







基础 - 为什么有Docker
想象一下,你有一台电脑,上面安装了不同版本的操作系统、程序和依赖,来运行你的应用。但每次你把程序从一台电脑搬到另一台电脑,可能就会出问题,因为系统环境不一样了。
Docker就像是给你的应用做了一个“盒子”。这个盒子里面装着你应用运行所需的一切,包括操作系统、程序、库等等,不管你把这个盒子放到哪台电脑上,应用都能在盒子里的环境下运行,不会受外部环境的影响。
所以,Docker的好处就是:
- 一切打包在一起,解决了不同环境的兼容问题。
- 随时可以搬到任何地方运行,不受操作系统的限制。
- 启动速度快,并且比传统虚拟机更轻量,省资源。
就像你把一个应用放进一个随时可以搬运的小盒子里,这个盒子能在任何地方都顺利打开,应用就能正常运行。
基础 - Docker架构与容器化
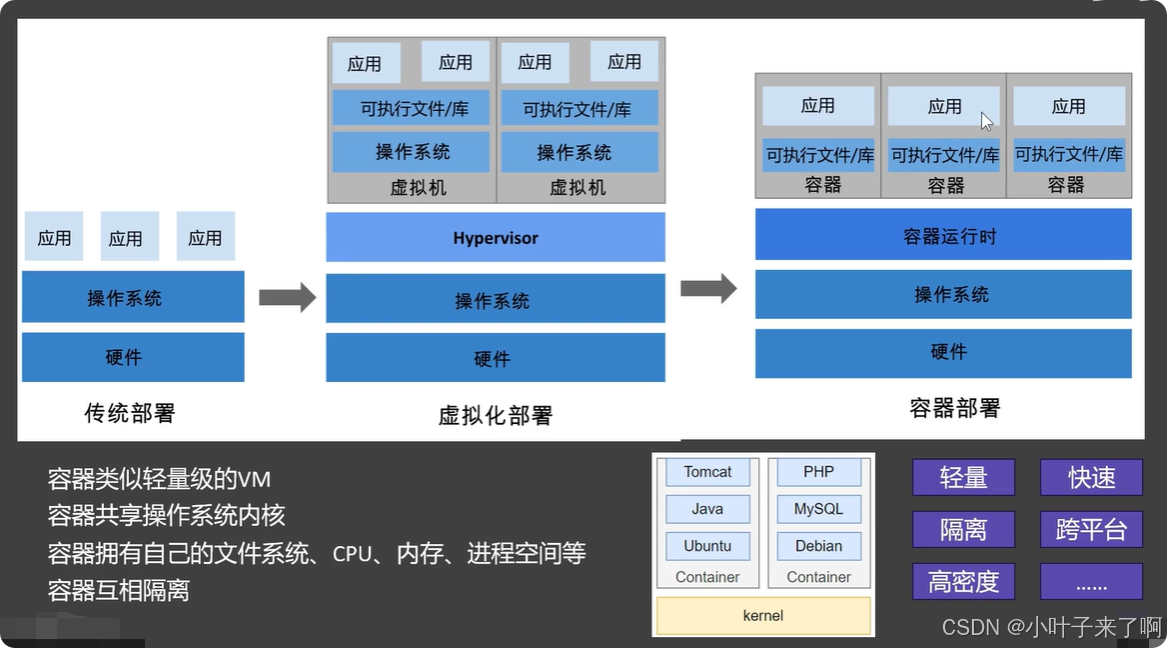
Docker是一个开放源代码的容器化平台,旨在简化应用程序的部署、扩展和管理。它基于容器化技术,将应用程序及其依赖打包成一个“容器”,在任何环境中都能快速一致地运行。理解Docker架构及容器化的概念,对于有效利用它的优势至关重要。
1. Docker架构
Docker架构的核心部分包括以下几个组件:
1.1 Docker引擎(Docker Engine)
Docker引擎是Docker的核心组件,分为两个部分:
- Docker守护进程(Docker Daemon):负责管理Docker容器、镜像等的创建、运行和管理。它可以接受来自Docker客户端的命令,并执行容器生命周期管理(例如,启动、停止、删除容器)。
- Docker客户端(Docker CLI):用户通过命令行与Docker守护进程交互,发送命令执行各种操作。比如,通过
docker run启动容器,docker ps查看正在运行的容器等。
1.2 Docker镜像(Docker Images)
Docker镜像是一个轻量级、可执行的独立软件包,它包含了运行应用所需的所有代码、运行时、库和系统工具。镜像是只读的,容器是从镜像启动的实例。镜像通常由多个层叠加而成,每一层都是文件系统的增量。
1.3 Docker容器(Docker Containers)
容器是Docker镜像的一个实例化,可以在隔离的环境中运行应用程序。容器与宿主操作系统共享内核,但相互隔离,保证应用和系统的独立性。容器具有启动速度快、占用资源少、便于扩展等优点。
1.4 Docker仓库(Docker Registry)
Docker仓库用于存储和共享Docker镜像。Docker Hub是一个公开的Docker镜像仓库,用户可以将镜像上传到Docker Hub,也可以从中下载镜像。企业可以搭建私有仓库,以便管理内部镜像。
1.5 Docker网络(Docker Networking)
Docker网络提供了容器之间的通信机制。每个容器都可以被分配到一个网络上,允许容器通过内部IP地址或服务名称进行通信。Docker支持多种网络模式,如bridge、host、overlay等。
2. 容器化概念
容器化是指将应用程序及其所有依赖项(如库、配置文件等)打包到一个标准化的单元——容器中。这种方式有很多优势,尤其在开发、测试和生产环境之间提供了高度的可移植性和一致性。
2.1 容器与虚拟化的区别
虽然容器和虚拟机都能提供环境隔离,但它们的工作方式有很大的不同:
- 虚拟机(VM):虚拟机运行在宿主操作系统之上,每个虚拟机都包含完整的操作系统(包括内核)。因此,虚拟机相对较重,启动时间长,资源消耗高。
- 容器:容器与宿主操作系统共享内核,它们只是隔离了运行环境。这使得容器比虚拟机更轻量,启动速度更快,资源消耗也更低。
2.2 容器化的优点
- 一致性:容器确保应用程序在开发、测试、生产环境中一致运行,避免了“在我机器上能运行”这种问题。
- 快速启动和高效资源利用:容器启动迅速,因为它们不需要加载整个操作系统。容器化应用可以节省更多的资源。
- 可移植性:容器包含应用程序及其所有依赖,可以在任何支持Docker的平台上运行,无论是本地开发环境还是云端平台。
- 隔离性:每个容器都是独立的,应用程序和它的依赖在容器中完全隔离,避免了冲突。
- 扩展性:容器化应用便于水平扩展,特别适合微服务架构。
2.3 容器编排
在生产环境中,容器的数量通常非常庞大,管理这些容器需要容器编排工具,如Kubernetes、Docker Swarm等。它们可以自动化容器的部署、扩展、监控和管理。
3. Docker工作流程
一个典型的Docker工作流程如下:
-
构建镜像:首先,开发者通过编写
Dockerfile来定义镜像的构建过程。Dockerfile是一个脚本,描述了如何从基础镜像开始,安装依赖并将应用程序添加到镜像中。 -
构建和推送镜像:使用
docker build命令构建镜像,然后将镜像推送到镜像仓库(如Docker Hub或私有仓库)中。 -
运行容器:通过
docker run命令从镜像启动一个容器,可以在容器中运行应用程序。 -
容器管理:使用
docker ps查看运行中的容器,docker stop停止容器,docker rm删除容器等。 -
容器编排与扩展:使用Kubernetes或Docker Swarm等工具来管理多个容器的部署和扩展。
4. 总结
Docker通过提供一种轻量级的容器化技术,使得应用程序能够在不同的环境中一致地运行,带来了更高的开发效率、更好的资源利用率和更简化的运维管理。掌握Docker的基本架构和工作流程,是现代开发人员和运维工程师的必备技能。
基础 - 安装Docker
安装
国内常见的云平台:阿里,腾讯,华为,青云
使用centos7.9
安装步骤
选择要安装的平台
Docker要求CentOS系统的内核版本高于3.10
uname -r #通过 uname -r 命令查看你当前的内核版本

# 移除旧版本docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 配置docker yum源。
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装 最新 docker
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 启动& 开机启动docker; enable + start 二合一
systemctl enable docker --now
# 配置加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"http://hub-mirror.c.163.com",
"https://mirrors.tuna.tsinghua.edu.cn",
"http://mirrors.sohu.com",
"https://ustc-edu-cn.mirror.aliyuncs.com",
"https://ccr.ccs.tencentyun.com",
"https://docker.m.daocloud.io",
"https://docker.awsl9527.cn"
]
}
EOF
# 重启后台进程(docker的在/etc/docker/daemon.json中)
sudo systemctl daemon-reload
# 重启docker进行配置文件重新加载
sudo systemctl restart docker命令
镜像操作----------------
# 搜索镜像
docker search 镜像名(不一定显示,很有可能找不到)
#下载镜像
docker pull 镜像名【:版本好,默认latest】
#查看已下载所有镜像
docker images=docker image ls列出所有的镜像列表
【
repository 镜像名 tag 镜像标签一般是版本,latest表示最新
imge id 表示镜像唯一id created 表示镜像什么时候创建 size 镜像大小
】
--------------------
# 删除镜像
docker rmi 镜像名【:tag】/唯一id
容器操作----------------
#运行一个新容器,启动时没有默认下载
docker run 镜像名【:tag】(默认最新)
docker run 【】 镜像名
#查看容器
docker ps 正在运行的容器
docker ps -a 查看所有容器
|container id 表示容器唯一id|image 表示使用的镜像
|command 容器的携带命令不用管
|created 表示容器创建时间|status 表示当前容器状态与时间 up表示开启
|ports 表示使用的端口与协议|names表示应用容器名字,没写随机指定
#启动已有容器
docker start id(可以只写前三位)/容器名
#停止容器
docker stop 容器名
#重启容器
docker restart (可以只写前三位)/容器名
#查看容器资源占用情况
docker stats (可以只写前三位)/容器名
#查看容器日志
docker logs (可以只写前三位)/容器名
#删除指定容器(要先stop容器)
docker rm (可以只写前三位)/容器名
#强制删除指定容器(运行中的也可以删除)
docker rm -f (可以只写前三位)/容器名
# 后台启动容器(-d后台启动,--name 为容器命名,不给就随机命名)
docker run -d --name mynginx nginx
# 后台启动并暴露端口(-p 外部端口:内部端口)
docker run -d --name mynginx -p 80:80 nginx
# 进入容器内部(-it表示要交互 )
docker exec -it 容器名/或者唯一id /bin/bash(交互方式)
【交换方式,/bin/bash表示使用这个shell交换】
【因为docker是轻量级的所以大概是没有vim了,要修改内容就用echo】
【exit退出容器,返回主机】
# 提交容器变化打成一个新的镜像(commit提交)
docker commit -m "update index.html" 你的容器名 你自定义的镜像名【:tag】
【
-a "作者是谁"
-m "提交信息"
-p 提交是暂停容器运行
-c 修改的列表
】
# 保存镜像为指定文件
docker save -o 你自定义的包名.tar 镜像名【:tag】
【
-o :将镜像写出成tar
】
# 删除多个镜像
docker rmi 多个id/镜像名(空格隔开)
# 加载镜像
docker load -i tar包的位置(加载完成后会直接变成镜像)
# 登录 docker hub
docker login
{
username:就写用户名或者邮箱
password:就写密码
}
# 重新给镜像打标签
docker tag 要上传的镜像【:tag】 用户名/新的镜像名【:tag】
# 推送镜像
docker push 用户名/新的镜像名【:tag】(这是上一个命令的后半截)存储
为什么要存储,与其说存储,比如说挂载或者映射,因为虽然我们可以进入容器的shell中,但是大多数容器都只是满足一点东西,比如为了小体积就不给vim了,或者是其他的东西。
那我们可不可以和磁盘一样挂载到主机上,利用主机完整的系统去操作呢?
当然可以,就这是下面要学的存储。
docker run -v 主要用途
-v选项用来在启动容器时,挂载一个文件夹或卷(volume)。挂载可以将宿主机的目录、文件,或者 Docker 管理的卷挂载到容器内,这样容器内的应用程序就能使用宿主机上的数据,或者容器的数据能持久化存储,即使容器停止或删除后数据依然存在。
等一下,我有一个疑问,挂载这个过程到底是怎么回事?
容器内部文件系统是临时的(房间内的物品,一旦房间被清理,物品就会消失)。 宿主机目录是持久化的(房间外的储藏室,物品一直存在,容器可以随时访问)。 通过 挂载,容器可以与宿主机目录共享数据,就像通过窗户把储藏室的数据引入容器房间,并允许容器和宿主机互相传递物品。 ---- 所以说使用了挂载本质上就是,当你访问一个文件时,未挂载就在容器里找,挂载了容器就会告诉你,去系统找,我这里不会给你的。这也就是为什么挂载后可以完成永久存储。
-v主要用于容器的 创建和启动 时(docker run和docker create)来挂载宿主机的目录或文件。- 它不能在容器运行后动态修改,因此需要在容器创建时指定挂载路径。
- 它的作用是 将宿主机的数据映射到容器内,提供容器与宿主机的数据共享或持久化存储。
挂载卷:两种常见场景
1. 挂载宿主机的目录到容器
这意味着你将宿主机上的一个目录与容器内部的目录进行映射。这样容器中对目录的任何操作都会反映到宿主机上。(这要你创建目录)
docker run -d -v /宿主机目录:/容器目录 镜像名(注意不要用/结束目录)
docker run -d -v /home/user/data:/app/data nginx
这个命令的意思是:
将宿主机的 /home/user/data 目录挂载到容器中的 /app/data 目录。
容器中的应用程序可以通过 /app/data 目录访问宿主机的文件。特点:
- 宿主机目录的文件可以直接被容器访问。
- 如果宿主机目录中没有文件,Docker 会创建一个空目录。
2. 挂载数据卷(volume)到容器【/var/lib/docker/volumes/<卷名>/_date下】
数据卷是由 Docker 管理的存储,可以在多个容器之间共享和持久化数据
docker run -d -v 自定义的卷名:/容器目录 镜像名
docker volume ls = docker volumes 列出所有的卷
docker volume create 卷名 创建卷
docker volume inspect 卷名 查看一个或多个卷细节
docker volume rm 卷名 删除一个或多个卷
docker volume prune 删除未使用的数据卷:该命令会查找所有未被任何容器使用的数据卷,并将它们删除。(有提示确认)
docker run -d -v my_volume:/app/data nginx
这个命令的意思是:
使用一个名为 my_volume 的数据卷,将其挂载到容器中的 /app/data 目录。
my_volume 是 Docker 自动管理的存储,它不依赖于宿主机的目录。即使容器删除,数据仍然保留在卷中。特点:
- 容器内的应用程序对数据的所有修改都会存储到
my_volume数据卷中。 - 可以跨多个容器共享数据。
如果你只想让容器读取数据,而不允许修改数据,可以使用 :ro(只读)标志:
docker run -d -v /home/user/app:/usr/share/nginx/html:ro nginx
看完了挂载,我们应该知道,目录挂载看容器外部文件,所以可以永久。卷挂载看容器内部文件,所以销毁就没有了。
docker网络
docker运行时会创建一个docker0(172.0.0.1开头,也就是bridge这个网络)的网络,所有的容器都会默认进入docker0这个网络,但是不支持主机域名,所以要创建自己的网络。

自定义网络
docker 【container】inspect 容器名 #查看容器详情
docker network create 自定义网络名 #创建一个网络
在docker run中添加--network 指定网络名
docker run -d --name app1 -p 80:80 --network mynet liye_nginx
在docker自己的网络中,容器可以相互访问
在自定义的网络中,容器名就是域名。比如访问app1(curl http://app1:端口号)Redis主从同步集群
准备:
拉取一个redis镜像,创建两个redis(端口6379)容器(一主一从),创建一个自定义网络
完成一个读写分离,主写从读。
{
非官方,比特纳米版
bitnami/redis镜像
}
#自定义网络
docker network create mynet
#主节点(-e 传入环境变量)
docker run -d -p 6379:6379 \
-v /app/rd1:/bitnami/redis/data \
-e REDIS_REPLICATION_MODE=master \
-e REDIS_PASSWORD=123456 \
--network mynet --name redis01 \
bitnami/redis
#从节点
docker run -d -p 6380:6379 \
-v /app/rd2:/bitnami/redis/data \
-e REDIS_REPLICATION_MODE=slave \
-e REDIS_MASTER_HOST=redis01 \
-e REDIS_MASTER_PORT_NUMBER=6379 \
#这个端口是非容器端口 \
-e REDIS_MASTER_PASSWORD=123456 \
-e REDIS_PASSWORD=123456 \
--network mynet --name redis02 \
bitnami/redis
#redis
用redis图形化工具测试一下Docker Compose
Docker Compose 是一个用于定义和运行多个 Docker 容器的工具。使用 Compose,你可以通过一个 docker-compose.yml 文件定义多容器应用,然后用一个简单的命令来启动和管理这些容器。
主要特点:
- 多容器管理:通过一个配置文件,管理多个容器、网络和卷。
- 易于使用:只需要一个命令就能启动所有的服务。
- 服务间的依赖管理:支持定义服务的依赖关系和启动顺序。
- 环境变量支持:支持在 Compose 文件中使用环境变量,或者通过
.env文件配置。 - 网络配置:可以配置容器间的网络,容器之间可以直接通信。
Docker Compose 使用示例
-
安装 Docker Compose
你可以通过以下命令安装 Docker Compose:
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose检查安装:
docker-compose --version -
docker-compose.yml 文件示例
假设你有一个简单的应用,其中包含一个
web服务和一个redis服务。以下是docker-compose.yml文件的示例:(用两个空格表示缩进嵌套)# 1. 定义 Compose 文件版本 version: '3.8' # 必填,定义文件使用的 Compose 版本 # 2. 项目名称(可选) name: myproject # 可选,项目的名称,默认为当前目录(有时候不支持,所以有相关报错就删除这一行吧) # 3. 容器服务配置 services: # 3.1. 定义 Web 服务 web: # 3.1.1. 容器名称(可选) container_name: web-container # 可选,指定容器的名称,默认使用服务名 # 3.1.2. 服务所用的镜像名称(必填) image: nginx:latest # 必填,指定容器运行的镜像 # 3.1.3. 服务暴露的端口(可选,可以配置多个) ports: - "8080:80" # 可选,宿主机端口与容器端口映射,格式:宿主机端口:容器端口 - "443:443" # 可选,可以添加多个端口映射 - "9000:9000" # 可选,同上 # <多个端口映射都可以按上述格式添加> # 3.1.4. 服务所需的环境变量(可选,可以配置多个) environment: - NGINX_HOST=mywebsite.com # 可选,设置环境变量 - NGINX_PORT=80 # 可选,定义应用所需的环境变量 # <多个环境变量可以继续添加> # 3.1.5. 挂载的数据卷(可选,可以配置多个) volumes: - ./html:/usr/share/nginx/html # 可选,主机目录或数据卷映射到容器路径 - nginx_data:/var/www/html # 可选,使用卷进行数据持久化 - /path/to/local:/path/in/container # 可选,多个挂载路径可以继续添加 # <多个卷挂载可以按上述格式添加> # 3.1.6. 设置重启策略(可选) restart: always # 可选,定义容器重启策略,如 always, on-failure, unless-stopped # <可以选择:always | on-failure | unless-stopped> # 3.1.7. 定义容器的依赖关系(可选,可以配置多个) depends_on: - db # 可选,定义启动顺序,确保 db 服务先启动 - redis # 可选,多个依赖服务可以继续添加 # <多个依赖服务可以按上述格式添加> # 3.1.8. 配置容器的健康检查(可选) healthcheck: test: ["CMD", "curl", "-f", "http://localhost/"] # 可选,定义健康检查命令 interval: 30s # 可选,检查间隔时间 retries: 3 # 可选,检查失败的重试次数 # 3.1.9. 设置日志驱动(可选) logging: driver: "json-file" # 可选,设置日志驱动,支持多种驱动(json-file, syslog 等) options: max-size: "10m" # 可选,最大日志文件大小 max-file: "3" # 可选,最多保留 3 个日志文件 # 3.1.10. 限制资源,如 CPU 和内存(可选) deploy: resources: limits: cpus: "0.5" # 可选,限制容器使用的 CPU 数量 memory: 512M # 可选,限制容器的内存使用量 # 3.1.11. 定义网络(可选,可以配置多个网络) networks: - webnet # 可选,容器之间通过指定的网络通信 - backend-net # 可选,可以配置多个网络 # <多个网络可以继续添加> # 3.2. 定义数据库服务(可选) db: container_name: db-container # 可选,指定容器名称 image: mysql:5.7 # 必填,使用的镜像 environment: - MYSQL_ROOT_PASSWORD=mysecretpassword # 可选,数据库的 root 密码 volumes: - db_data:/var/lib/mysql # 可选,使用卷持久化数据库数据 ports: - "3306:3306" # 可选,数据库端口映射 networks: - webnet # 可选,使用的网络 restart: always # 可选,容器重启策略 # 4. 定义卷(volumes)用于持久化数据(必填) volumes: nginx_data: # 必填,定义 nginx 数据卷 db_data: # 必填,定义数据库数据卷 # <多个卷可以继续添加,格式如:volume1: {}> # 5. 定义自定义网络(可选,可以配置多个网络) networks: webnet: # 可选,自定义的网络名称 driver: bridge # 可选,定义网络的驱动,默认是 bridge backend-net: # 可选,后台服务的专用网络 driver: bridge # 可选,定义网络的驱动 # <多个网络可以继续添加,格式如:net1: {driver: bridge}>version: '3.8' # 定义Docker Compose文件的版本 name: mynginx # (可选)定义项目的名称,这不是Compose的标准项,docker-compose会自动使用目录名作为项目名 services: # 服务定义部分 nginx: # 服务名称 image: nginx # 使用的镜像 ports: # 端口映射 - "80:80" # 映射容器的80端口到宿主机的80端口 volumes: # 数据卷映射 - nginx_data:/usr/share/nginx/html # 将nginx_data卷挂载到容器的指定路径 restart: always # 容器重启策略,如果容器停止会自动重启 volumes: # 定义外部数据卷 nginx_data: # 定义名为nginx_data的数据卷 -
使用 Docker Compose 服务(所有的命令都可以使用-f指定,在docker-compose后,不懂的可以用--help再看看)
默认启动就只能用这些名字:docker-compose.yml、docker-compose.yaml、compose.yml、compose.yaml 使用 Docker Compose 启动服务 在包含 docker-compose.yml 文件的目录下运行: docker-compose up 这会启动所有定义的服务(默认是前台运行),如果想要在后台运行,则使用 -d 参数: docker-compose up -d 这会在后台启动服务,并允许你继续操作终端。 docker-compose -f yml文件路径 up -d up命令应该在文件后面,所以up要在-f后 在启动一次就是更新数据 停止服务 docker-compose down 这个命令会停止并删除所有的容器、网络和卷(如果是用 docker-compose up -d 启动的)。 如果只想停止而不删除容器,可以使用: docker-compose stop 查看服务日志 docker-compose logs web 查看所有服务的日志: docker-compose logs -
其他常用命令
查看容器的状态: docker-compose ps 重新构建服务: docker-compose build 这个命令用于重新构建 Docker Compose 中定义的服务。如果你对 Dockerfile 或服务的配置进行了修改,可以使用该命令来重建镜像。 运行一次性命令: 运行一次性命令并启动容器。docker-compose run 会启动一个新的容器并执行指定的命令。这与 docker-compose up 不同,后者会根据配置启动所有服务并在后台运行。 docker-compose run <service_name> <command> 例如,如果你想在 web 服务中运行一个命令: docker-compose run web bash
Dockerfile
什么是dockerfile
Dockerfile 是一个文本文件,包含一系列的指令(指令用于定义镜像的构建步骤)。Dockerfile 描述了如何构建 Docker 镜像,包括需要的操作系统环境、安装的软件包、应用程序代码以及配置等内容。你通过编写 Dockerfile 文件,然后使用 docker build 命令根据这个文件创建一个 Docker 镜像。
dockerfile的语法与命令
# 使用官方的 Node.js 镜像作为基础镜像
FROM node:14
# 设置镜像维护者信息
LABEL maintainer="your-email@example.com"
# 设置工作目录,在该目录下执行后续命令
WORKDIR /app
# 将本地的 package.json 和 package-lock.json 复制到容器中的工作目录
COPY package*.json ./
# 安装项目依赖
RUN npm install
# 将本地的源代码复制到容器中的工作目录
COPY . .
# 设置环境变量
ENV NODE_ENV production
# 容器启动时运行的命令,启动 Node.js 应用
CMD ["node", "app.js"]
# 容器暴露 3000 端口供外部访问
EXPOSE 3000
# 使用 ARG 传递构建时的变量
ARG VERSION=1.0
RUN echo "Building version $VERSION"
# 使用 VOLUME 创建一个挂载点,以便容器和主机之间共享文件
VOLUME ["/data"]
# 采用多阶段构建,创建更小的最终镜像
# 第一阶段:构建阶段
FROM node:14 AS build
WORKDIR /build
COPY . .
RUN npm install
RUN npm run build
# 第二阶段:运行阶段(更加轻量化的生产环境镜像)
FROM node:14-slim
WORKDIR /app
# 从构建阶段中复制构建好的文件
COPY --from=build /build/dist /app
# 安装生产依赖
RUN npm install --production
# 设置容器启动时的命令
CMD ["node", "app.js"]
代码解析:
FROM:设置基础镜像,最初的镜像是 Node.js 镜像。
LABEL:添加镜像的元数据,例如维护者信息。
WORKDIR:设置容器内的工作目录,后续命令都将在此目录下运行。
COPY:将本地文件或目录复制到容器内。
RUN:在构建过程中运行命令,通常用于安装依赖或其他构建步骤。
ENV:设置环境变量,方便在容器运行时使用。
CMD:指定容器启动时执行的默认命令。
EXPOSE:声明容器会监听的端口。
ARG:在构建时传递变量,可以在构建过程中使用。
VOLUME:创建一个可以在容器和主机之间共享的挂载点。
多阶段构建:通过分阶段构建减少最终镜像的大小。第一个阶段用于构建应用,第二个阶段用于运行应用。深入理解
Dockerfile 的构建过程分为以下几个步骤:
docker build -t 自定义镜像名 -f /path/to/Dockerfile .
-
解析 Dockerfile
Docker 会逐行读取 Dockerfile 文件,解释每一条命令。 -
镜像构建
每执行一个RUN、COPY、ADD等命令时,Docker 都会创建一个新的镜像层。每一层都包含前一层的所有文件和操作。 -
缓存机制
Docker 会缓存构建过程中的每一层(除了某些特殊指令),如果 Dockerfile 没有变化,后续的构建可以跳过某些步骤,提高构建效率。 -
构建完成
最终,当 Dockerfile 里的所有指令都执行完毕,Docker 会将所有镜像层合并成一个最终的镜像。
超酷 - 一键启动所有中间件

先准备环境
#Disable memory paging and swapping performance
sudo swapoff -a
# Edit the sysctl config file
sudo vi /etc/sysctl.conf
# Add a line to define the desired value
# or change the value if the key exists,
# and then save your changes.
vm.max_map_count=262144
# Reload the kernel parameters using sysctl
sudo sysctl -p
# Verify that the change was applied by checking the value
cat /proc/sys/vm/max_map_countyaml
注意:
●将下面文件中 kafka 的 119.45.147.122 改为你自己的服务器IP。
●所有容器都做了时间同步,这样容器的时间和linux主机的时间就一致了
准备一个 compose.yaml文件,内容如下:
name: devsoft
services:
redis:
image: bitnami/redis:latest
restart: always
container_name: redis
environment:
- REDIS_PASSWORD=123456
ports:
- '6379:6379'
volumes:
- redis-data:/bitnami/redis/data
- redis-conf:/opt/bitnami/redis/mounted-etc
- /etc/localtime:/etc/localtime:ro
mysql:
image: mysql:8.0.31
restart: always
container_name: mysql
environment:
- MYSQL_ROOT_PASSWORD=123456
ports:
- '3306:3306'
- '33060:33060'
volumes:
- mysql-conf:/etc/mysql/conf.d
- mysql-data:/var/lib/mysql
- /etc/localtime:/etc/localtime:ro
rabbit:
image: rabbitmq:3-management
restart: always
container_name: rabbitmq
ports:
- "5672:5672"
- "15672:15672"
environment:
- RABBITMQ_DEFAULT_USER=rabbit
- RABBITMQ_DEFAULT_PASS=rabbit
- RABBITMQ_DEFAULT_VHOST=dev
volumes:
- rabbit-data:/var/lib/rabbitmq
- rabbit-app:/etc/rabbitmq
- /etc/localtime:/etc/localtime:ro
opensearch-node1:
image: opensearchproject/opensearch:2.13.0
container_name: opensearch-node1
environment:
- cluster.name=opensearch-cluster # Name the cluster
- node.name=opensearch-node1 # Name the node that will run in this container
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager
- bootstrap.memory_lock=true # Disable JVM heap memory swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Disables Security plugin
ulimits:
memlock:
soft: -1 # Set memlock to unlimited (no soft or hard limit)
hard: -1
nofile:
soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container
- /etc/localtime:/etc/localtime:ro
ports:
- 9200:9200 # REST API
- 9600:9600 # Performance Analyzer
opensearch-node2:
image: opensearchproject/opensearch:2.13.0
container_name: opensearch-node2
environment:
- cluster.name=opensearch-cluster # Name the cluster
- node.name=opensearch-node2 # Name the node that will run in this container
- discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster
- cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager
- bootstrap.memory_lock=true # Disable JVM heap memory swapping
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM
- "DISABLE_INSTALL_DEMO_CONFIG=true" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch
- "DISABLE_SECURITY_PLUGIN=true" # Disables Security plugin
ulimits:
memlock:
soft: -1 # Set memlock to unlimited (no soft or hard limit)
hard: -1
nofile:
soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536
hard: 65536
volumes:
- /etc/localtime:/etc/localtime:ro
- opensearch-data2:/usr/share/opensearch/data # Creates volume called opensearch-data2 and mounts it to the container
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:2.13.0
container_name: opensearch-dashboards
ports:
- 5601:5601 # Map host port 5601 to container port 5601
expose:
- "5601" # Expose port 5601 for web access to OpenSearch Dashboards
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch-node1:9200","http://opensearch-node2:9200"]'
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # disables security dashboards plugin in OpenSearch Dashboards
volumes:
- /etc/localtime:/etc/localtime:ro
zookeeper:
image: bitnami/zookeeper:3.9
container_name: zookeeper
restart: always
ports:
- "2181:2181"
volumes:
- "zookeeper_data:/bitnami"
- /etc/localtime:/etc/localtime:ro
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'bitnami/kafka:3.4'
container_name: kafka
restart: always
hostname: kafka
ports:
- '9092:9092'
- '9094:9094'
environment:
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://0.0.0.0:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://119.45.147.122:9094
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- ALLOW_PLAINTEXT_LISTENER=yes
- "KAFKA_HEAP_OPTS=-Xmx512m -Xms512m"
volumes:
- kafka-conf:/bitnami/kafka/config
- kafka-data:/bitnami/kafka/data
- /etc/localtime:/etc/localtime:ro
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
restart: always
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: true
KAFKA_CLUSTERS_0_NAME: kafka-dev
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
volumes:
- kafkaui-app:/etc/kafkaui
- /etc/localtime:/etc/localtime:ro
nacos:
image: nacos/nacos-server:v2.3.1
container_name: nacos
ports:
- 8848:8848
- 9848:9848
environment:
- PREFER_HOST_MODE=hostname
- MODE=standalone
- JVM_XMX=512m
- JVM_XMS=512m
- SPRING_DATASOURCE_PLATFORM=mysql
- MYSQL_SERVICE_HOST=nacos-mysql
- MYSQL_SERVICE_DB_NAME=nacos_devtest
- MYSQL_SERVICE_PORT=3306
- MYSQL_SERVICE_USER=nacos
- MYSQL_SERVICE_PASSWORD=nacos
- MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
- NACOS_AUTH_IDENTITY_KEY=2222
- NACOS_AUTH_IDENTITY_VALUE=2xxx
- NACOS_AUTH_TOKEN=SecretKey012345678901234567890123456789012345678901234567890123456789
- NACOS_AUTH_ENABLE=true
volumes:
- /app/nacos/standalone-logs/:/home/nacos/logs
- /etc/localtime:/etc/localtime:ro
depends_on:
nacos-mysql:
condition: service_healthy
nacos-mysql:
container_name: nacos-mysql
build:
context: .
dockerfile_inline: |
FROM mysql:8.0.31
ADD https://raw.githubusercontent.com/alibaba/nacos/2.3.2/distribution/conf/mysql-schema.sql /docker-entrypoint-initdb.d/nacos-mysql.sql
RUN chown -R mysql:mysql /docker-entrypoint-initdb.d/nacos-mysql.sql
EXPOSE 3306
CMD ["mysqld", "--character-set-server=utf8mb4", "--collation-server=utf8mb4_unicode_ci"]
image: nacos/mysql:8.0.30
environment:
- MYSQL_ROOT_PASSWORD=root
- MYSQL_DATABASE=nacos_devtest
- MYSQL_USER=nacos
- MYSQL_PASSWORD=nacos
- LANG=C.UTF-8
volumes:
- nacos-mysqldata:/var/lib/mysql
- /etc/localtime:/etc/localtime:ro
ports:
- "13306:3306"
healthcheck:
test: [ "CMD", "mysqladmin" ,"ping", "-h", "localhost" ]
interval: 5s
timeout: 10s
retries: 10
prometheus:
image: prom/prometheus:v2.52.0
container_name: prometheus
restart: always
ports:
- 9090:9090
volumes:
- prometheus-data:/prometheus
- prometheus-conf:/etc/prometheus
- /etc/localtime:/etc/localtime:ro
grafana:
image: grafana/grafana:10.4.2
container_name: grafana
restart: always
ports:
- 3000:3000
volumes:
- grafana-data:/var/lib/grafana
- /etc/localtime:/etc/localtime:ro
volumes:
redis-data:
redis-conf:
mysql-conf:
mysql-data:
rabbit-data:
rabbit-app:
opensearch-data1:
opensearch-data2:
nacos-mysqldata:
zookeeper_data:
kafka-conf:
kafka-data:
kafkaui-app:
prometheus-data:
prometheus-conf:
grafana-data:启动
# 在 compose.yaml 文件所在的目录下执行
docker compose up -d
# 等待启动所有容器访问
zookeeper可视化工具下载:
https://github.com/vran-dev/PrettyZoo/releases/download/v2.1.1/prettyZoo-win.zip
redis可视化工具下载:
https://github.com/qishibo/AnotherRedisDesktopManager/releases/download/v1.6.4/Another-Redis-Desktop-Manager.1.6.4.exe| 组件(容器名) | 介绍 | 访问地址 | 账号/密码 | 特性 |
| Redis(redis) | k-v 库 | 你的ip:6379 | 单密码模式:123456 | 已开启AOF |
| MySQL(mysql) | 数据库 | 你的ip:3306 | root/123456 | 默认utf8mb4字符集 |
| Rabbit(rabbit) | 消息队列 | 你的ip:15672 | rabbit/rabbit | 暴露5672和15672端口 |
| OpenSearch(opensearch-node1/2) | 检索引擎 | 你的ip:9200 | 内存512mb;两个节点 | |
| opensearch-dashboards | search可视化 | 你的ip:5601 | ||
| Zookeeper(zookeeper) | 分布式协调 | 你的ip:2181 | 允许匿名登录 | |
| kafka(kafka) | 消息队列 | 你的ip:9092 外部访问:9094 | 占用内存512mb | |
| kafka-ui(kafka-ui) | kafka可视化 | 你的ip:8080 | ||
| nacos(nacos) | 注册/配置中心 | 你的ip:8848 | nacos/nacos | 持久化数据到MySQL |
| nacos-mysql(nacos-mysql) | nacos配套数据库 | 你的ip:13306 | root/root | |
| prometheus(prometheus) | 时序数据库 | 你的ip:9090 | ||
| grafana(grafana) | 你的ip:3000 | admin/admin | ||
结束语(k8s再见)

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









