




 文章介绍了变异系数法的概念,通过数据正向化、标准化、计算变异系数和权重,进而计算得分。提供了基于Python和MATLAB的代码示例,用于处理风场运行数据,评估各风场的性能。
文章介绍了变异系数法的概念,通过数据正向化、标准化、计算变异系数和权重,进而计算得分。提供了基于Python和MATLAB的代码示例,用于处理风场运行数据,评估各风场的性能。
一、概念
1.1相关概念
变异系数法是根据统计学方法计算得出系统各指标变化程度的方法,是直接利用各项指标所包含的信息,通过计算得到指标的权重,因此是一种客观赋权的方法。
变异系数法根据各评价指标当前值与目标值的变异程度来对各指标进行赋权,若某项指标的数值差异较大,能明确区分开各被评价对象,说明该指标的分辨信息丰富,因而应给该指标以较大的权重;反之,若各个被评价对象在某项指标上的数值差异较小,那么这项指标区分各评价对象的能力较弱,因而应给该指标较小的权重。
1.2.算法原理
1.2.1 指标正向化

1.2.2 数据标准化

1.2.3 计算变异系数

1.2.4 计算权重以及得分
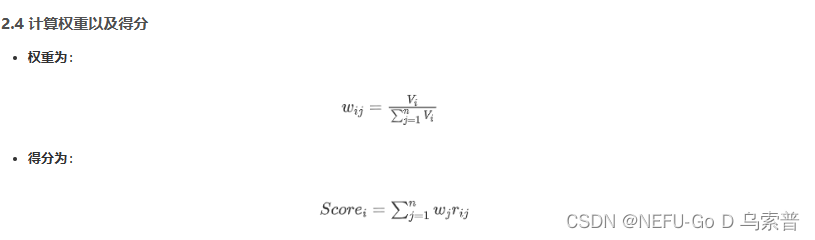
二、基于python的变异系数法
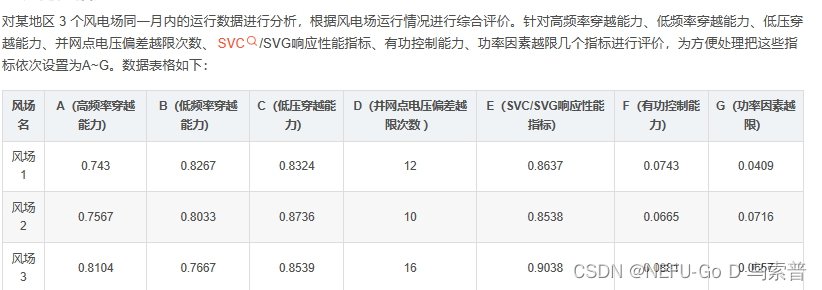
2.1问题描述
2.2代码实现
import pandas as pd
import numpy as np
#读取数据
data=pd.read_excel('风场运行数据.xlsx')
#数据正向化处理
label_need=data.keys()[1:]
data1=data[label_need].values
data2=data1.copy()
index=[3,5,6] #越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
k=0.1
for i in range(0,len(index)):
data2[:,index[i]]=1/(k+max(abs(data1[:,index[i]]))+data1[:,index[i]])
#数据标准化
[m,n]=data2.shape
data3=data2.copy()
for j in range(0,n):
data3[:,j]=data2[:,j]/np.sqrt(sum(np.square(data2[:,j])))
#计算变异系数
A=np.average(data3, axis=0)
S=np.std(data3, axis=0)
V=S/A
# 计算权重
w=V/sum(V)
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i+1}个风场百分制得分为:{Score[i]}")
三、基于MATLAB的变异系数法
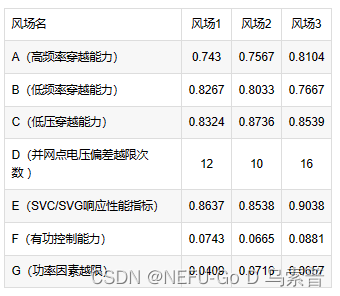
3.1 读取数据
data=xlsread('D:\桌面\变异系数.xlsx')
3.2 指标正向化
%指标正向 化处理后数据为data1
data1=data;
%%负向指标(越小越优型指标)处理
index=[4,6,7];%负向指标位置
k=0.1;
for i=1:length(index)
data1(:,index(i))=1./(k+max(abs(data(:,index(i))))+data(:,index(i)))
end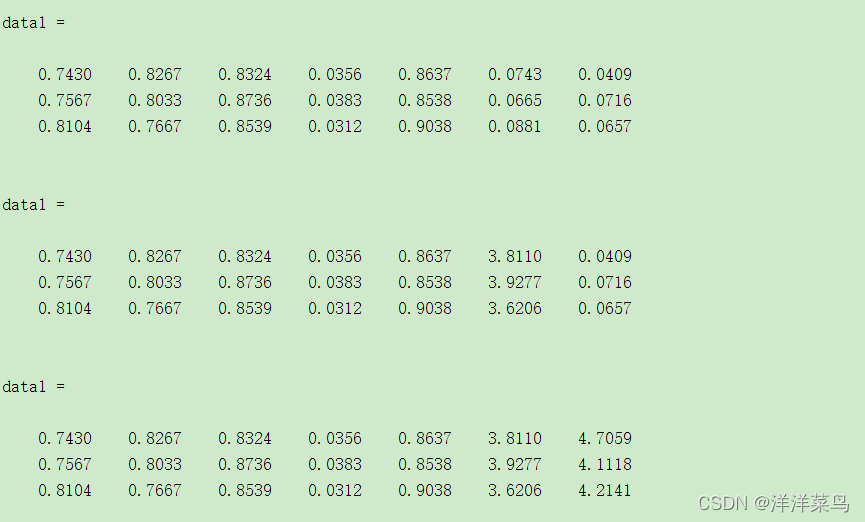
3.3 数据标准化
%数据标准化
data2=data1;
for j=1:size(data1,2)
data2(:,j)= data1(:,j)./sqrt(sum(data1(:,j).^2));
end
data2
3.4 计算变异系数
%计算变异系数
A=mean(data2) %求每列平均值
S=std(data2) %求每列方差
V=S./A %变异系数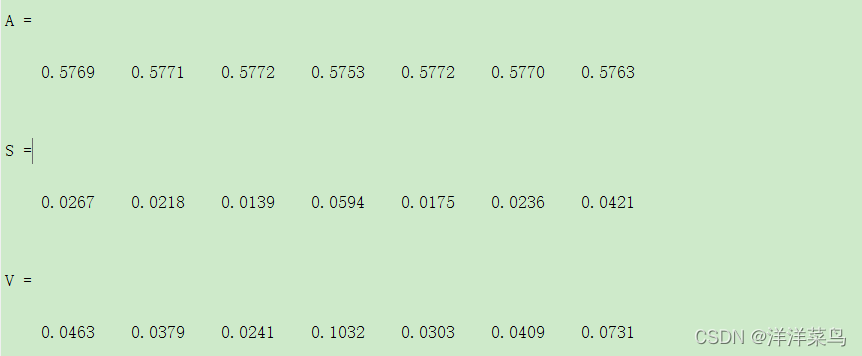
3.5 计算权重
%计算权重
w=V./sum(V)
3.6 计算得分
%计算得分
s=data2*w';
Score=100*s/max(s);
for i=1:length(Score)
%A(i,:)=[row(i), col(i), rho_1(row(i), col(i))];
fprintf('第%d个风场百分制评分为:%d\n',i,Score(i));
end
完整代码
clc;clear;
data=xlsread('D:\桌面\变异系数.xlsx');
%指标正向 化处理后数据为data1
data1=data;
%%负向指标(越小越优型指标)处理
index=[4,6,7];%负向指标位置
k=0.1;
for i=1:length(index)
data1(:,index(i))=1./(k+max(abs(data(:,index(i))))+data(:,index(i)));
end
%数据标准化
data2=data1;
for j=1:size(data1,2)
data2(:,j)= data1(:,j)./sqrt(sum(data1(:,j).^2));
end
data2;
%计算变异系数
A=mean(data2); %求每列平均值
S=std(data2); %求每列方差
V=S./A; %变异系数
%计算权重
w=V./sum(V);
%计算得分
s=data2*w';
Score=100*s/max(s);
for i=1:length(Score)
%A(i,:)=[row(i), col(i), rho_1(row(i), col(i))];
fprintf('第%d个风场百分制评分为:%d\n',i,Score(i));
end

















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











