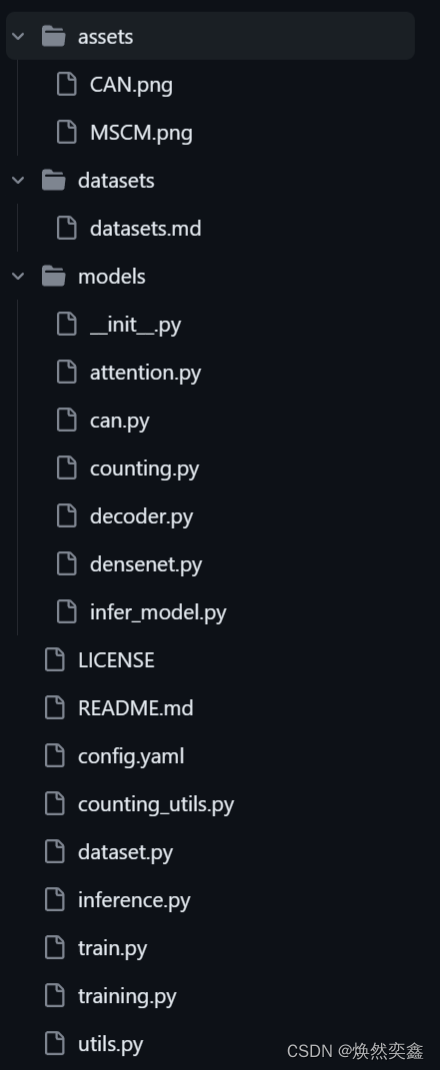
关注模型本身,我们主要弄懂densenet.py,attention.py,counting.py,decoder.py四个文件就行了。
2.CAN整体框架
CAN包括Backbone,CCAD和MSCM三个核心模块
Backbone: DenseNet 主要内容在densenet.py中
MSCM:Multi-Scale Counting Module 主要内容在counting.py中
CCAD:Counting-Combined Attentional Decoder 主要内容在attention.py和decoder.py中
3.Backbone: DenseNet
关于什么是densenet,请看这里Densenet,这里代码采用的DenseNet-B
backbone用来处理图片提取特征,得到特征图F,对应图中的:
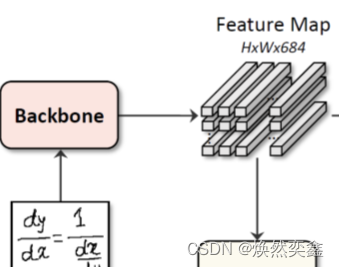
代码中定义了denseblock和transition类分别实现densenet的一个block和transition层。我通过调试,给出了输入x[batch_size,channel,height,width]经过backbone的处理流程:
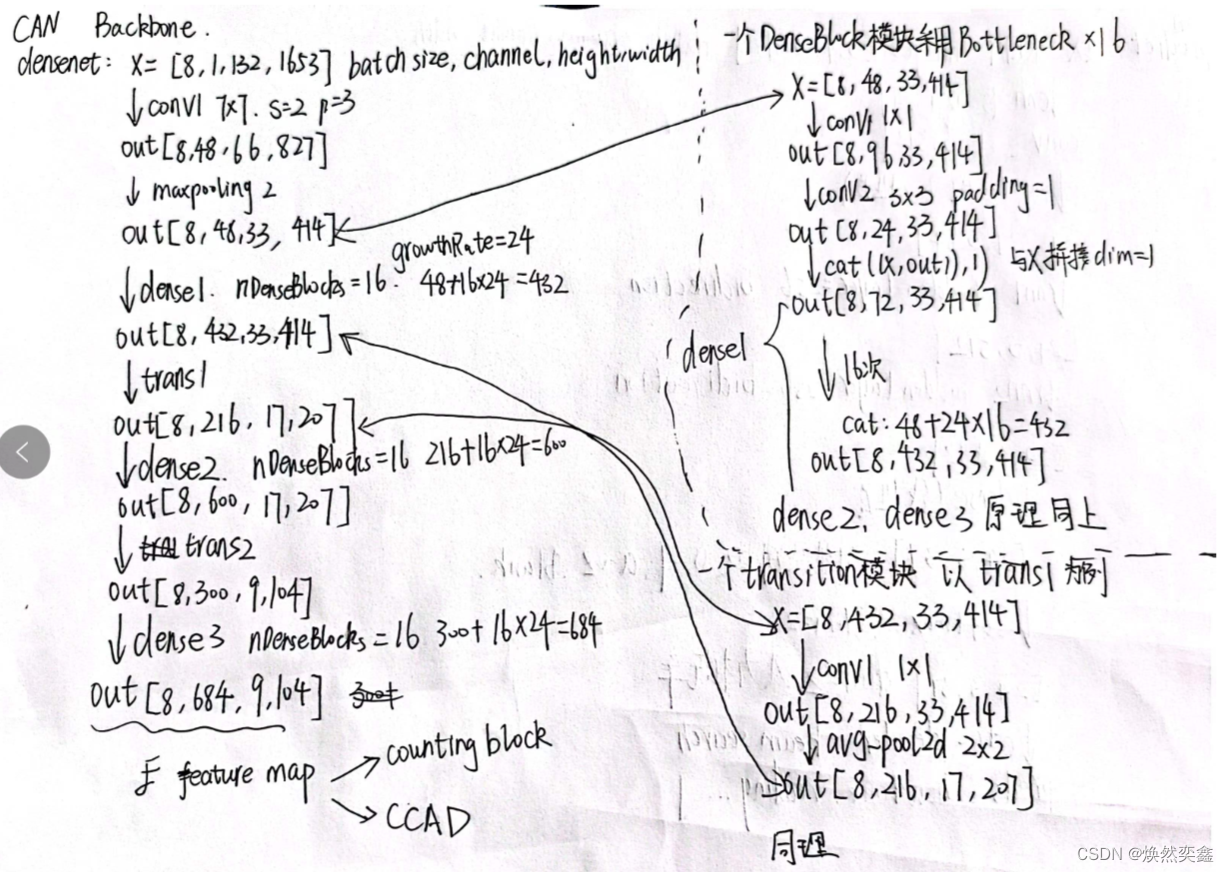
输入图片要经过dense1,2,3和transition1,2,右边给出了这两个模块对输入的具体处理过程,建议各位结合densenet.py源码看流程。
4.MSCM:Multi-Scale Counting Module
一个多尺度的计数模块,也是CAN这篇文章的主要创新点之一,能够关注到全局特征,作为一种弱监督。对应图中的:
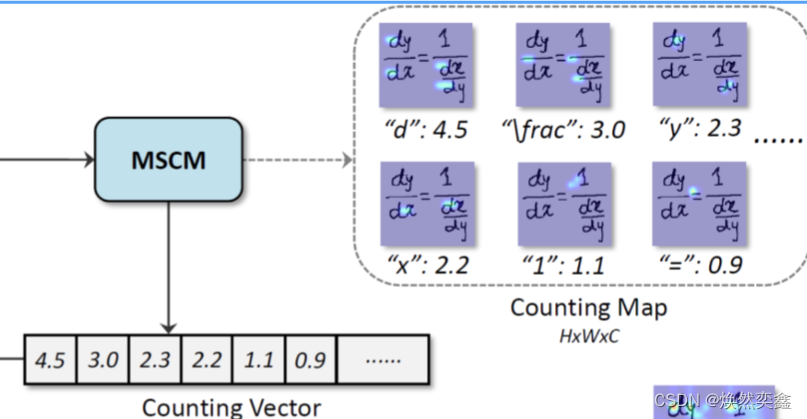
MSCM具体内部结构:
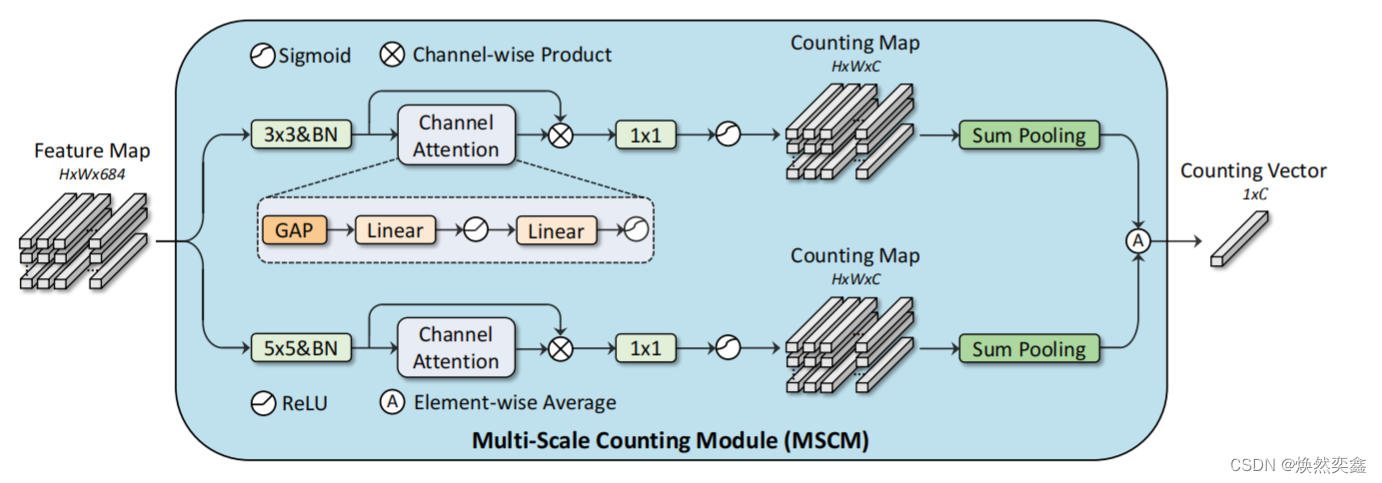
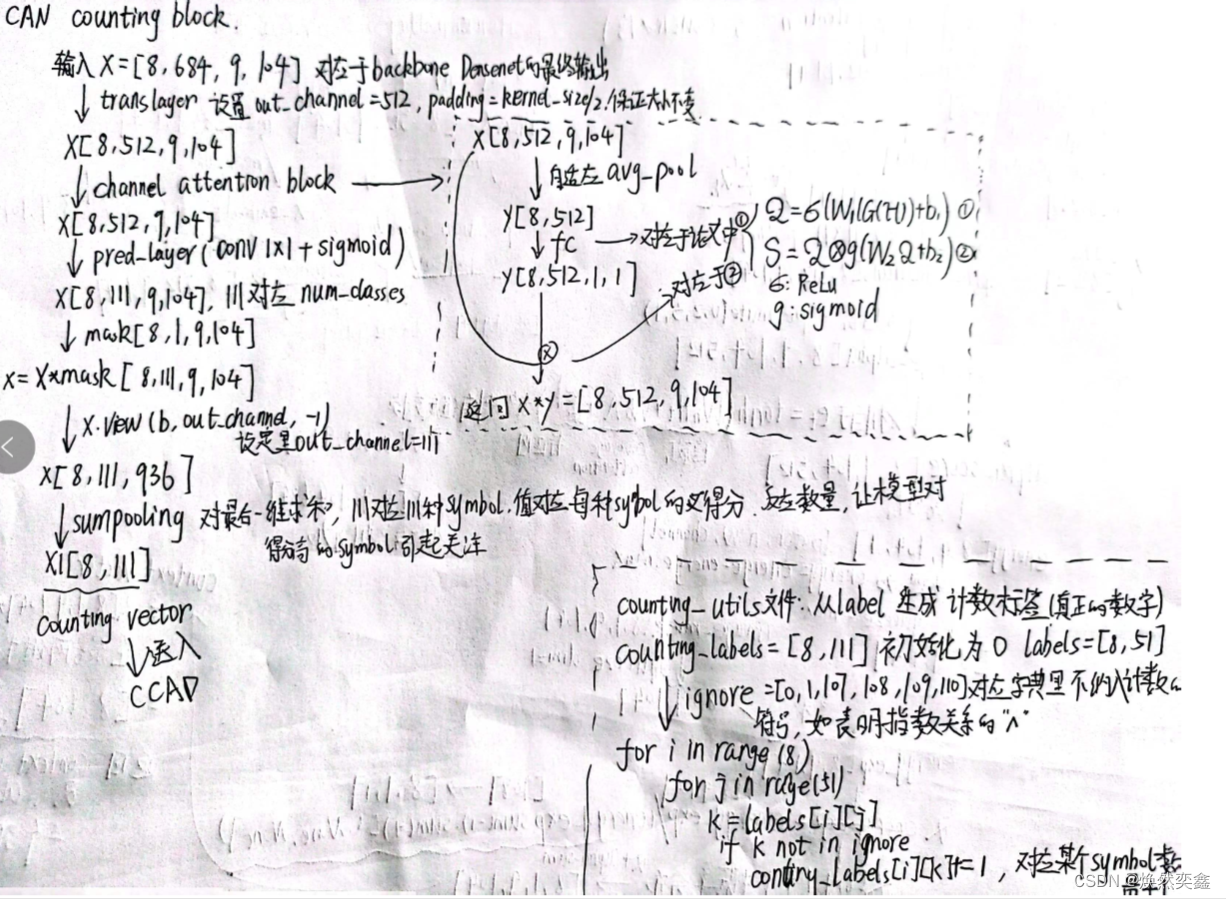
我们特别要注意这里的Multi-Scale,就是分别用3*3和5*5卷积核,代码中是怎样实现的呢?下面仅展示有需要代码:
#counting.py文件中定义了trans_layer 层,传入的是变量kernel_size
class CountingDecoder(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size):
self.trans_layer = nn.Sequential(
nn.Conv2d(self.in_channel, 512, kernel_size=kernel_size, padding=kernel_size//2, bias=False),
nn.BatchNorm2d(512))
# 因为是multi-scale feature extraction,two parallel convolution branches,kernel_size之后会设置3和5
#在前向传播中定义了trans_layer的传播
def forward(self, x, mask):
x = self.trans_layer(x)
#can.py文件中,引入了CountingDecoder类,并分别传入了kernel_size3,5
from models.counting import CountingDecoder as counting_decoder
class CAN(nn.Module):
self.counting_decoder1 = counting_decoder(self.in_channel, self.out_channel, 3)
self.counting_decoder2 = counting_decoder(self.in_channel, self.out_channel, 5)5.CCAD:Counting-Combined Attentional Decoder
对应图中的:
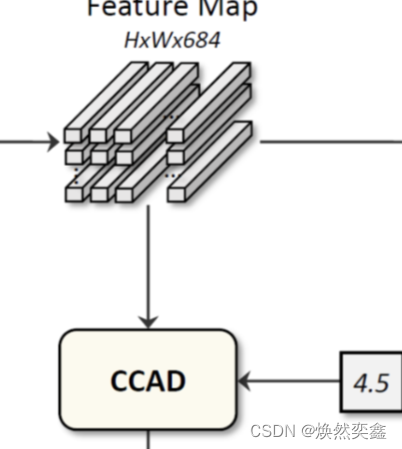
详细展开CCAD内部结构:
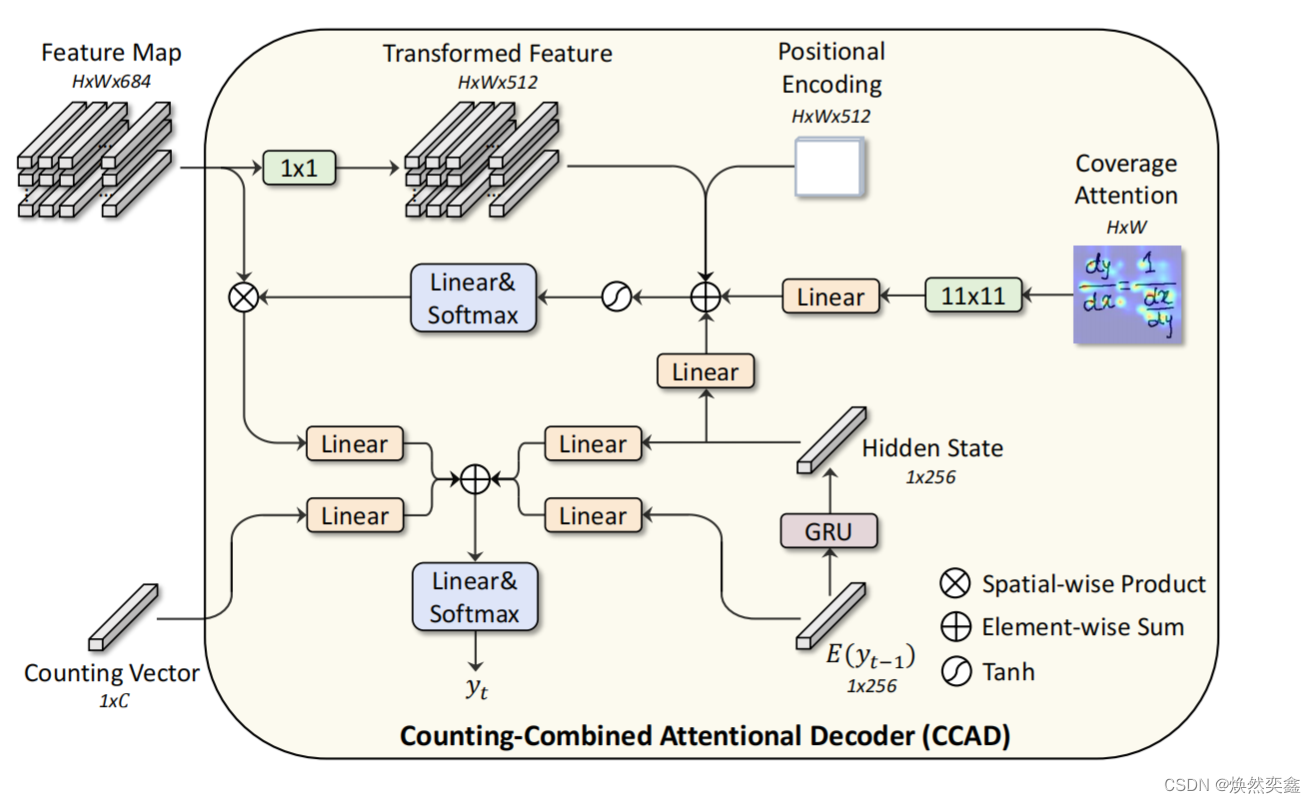
左下角的counting vector就是MSCM最终的输出计数向量,要作为CCAD的一个输入;另一个输入就是右上角Backbone的输出特征图F 。
attention.py文件的代码实现了注意力的加和以及处理,也就是对应这一部分:
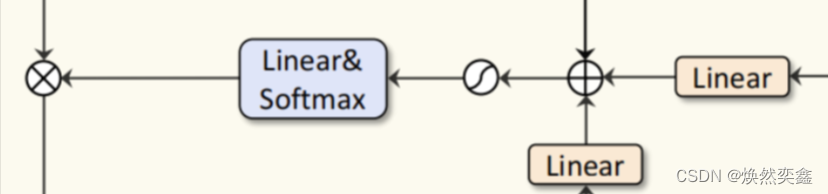
将Coverage attention,position encoding过的T和隐藏状态H进行求和并做处理 ,这一部分强烈建议结合代码来看,不然会觉得流程图很乱

decoder.py文件代码实现了最终的CCAD,调用attention.py实现注意力求和,而且还给出了Position encoding的代码。

前面我还好奇attention.py中定义的求和并没有加入Position encoding,原来在decoder.py进行了Position encoding与T的求和
position_embedding = PositionEmbeddingSine(256, normalize=True)
pos = position_embedding(cnn_features_trans, images_mask[:,0,:,:])
cnn_features_trans = cnn_features_trans + pos #T=T+position encoding














 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









