






个人笔记记录,由于水平有限,代码可能略有繁琐,仅供参考
由于代码中可能存在少量bug,在此列出代码最后更新时间,如果有更新,建议重新复制代码使用
最后更新代码时间:2024/07/29 4:55
非lst文件直接点目录跳转至“使用Python进行数据自动化处理”即可
处理lst文件的一般步骤
一些拉伸机(比如我们组的拉伸机)保存数据的格式为.lst(一种类csv文件)
一般处理此类文件并绘图需要如下五步,对于操作不太熟练的同学,处理一个数据可能就要消耗近十分钟
- 从lst文件中选取所需数据复制到Excel中,并设置“,”的分隔符,让数据在表格中分列
这是由于在我们使用的绘图数据之前有数百列对于绘图无意义的数据
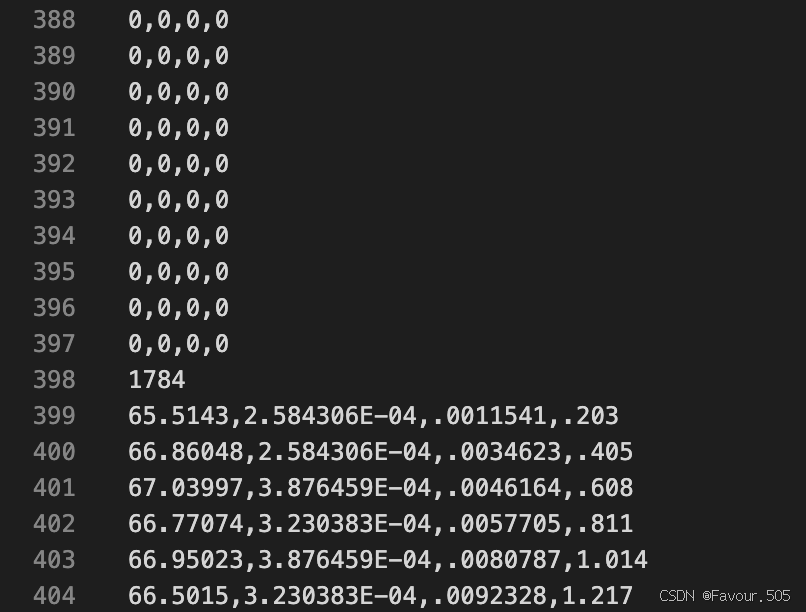
这个示例数据从399行才开始有意义
同时,绘图数据一般以前两列(力/N、长度增量/mm)作为基础 - 删除多余的绘图数据(删除试样断裂后未及时停机出现的数据)
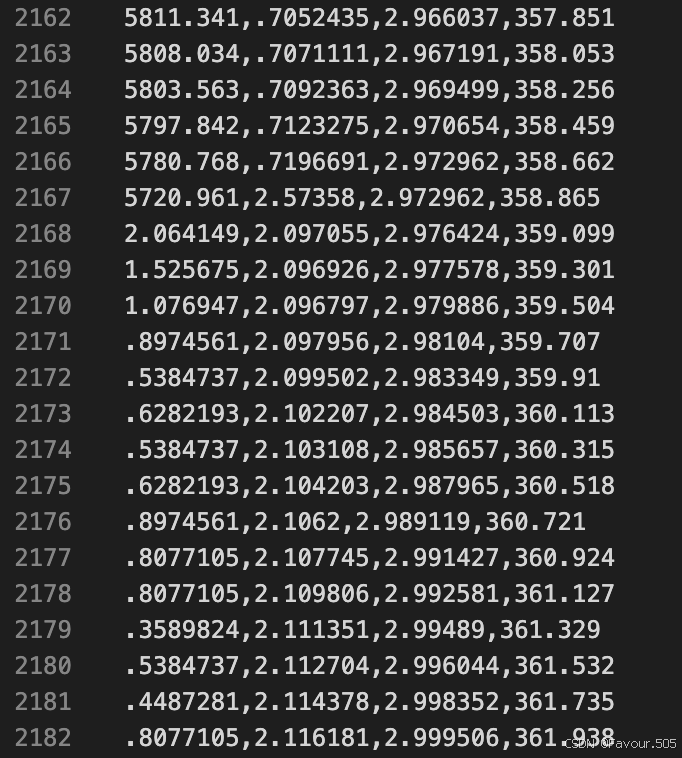
删除第二列(长度增量)开始骤增后的数据(2167及以后) - 在Excel中做运算,得到应力应变
S t r e s s ( M P a ) = 第一列原始数据 试样截面面积 Stress(MPa)=\frac{\text{第一列原始数据}}{\text{试样截面面积}} Stress(MPa)=试样截面面积第一列原始数据
S t r a i n = 第二列原始数据 标距段原始长度(本引伸计为10) Strain=\frac{\text{第二列原始数据}}{\text{标距段原始长度(本引伸计为10)}} Strain=标距段原始长度(本引伸计为10)第二列原始数据
如果Strain用百分比表示需再乘100% - 将应力应变导入Origin的工作表中,做折线图并调整线宽、字体等参数
- 用Origin做直线拟合弹性段区间,取拟合曲线的k值做出两平行线,分别求出屈服强度与延伸率
使用Python进行数据自动化处理
为了节省处理数据的时间,并对曲线进行美观,个人编写了两个Python代码,分别做到一键式处理lst文件及一键式绘图(同时给出屈服强度、抗拉强度、延伸率、弹性模量),下对部分代码进行解释
VS Code的安装及Python环境配置
VSC的功能极为丰富,可以通过安装社区丰富的包来打开各种形式的文件(.py、.csv、.lst、.xlsx、.docx……),建议使用VSC来实现数据处理与绘图均在一个页面中完成
篇幅有限,在此对VSC不做赘述,步骤可以参考CSDN中各位大佬的文章,下给两篇作为参考,过程中VSC遇到的绝大多数问题均可在网上查到解决方案(doge)
VS Code安装:Visual Studio Code安装及设置
Python环境配置:VS Code配置使用 Python,超详细配置指南,看这一篇就够了
代码详解
建议运行代码时使用虚拟环境,个人使用的虚拟环境Python版本为3.9.19,pandas库版本2.2.2(这个代码逻辑比较简单,应该不怎么涉及库版本冲突问题,按自己喜好安装即可)
要在虚拟环境中安装各种库,使用代码如下
# 打开终端(不会可以在csdn搜)
# 进入虚拟环境,假如环境名称为huanjing
conda activate huanjing
# 此时终端最左侧会显示你的虚拟环境名,如果要安装pandas库
pip install pandas
# 把代码最开始import和from后跟的库都装一遍就行
# 对于本文涉及的代码,可以使用以下命令一次性安装所用库
pip install pandas matplotlib numpy scikit-learn
过程中遇到的各种报错csdn应该都能查到解决方案
数据预处理部分
如果已有处理好的csv文件,序号2往后可以不用看
该代码实现了自动从lst文件中提取所需要的拉伸曲线数据部分并另存为一个名为“Proc_{你的lst文件名}.csv”的文件(从有合理的拉伸数据开始,到应变产生巨大变化的部分结束,与上述一般处理逻辑类似)
- 在合适路径建一个“数据”文件夹,文件夹中放代码文件,然后在该文件夹下创建小文件夹放不同试验的数据,用VSC的功能面板中的文件-打开文件夹(注意不是打开文件)来打开“数据”文件夹,如下
- 将代码(后附)复制粘贴到VSC中,使用.py和.ipynb文件格式均可,复制后可以点击def旁的小三角让函数折叠,效果如下
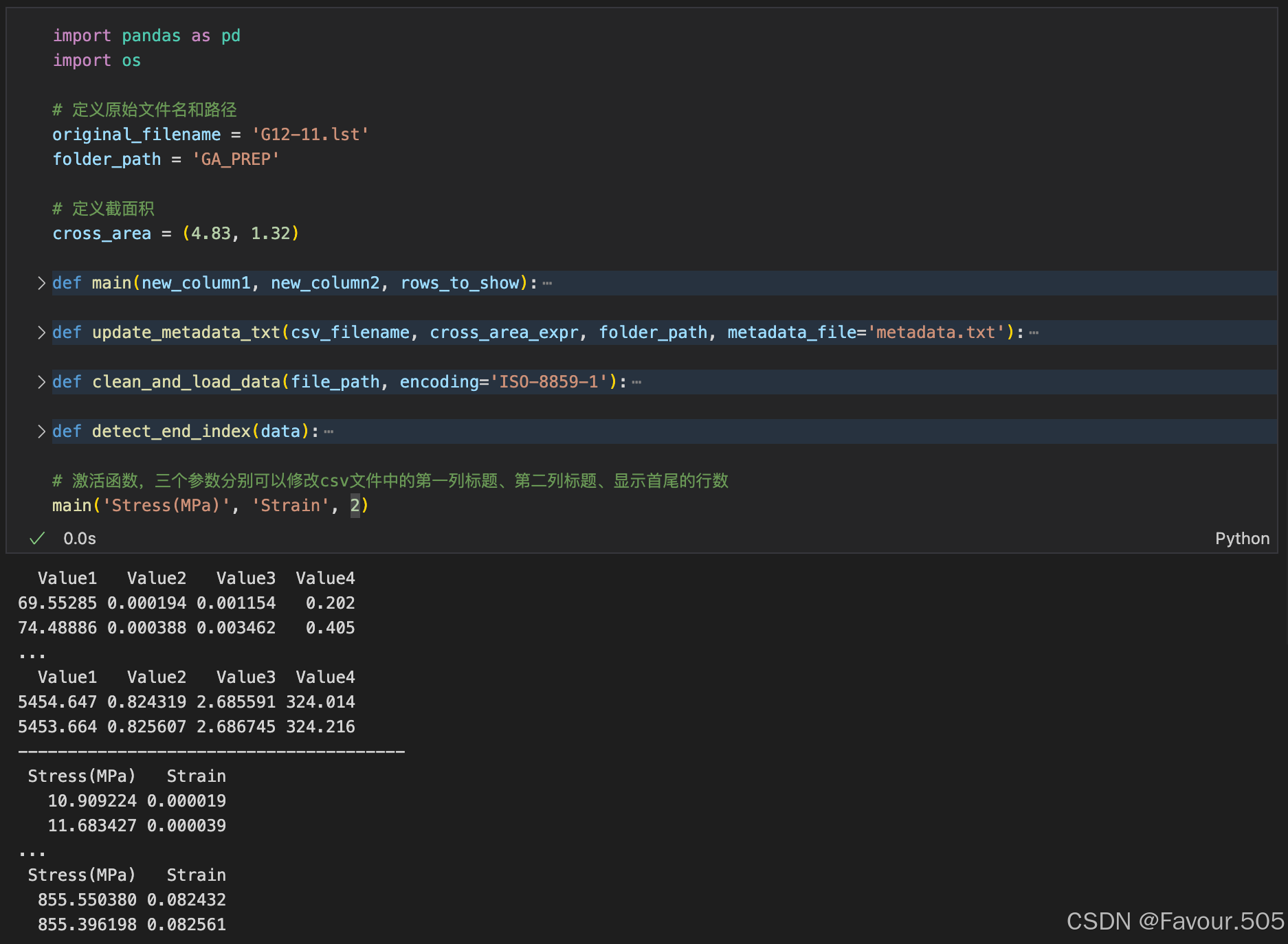
参数介绍
- folder_path后的两个引号中输入你不同试验数据的小文件夹名称,我以GA_PREP示例(注意文件名中最好不要有斜杠,建议全部使用中英文和下划线)
- original_filename后的两个引号中输入GA_PREP文件夹下的lst文件名称(记得要把.lst的后缀加上),我以G12-11.lst示例
- cross_area后的括号中逗号前后分别输入试样截面的高度和厚度(单位mm,顺序无所谓,如果只记住了面积,可以逗号前输入面积/mm^2,逗号后输入1)
- 参考前面的代码示例图片,第二个函数后面的.txt文件是一个存储你已处理数据的文件,默认保存在你的folder_path里
这个文件可以帮助你记录自己是否已处理过该文件,处理时使用的面积是否正确
txt中可以显示你已处理的数据文件名称、你输入的面积、这个文件对应的抗拉强度(最大值)
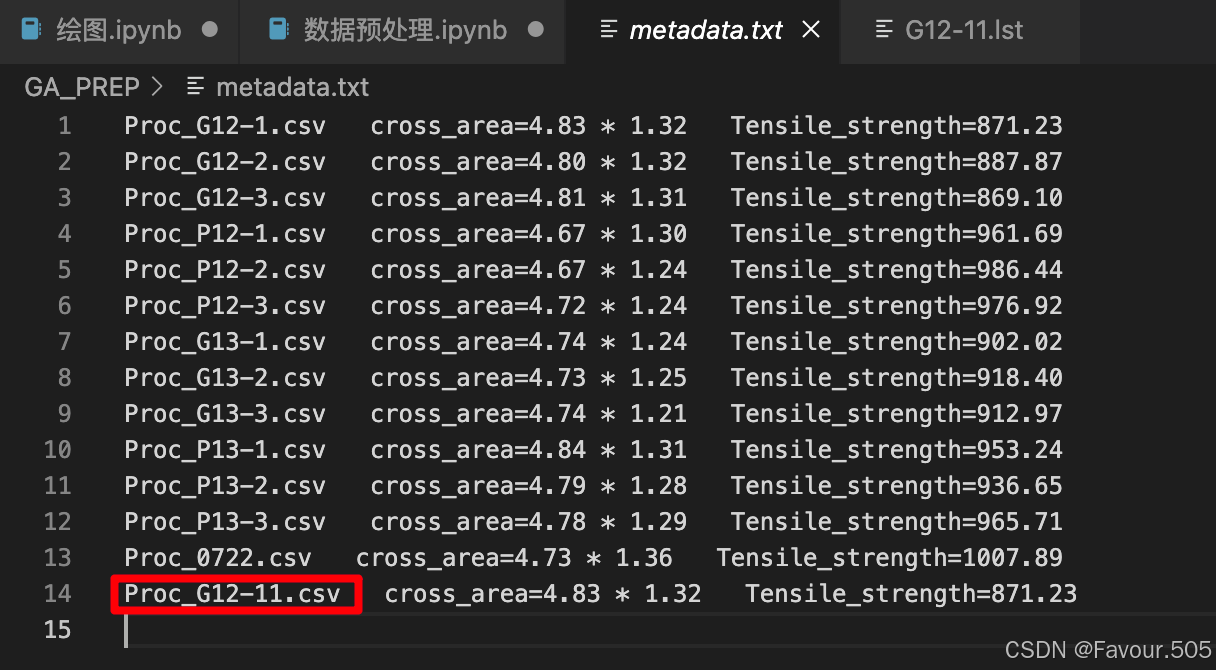
如果发现面积输错了,也不用担心,不改动original_filename,修改cross_area,重复运行代码可以替换掉txt中错误的cross_area值(不是最新处理的文件也可以替换) - 主函数部分的
main(‘Stress(MPa)’, ‘Strain’, 2)
‘Stress(MPa)’, 'Strain’可以分别修改保存的csv文件第一列与第二列的标题
2可以修改显示的行数(用于观察处理后的数据是否合理,改成几就是显示首尾几行)
前两个参数不建议修改
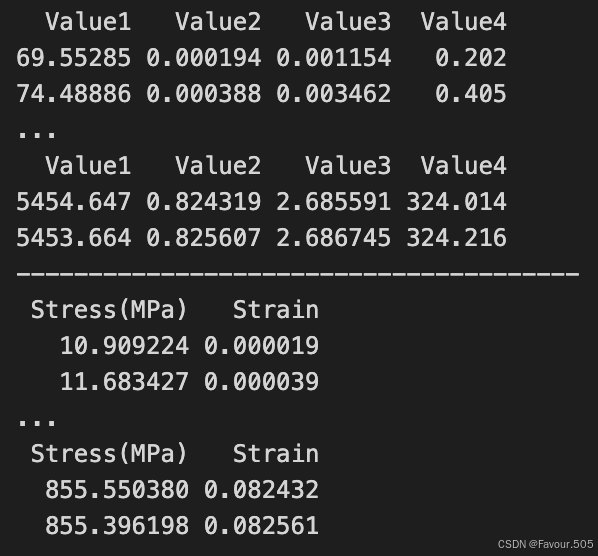
- 运行完代码后将在folder_path路径下出现一个metadata.txt文件,一个Proc_G12-11.csv文件,接着进行下一步即可
- 如果发现运行代码后显示的首尾值不合理(即上图显示的数据不合理,一般不会),可以查看Proc_G12-11.csv文件,如果这个文件里的数据看起来也不对,可以沿着本文最开始lst文件初始处理步骤在Excel中自行处理,做一个一个只有两列的表格,表格第一行分别为Stress(MPa)、Strain,如下图
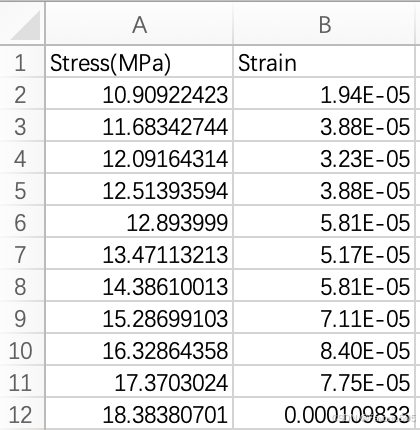
将这个文件另存为csv文件,路径与folder_path保持一致(请注意一定要选择逗号分隔这个选项)
这样就可以在VSC中看到这个文件了(用这个替代Proc_G12-11.csv)
数据预处理部分代码如下
import pandas as pd
import os
# 定义原始文件名和路径
original_filename = 'G12-11.lst'
folder_path = 'GA_PREP'
# 定义截面积
cross_area = (4.83, 1.32)
def main(new_column1, new_column2, rows_to_show):
# 创建新文件名
new_filename = f'Proc_{original_filename.replace(".lst", ".csv")}'
# 读取并清理数据
data = clean_and_load_data(f'{folder_path}/{original_filename}')
# 寻找结束索引
end_index = detect_end_index(data)
# 读取需要的行和列
selected_data = data.iloc[:end_index]
# 显示该表首尾rows_to_show列
print(selected_data.head(rows_to_show).to_string(index=False) + "\n...\n" + selected_data.tail(rows_to_show).to_string(index=False))
# 对数据进行转换
processed_data = pd.DataFrame()
processed_data[new_column1] = selected_data.iloc[:, 0] / (cross_area[0] * cross_area[1]) # 对第一列数据进行转换并命名
processed_data[new_column2] = selected_data.iloc[:, 1] / 10 # 对第二列数据进行转换并命名
print('---------------------------------------')
# 保存为 CSV 文件
processed_data.to_csv(f'{folder_path}/{new_filename}', index=False)
update_metadata_txt(new_filename, cross_area, folder_path)
print(processed_data.head(rows_to_show).to_string(index=False) + "\n...\n" + processed_data.tail(rows_to_show).to_string(index=False))
def update_metadata_txt(csv_filename, cross_area_expr, folder_path, metadata_file='metadata.txt'):
"""
更新 metadata.txt 文件中的记录。
:param csv_filename: CSV 文件名
:param cross_area_expr: 截面积的表达式
:param folder_path: 文件所在的文件夹路径
:param metadata_file: 元数据文件名
"""
cross_area_str = f'{cross_area_expr[0]:.2f} * {cross_area_expr[1]:.2f}'
data_path = os.path.join(folder_path, csv_filename)
data = pd.read_csv(data_path)
max_value = data.iloc[:, 0].max() # 假设数据已正确读取且第一列是数值类型
new_line = f'{csv_filename} cross_area={cross_area_str} Tensile_strength={max_value:.2f}\n'
# 元数据文件的完整路径
metadata_path = os.path.join(folder_path, metadata_file)
# 读取和更新元数据文件
if os.path.exists(metadata_path):
with open(metadata_path, 'r') as file:
lines = file.readlines()
updated = False
for i, line in enumerate(lines):
if line.startswith(csv_filename):
lines[i] = new_line
updated = True
break
if not updated:
lines.append(new_line)
with open(metadata_path, 'w') as file:
file.writelines(lines)
else:
with open(metadata_path, 'w') as file:
file.write(new_line)
def clean_and_load_data(file_path, encoding='ISO-8859-1'):
"""
读取并清理数据文件。
:param file_path: 文件路径
:param encoding: 文件编码
:return: 清理后的数据 DataFrame
"""
with open(file_path, 'r', encoding=encoding) as file:
lines = file.readlines()
cleaned_lines = []
for line in lines:
parts = line.strip().split(',')
if len(parts) == 4 and not all(float(part) == 0.0 for part in parts):
cleaned_lines.append(line)
if cleaned_lines:
from io import StringIO
data = pd.read_csv(StringIO(''.join(cleaned_lines)), header=None)
data.columns = ['Value1', 'Value2', 'Value3', 'Value4']
else:
data = pd.DataFrame(columns=['Value1', 'Value2', 'Value3', 'Value4'])
return data
def detect_end_index(data):
"""
寻找数据中的结束点索引。
:param data: 输入数据 DataFrame
:return: 结束点索引
"""
end_index = None
if len(data) > 0:
previous_value = data.iloc[1, 1] # 直接访问第二列
for i in range(len(data) - 100, len(data)):
current_value = data.iloc[i, 1] # 直接访问第二列
if current_value > 1.5 * previous_value:
end_index = i
break
previous_value = current_value
return end_index
# 激活函数,三个参数分别可以修改csv文件中的第一列标题、第二列标题、显示首尾的行数
main('Stress(MPa)', 'Strain', 2)
绘图部分
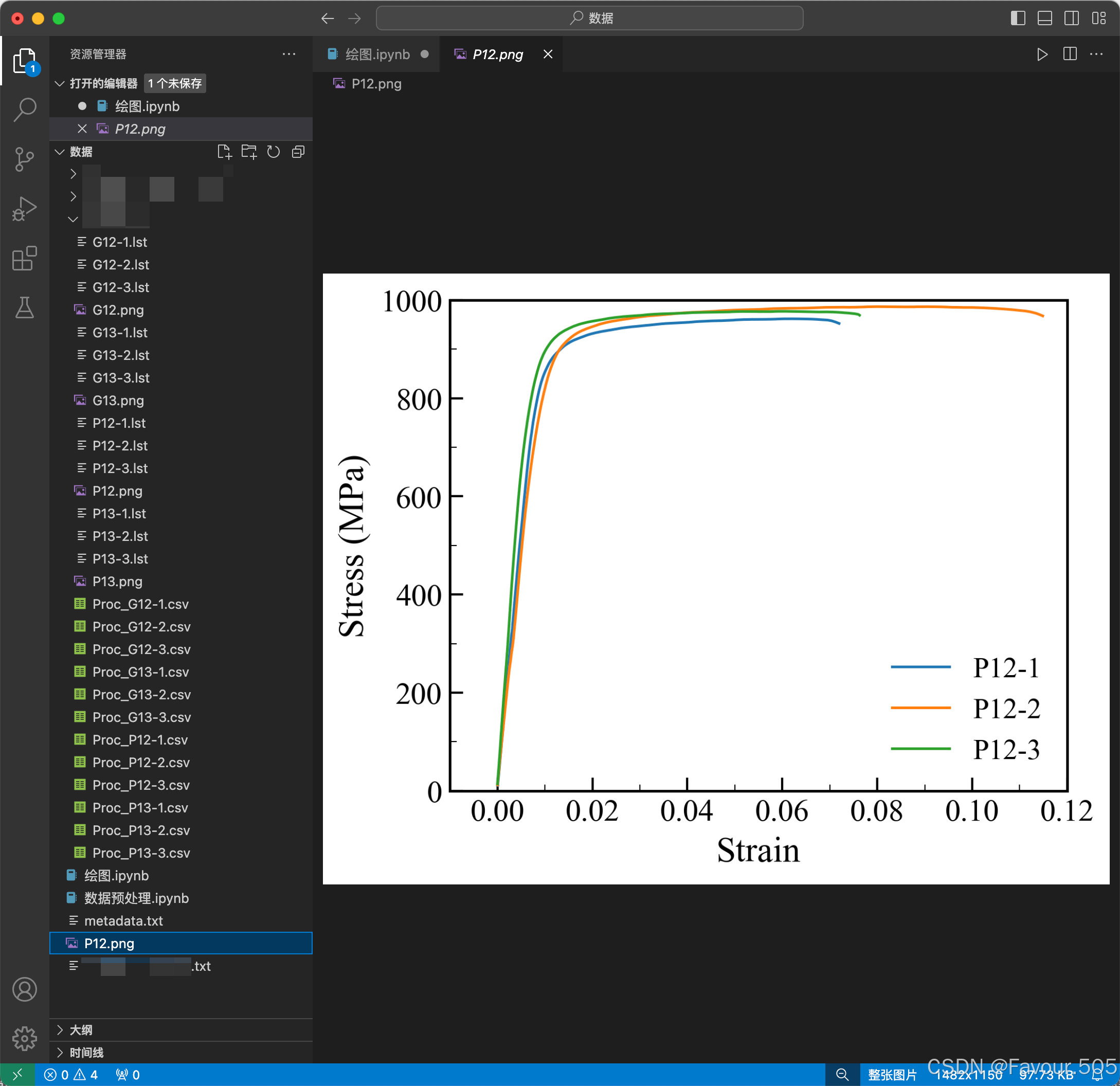
做完数据预处理部分后,文件夹中的csv文件就是我们绘图的数据文件(本例中为Proc_G12-11.csv)
本代码可以实现多条曲线绘制在同一张图上
曲线绘制时,可以选择是否进行绘图计算(可以得到弹性模量、屈服强度、抗拉强度、延伸率),本代码可以将曲线的屈服强度等信息汇总到表格中
- 确保csv文件保存在正确路径(csv文件应该保存在代码所在文件夹目录下的一个子文件夹)
- 将代码复制进VSC并进行def函数折叠后示意图如下
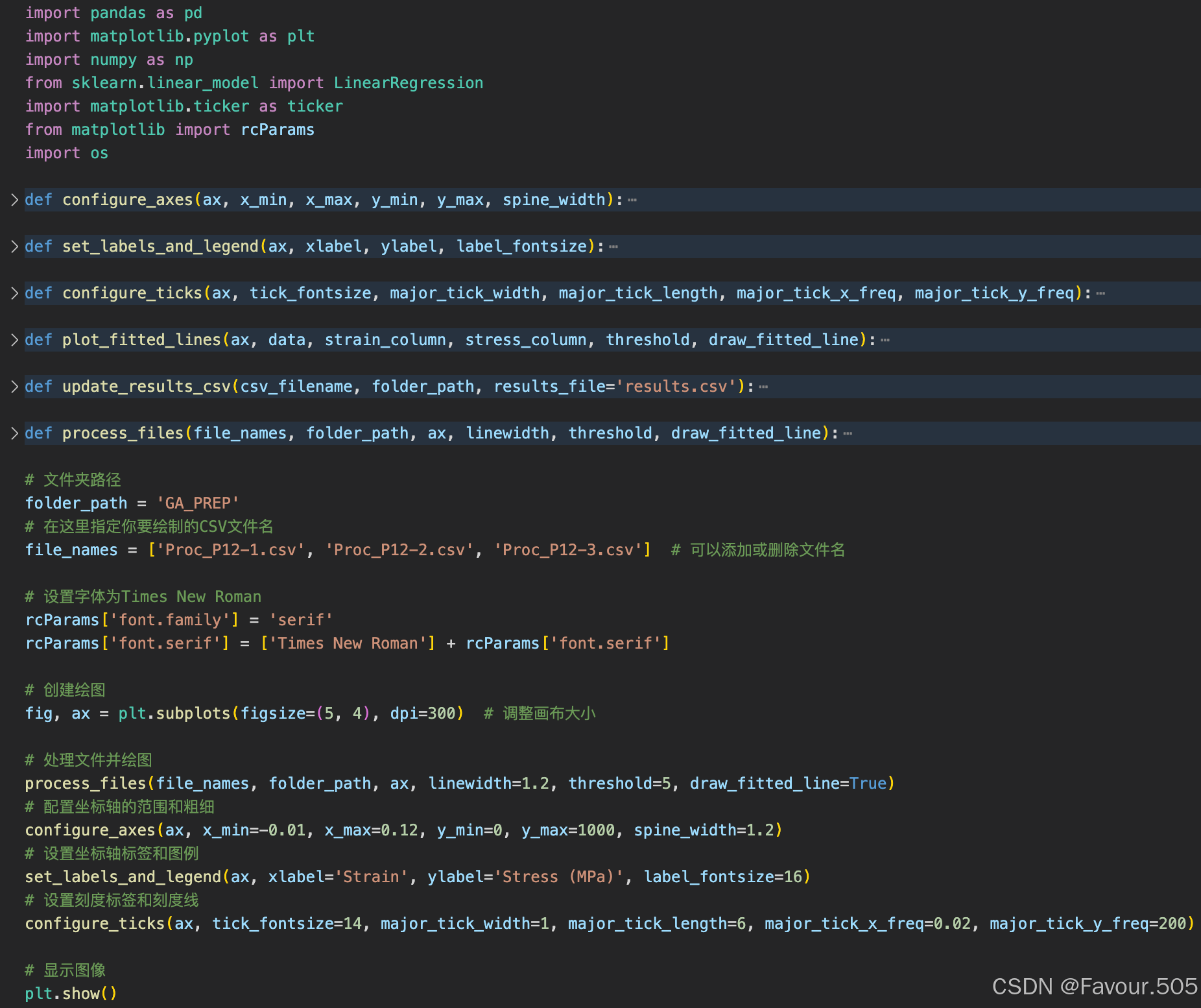
参数介绍
- folder_path、file_names与数据预处理部分相同,分别是路径和文件名称,请注意这里的文件名称要用预处理以后的csv文件名称,可以添加或者删除文件名称,以同时绘制多条或单条曲线
请注意在添加或删除文件名称时使用英文引号和英文逗号 - 设置字体部分
第一行保证字体的主要类型为衬线字体,详情可搜索Matplotlib 支持的字体类型
第二行保证字体为Times New Roman - 创建绘图部分
figsize=(5, 4)表示这是一个5*4比例的画布,可以更改
dip=300是画布像素,一般300就够用了 - process_files函数
linewidth=1.2:调整数字改变拉伸曲线的线宽
threshold=5:调整数字改变拟合弹性段直线的容差
draw_fitted_line=True:开启绘制拟合弹性段直线的功能(关闭为=False)
功能开启时,红线用于计算屈服强度(放大可以看到一个红线与曲线相交的绿色点,用于确认屈服强度对应的点位置正确),蓝线用于计算延伸率
举一个单个数据的例子
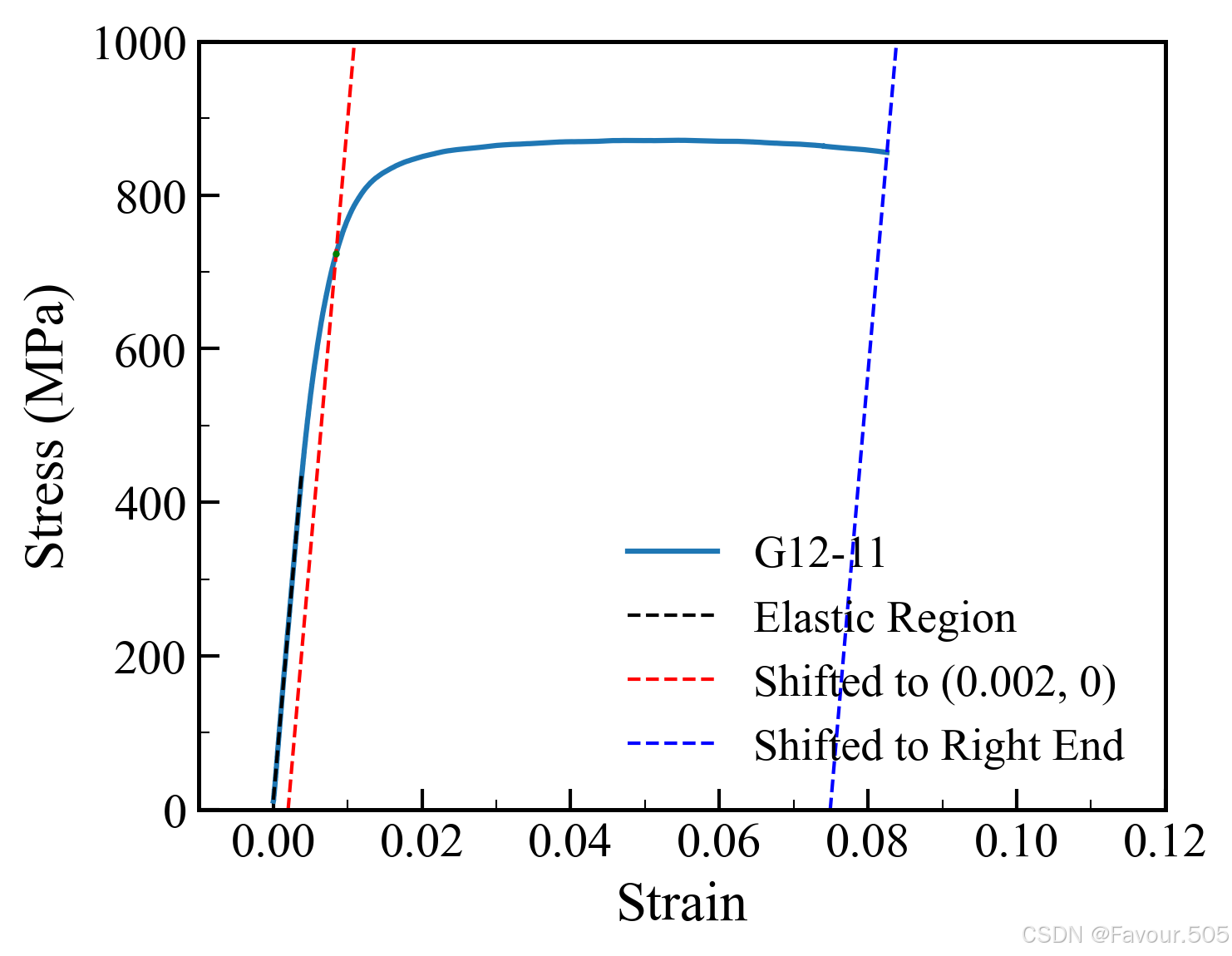
threshold=5时,可以看到蓝色曲线部分有一条黑色直线
这条线就是拟合弹性段的直线,提高threshold的数值可以让这个直线误差变大
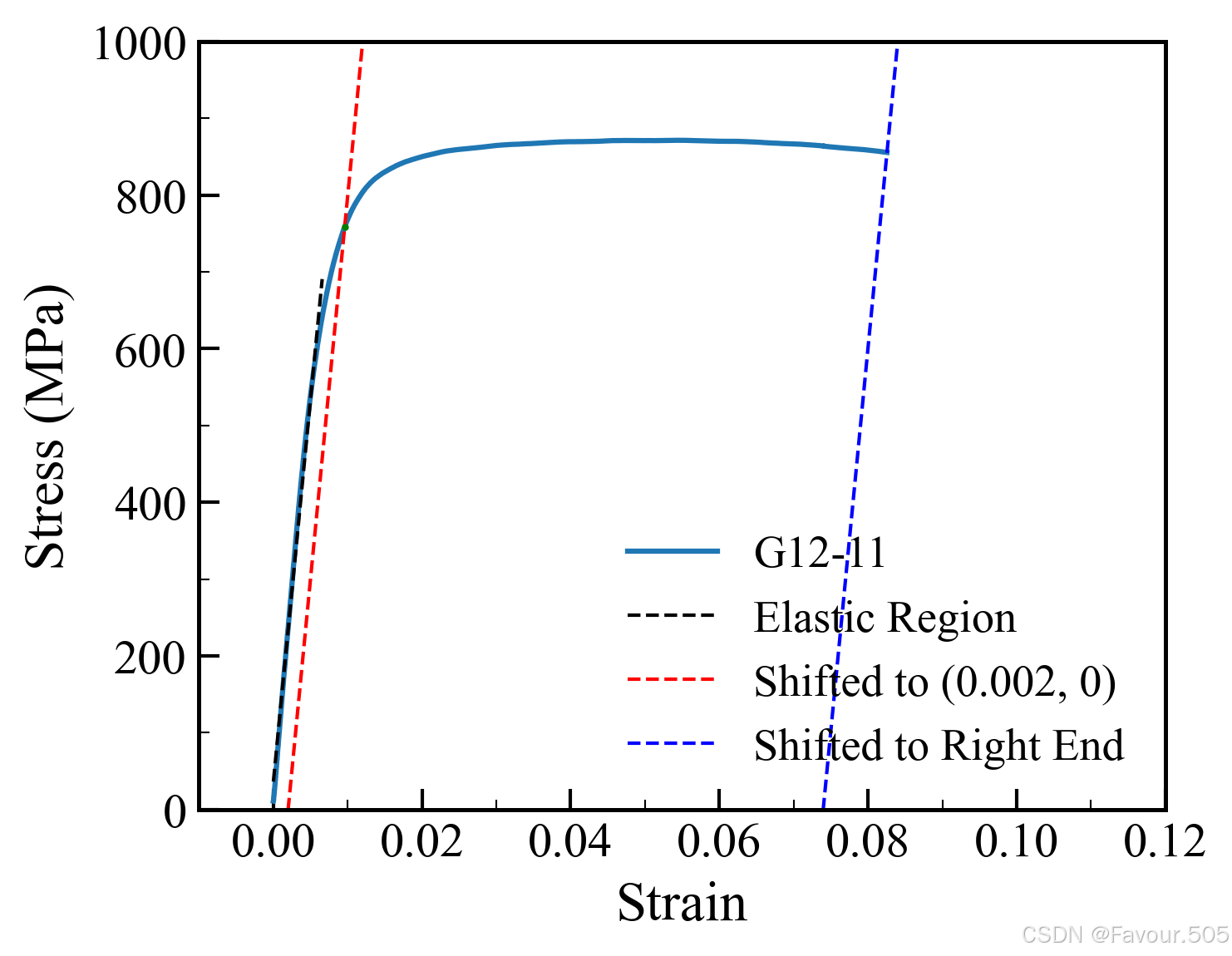
threshold=50时,可以看到黑色直线已经略微偏移了真正的弹性阶段,此时计算出的屈服强度和延伸率会不准
(可以理解为数字越大,对弹性段成正比的精度要求越低。可以通过更改数字,观察黑色直线在蓝色曲线上的位置来选择自己想要的弹性段)
- configure_axes函数
x_min=-0.01:调整数字改变x轴最小值
x_max=0.12:调整数字改变x轴最大值
y_min=0:调整数字改变y轴最小值
y_max=1000:调整数字改变y轴最大值
spine_width=1.2:调整数字改变坐标轴边框宽度 - set_labels_and_legend函数(标签用中文可能报错或无法显示)
xlabel=‘Strain’:改变引号中内容可以调整x轴标签
ylabel=‘Stress (MPa)’:改变引号中内容可以调整y轴标签
label_fontsize=16:调整数字改变标签字号 - configure_ticks函数
tick_fontsize=14:调整数字改变刻度标签(数字)字号
major_tick_width=1:调整数字改变主刻度线粗细(最好比坐标轴宽度spine_width窄),已经默认设置了副刻度线粗细为主刻度线一半(调整查看configure_ticks函数中的调整次要刻度线这一行的width)
major_tick_length=6:调整数字改变主刻度线高度,已经默认设置了副刻度线粗细为主刻度线一半(调整查看configure_ticks函数中的调整次要刻度线这一行的length)
major_tick_x_freq=0.02:调整数字改变x轴的主刻度线间隔,已经默认设置了副刻度线间隔为主刻度线一半(调整查看configure_ticks函数中的设置次要刻度线的频率这一行)
major_tick_y_freq=200:调整数字改变y轴的主刻度线间隔,已经默认设置了副刻度线间隔为主刻度线一半(调整查看configure_ticks函数中的设置次要刻度线的频率这一行) - 保存图片
可以选择直接在VSC显示的图片上点保存键
也可以在plt.show()这一行上方添加一行代码
# 保存图片到当前路径
plt.savefig(f'{folder_path}/图片名称.png')
# 如果要修改保存参数
plt.savefig(f'{folder_path}/图片名称.png',
dpi=300, # 分辨率
bbox_inches='tight', # 自动调整保存的图像边界,以去除多余的空白区域,使图像内容紧密地适应图像边框
transparent=True # 背景透明,默认是False,想要白背景可以改为False
)
- 如果想调整曲线颜色(代码中补充了一个调整线形的,原理类似)
展开process_files函数
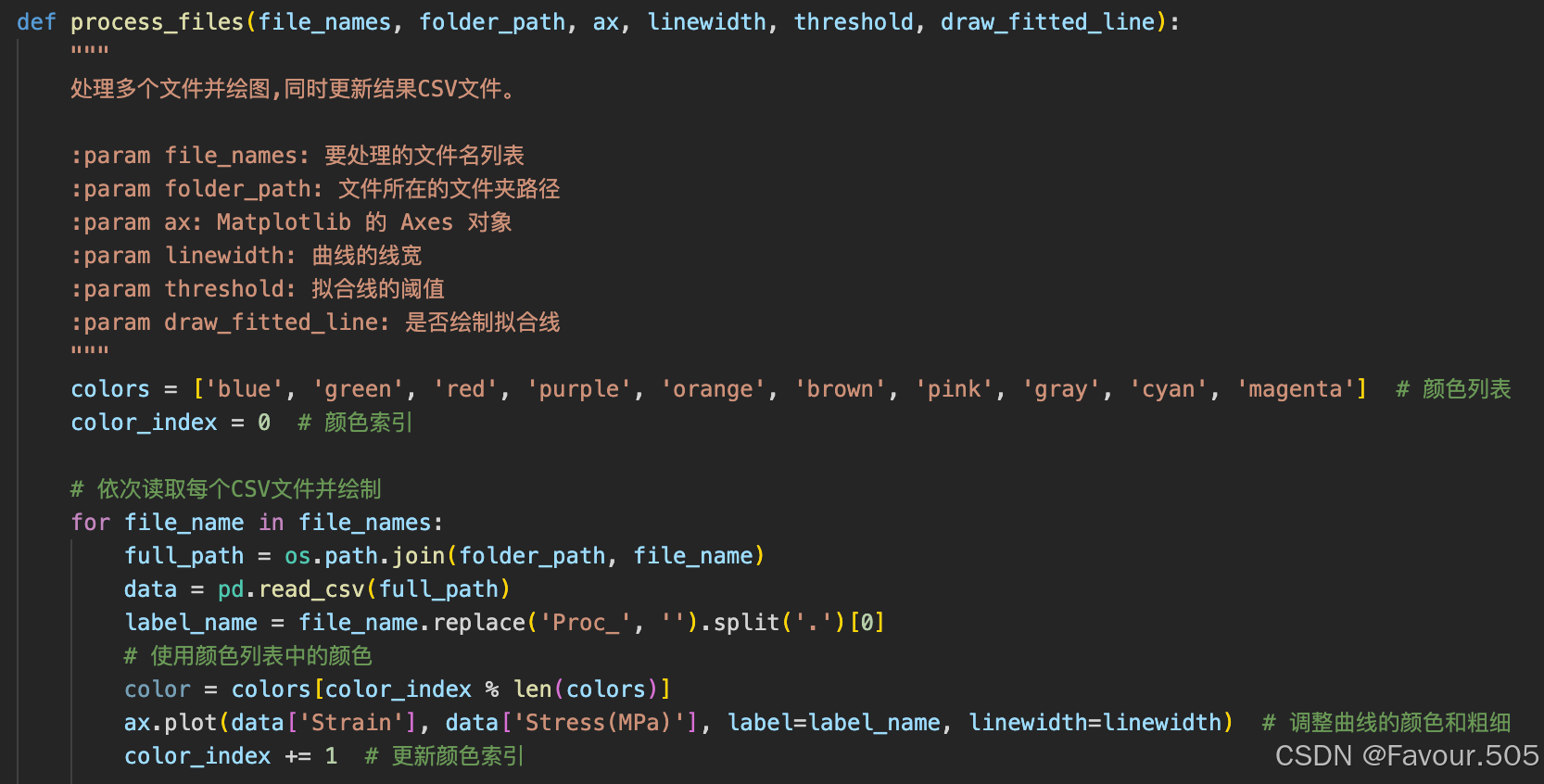
可以看到有一行colors的代码,可以依次修改blue、green等颜色来调整曲线的颜色(依次对应主函数中file_names的顺序),这个颜色可以是16进制的颜色,可参考Python 颜色代码大全
现在尚并未使用这行colors,所以绘图颜色是默认颜色
如果想使用自定义颜色,请在ax.plot这一行的括号内尾部添加代码, color=color,即将这一行改为
ax.plot(data['Strain'], data['Stress(MPa)'], label=label_name, linewidth=linewidth, color=color) # 调整曲线的颜色和粗细
- 如果想修改图例位置
展开set_labels_and_legend函数
legend = ax.legend这一行代码的内容可以对图例位置进行修改
可参考csdn博客:Python绘图中如何设置图例位置
或参考官方函数说明:官方文档
修改完参数,运行这个代码,VSC将展示曲线图片
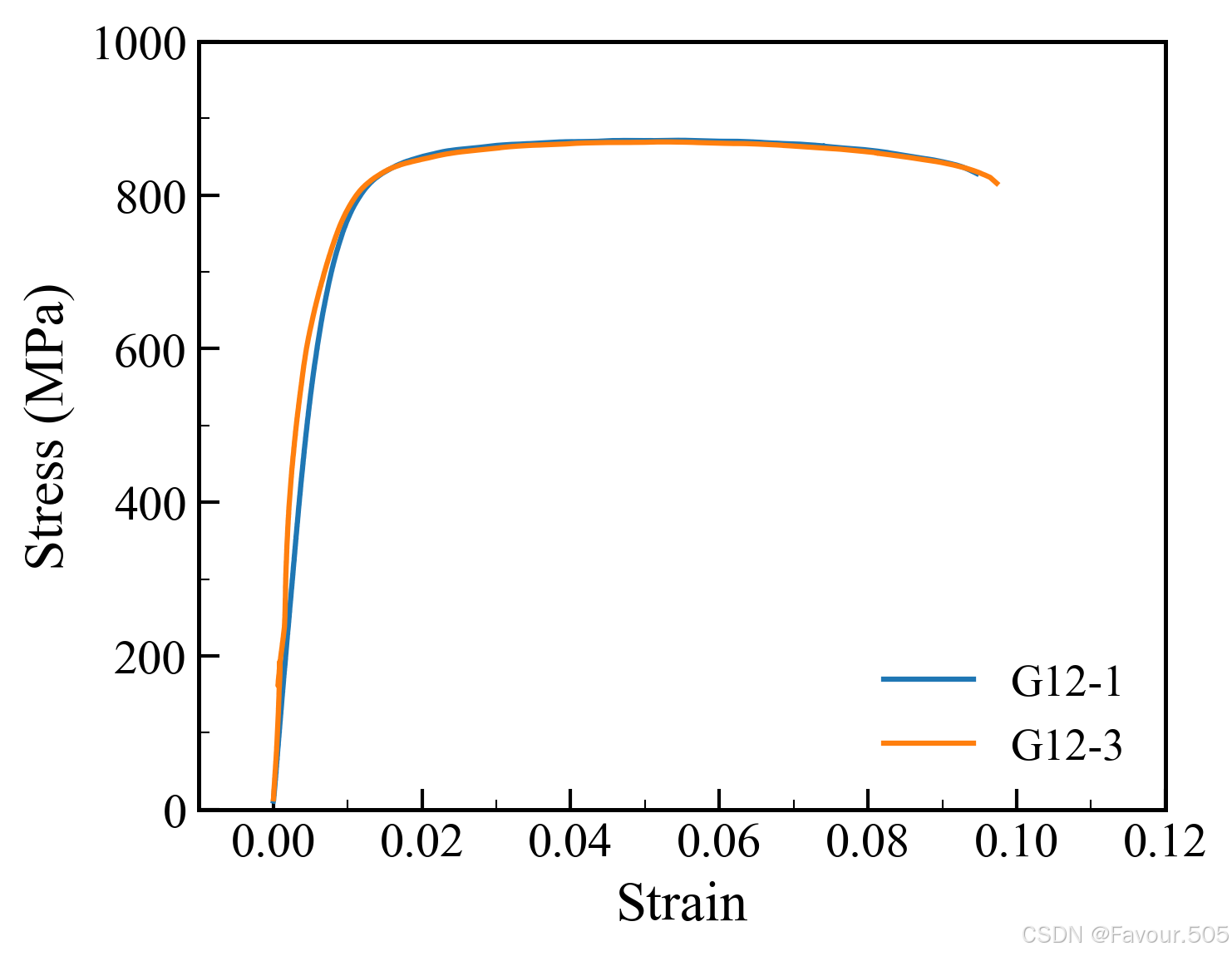
如果将draw_fitted_line设置为True,VSC将展示带拟合直线的曲线图片(建议设置为True时只输入一条曲线,以便于进行合适的threshold调整,得到准确的屈服强度等数据)
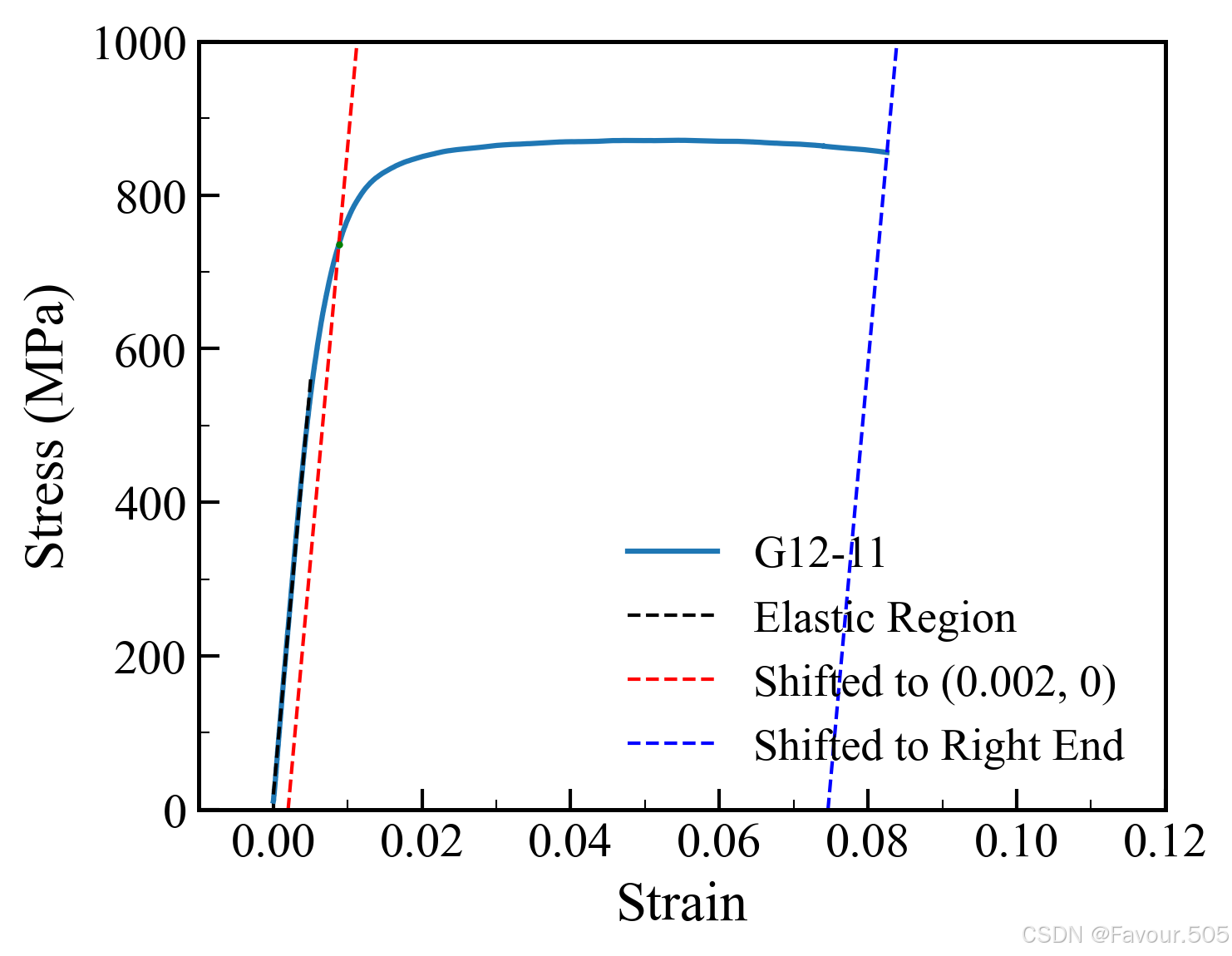
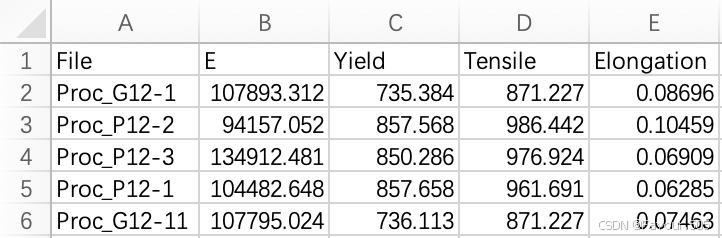
同时,代码会自动在folder_path路径下生成一个results.csv的文件,记录曲线数据,使用Excel打开,即可得到表格(每次处理的新数据均会记录在里面,对老数据的更改会更新表格的值)
绘图部分代码如下
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.ticker as ticker
from matplotlib import rcParams
import os
def configure_axes(ax, x_min, x_max, y_min, y_max, spine_width):
"""配置坐标轴的范围和粗细"""
ax.set_xlim(x_min, x_max) # 设置横坐标范围
ax.set_ylim(y_min, y_max) # 设置纵坐标范围
for spine in ax.spines.values():
spine.set_linewidth(spine_width) # 调整坐标轴的粗细
def set_labels_and_legend(ax, xlabel, ylabel, label_fontsize):
"""设置坐标轴标签和图例"""
ax.set_xlabel(xlabel, fontsize=label_fontsize, fontname='Times New Roman')
ax.set_ylabel(ylabel, fontsize=label_fontsize, fontname='Times New Roman')
legend = ax.legend(prop={'family': 'Times New Roman', 'size': 13}, # 图例的字体属性
loc='lower right', # 调整图例的位置
bbox_to_anchor=(1, 0), # 将图例固定在右下角
frameon=False # 是否在图例周围绘制框架(True 或 False)
)
return legend
def configure_ticks(ax, tick_fontsize, major_tick_width, major_tick_length, major_tick_x_freq, major_tick_y_freq):
"""设置刻度标签和刻度线"""
plt.xticks(fontsize=tick_fontsize, fontname='Times New Roman')
plt.yticks(fontsize=tick_fontsize, fontname='Times New Roman')
ax.tick_params(axis='both', direction='in', length=major_tick_length, width=major_tick_width) # 调整主要刻度线
ax.minorticks_on()
ax.tick_params(axis='both', which='minor', direction='in', length=major_tick_length / 2, width=major_tick_width / 2) # 调整次要刻度线
ax.xaxis.set_major_locator(ticker.MultipleLocator(major_tick_x_freq)) # 设置主要刻度线的频率
ax.yaxis.set_major_locator(ticker.MultipleLocator(major_tick_y_freq)) # 设置主要刻度线的频率
ax.xaxis.set_minor_locator(ticker.MultipleLocator(major_tick_x_freq / 2)) # 设置次要刻度线的频率
ax.yaxis.set_minor_locator(ticker.MultipleLocator(major_tick_y_freq / 2)) # 设置次要刻度线的频率
def plot_fitted_lines(ax, data, strain_column, stress_column, threshold, draw_fitted_line):
"""绘制拟合直线,并进行平移和交点计算"""
if not draw_fitted_line:
return None, None, None, None
# 找到弹性段范围
X = data[strain_column].values.reshape(-1, 1)
y = data[stress_column].values
def is_within_threshold(start, end):
model = LinearRegression()
model.fit(X[start:end], y[start:end])
y_pred = model.predict(X[start:end+1])
return abs(y_pred[-1] - y[end]) <= threshold
low, high = 2, len(X)
while low < high:
mid = (low + high) // 2
if is_within_threshold(0, mid):
low = mid + 1
else:
high = mid
end_index = low - 1
model = LinearRegression()
model.fit(X[:end_index], y[:end_index])
slope = model.coef_[0]
intercept = model.intercept_
# 绘制弹性段拟合线
x_fit = np.linspace(X[0], X[end_index - 1], 500)
y_fit = slope * x_fit + intercept
ax.plot(x_fit, y_fit, color='black', linestyle='--', linewidth=1, label='Elastic Region')
def draw_line(slope, x0, y0, x_range):
"""绘制经过指定点 (x0, y0) 的直线"""
x_vals = np.linspace(x_range[0], x_range[1], 500)
y_vals = slope * (x_vals - x0) + y0
return x_vals, y_vals
# 第一次平移到经过点 (x=0.002, y=0)
x_shifted, y_shifted = draw_line(slope, x0=0.002, y0=0, x_range=[0, 0.1])
ax.plot(x_shifted, y_shifted, color='red', linestyle='--', linewidth=1, label='Shifted to (0.002, 0)')
# 找到红色直线和曲线的最近交点(屈服强度)
min_distance = float('inf')
yield_strength = None
yield_strength_x = None # 用于记录对应的x坐标
for x_orig, y_orig in zip(X.flatten(), y):
y_shifted_point = slope * (x_orig - 0.002) + 0
distance = abs(y_shifted_point - y_orig)
if distance < min_distance:
min_distance = distance
yield_strength = y_orig
yield_strength_x = x_orig
print(f'Yield Strength (at x=0.002): {yield_strength}')
# 添加标记点
ax.plot(yield_strength_x, yield_strength, marker='o', markersize=1, color='green')
# 第二次平移到经过曲线的最右端点
x_shifted, y_shifted = draw_line(slope, x0=X[-1][0], y0=y[-1], x_range=[0, 0.1])
ax.plot(x_shifted, y_shifted, color='blue', linestyle='--', linewidth=1, label='Shifted to Right End')
# 找到延伸率(y=0时的x坐标)
elongation = (-y[-1] / slope) + X[-1][0]
print(f'Elongation (at y=0): {elongation}')
return slope, yield_strength, elongation, data.iloc[:, 0].max()
def process_files(file_names, folder_path, ax, linewidth, threshold, draw_fitted_line):
"""
处理多个文件并绘图,同时更新结果CSV文件。
:param file_names: 要处理的文件名列表
:param folder_path: 文件所在的文件夹路径
:param ax: Matplotlib 的 Axes 对象
:param linewidth: 曲线的线宽
:param threshold: 拟合线的阈值
:param draw_fitted_line: 是否绘制拟合线
"""
colors = ['blue', 'green', 'red', 'purple', 'orange', 'brown', 'pink', 'gray', 'cyan', 'magenta'] # 颜色列表
color_index = 0 # 颜色索引
linestyles = ['--', '--', '-', '-'] # 线形列表
linestyle_index = 0 # 线形索引
results_path = os.path.join(folder_path, 'results.csv')
if os.path.exists(results_path):
results_df = pd.read_csv(results_path)
else:
results_df = pd.DataFrame(columns=['File', 'E', 'Yield', 'Tensile', 'Elongation'])
# 依次读取每个CSV文件并绘制
for file_name in file_names:
full_path = os.path.join(folder_path, file_name)
data = pd.read_csv(full_path)
label_name = file_name.replace('Proc_', '').split('.csv')[0]
# 使用颜色列表中的颜色
color = colors[color_index % len(colors)]
# 使用线形列表中的线形
linestyle = linestyles[linestyle_index % len(linestyles)]
ax.plot(data['Strain'], data['Stress(MPa)'], label=label_name, linewidth=linewidth) # 调整曲线的颜色和粗细
color_index += 1 # 更新颜色索引
linestyle_index += 1 # 更新线形索引
# 绘制拟合直线并计算所需的值
slope, yield_strength, elongation, tensile_strength = plot_fitted_lines(ax, data, 'Strain', 'Stress(MPa)', threshold, draw_fitted_line)
if slope is not None:
file_name_without_extension = file_name.replace('.csv', '')
new_row = {
'File': file_name_without_extension,
'E': round(slope, 3),
'Yield': round(yield_strength, 3),
'Tensile': round(tensile_strength, 3),
'Elongation': round(elongation, 5)
}
idx = results_df.index[results_df['File'] == file_name_without_extension].tolist()
if idx:
for i in idx:
results_df.loc[i] = new_row
else:
results_df = results_df.append(new_row, ignore_index=True)
results_df.to_csv(results_path, index=False)
# 文件夹路径
folder_path = 'GA_PREP'
# 在这里指定你要绘制的CSV文件名
file_names = ['Proc_G12-1.csv'] # 可以添加或删除文件名
# 设置字体为Times New Roman
rcParams['font.family'] = 'serif'
rcParams['font.serif'] = ['Times New Roman'] + rcParams['font.serif']
# 创建绘图
fig, ax = plt.subplots(figsize=(5, 4), dpi=300) # 调整画布大小
# 处理文件并绘图
process_files(file_names, folder_path, ax, linewidth=1.5, threshold=20, draw_fitted_line=True)
# 配置坐标轴的范围和粗细
configure_axes(ax, x_min=-0.01, x_max=0.12, y_min=0, y_max=1000, spine_width=1.2)
# 设置坐标轴标签和图例
set_labels_and_legend(ax, xlabel='Strain', ylabel='Stress (MPa)', label_fontsize=16)
# 设置刻度标签和刻度线
configure_ticks(ax, tick_fontsize=14, major_tick_width=1, major_tick_length=6, major_tick_x_freq=0.02, major_tick_y_freq=200)
# 显示图像
plt.show()
有任何疑问,欢迎讨论~共同进步~


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









