






Python 语法和算法模板
之前准备比赛整理的笔记,只拿了重庆赛区省一等奖。我是一个月学完的,准备的非常仓促,笔记中有很多算法和知识点没有弄明白,写出来同时让大家批评指正。
输入
split()方法的含义:
Python split() 通过指定分隔符对字符串进行切片。通常用于输入时和map()函数一起使用
m, n = map(int,input().split()): 使用split()函数将输入的字符串按照空格进行分割。如果用户输入的是"10 20",那么split()函数将返回一个包含两个字符串的列表,即['10', '20']
输出
join()方法:
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
用法:str.join(sequence)
参数:
- sequence – 要连接的元素序列,可以是列表、元组、字符串、字典等可迭代对象
保留n位的小数
"%.nf" %[变量]【四舍五入】
a = 2.345566
print("%4f" %a) # 2.3456
format函数 【四舍五入】
a = 2.345566
print("{:.4f}".format(a)) # 2.3456
直接截断,【不进行四舍五入】
先放大指定倍数,后取整,后再除以指定倍数
原理为:扩大指定倍数后,使用int就可以截断整数(没有四舍五入),再除以相应位数得到小数
-
保留两位有效数字:先×100,后int,后÷100:
a = 2.345566 c = int(a * 100) / 100 print(c) # 2.34 -
保留三位小数:先×1000,后int,后÷1000:
a = 2.345566 c = int(a * 1000) / 1000 print(c) # 2.345
循环结构
while循环
辗转相除法求最大公约数:
我们想求两个数
a
和
b
a和b
a和b的最大公约数
(
a
,
b
)
(a,b)
(a,b)。
a
/
b
=
q
.
.
.
.
.
.
r
a/b=q......r
a/b=q......r,将其改写为GCD(a,b)=GCD(b,r),通过不断重复最终得到余数为0时,所得到的被除数就是最大公约数。所以这个算法的基本思想是通过反复用较小数去除较大数,直到余数为零。这时,被除数就是最大公约数。
GCD(Greatest Common Divisor)最大公约数
代码:
a = int(input())
b = int(input())
r = a%b #先求余数
while r != 0:
a = b
b = r
r= a%b
print("gcd=",b)
基础数据结构
字符串
ord()和chr()两个函数作用的描述:
ord() 和 chr() 是 Python 中用于处理字符和其 ASCII 码之间转换的两个内置函数。
ord(charachteristic)用于获取一个字符的ASCII码print(ord('A')) # 输出 65 print(ord('a')) # 输出 97
2. `chr(ascii)`用于获取一个ASCII码对应的字符
```python
print(chr(65)) # 输出 'A'
print(chr(97)) # 输出 'a'
计数count()
假设s是一个字符串,s.count(s[i])表示计算字符s[i]在该字符串中出现的次数
s = "leetcode"
print(s.count('e')) #输出为3,即e在字符串中出现了3次
链表
链表是一个随时删除,随时插入的数据结构
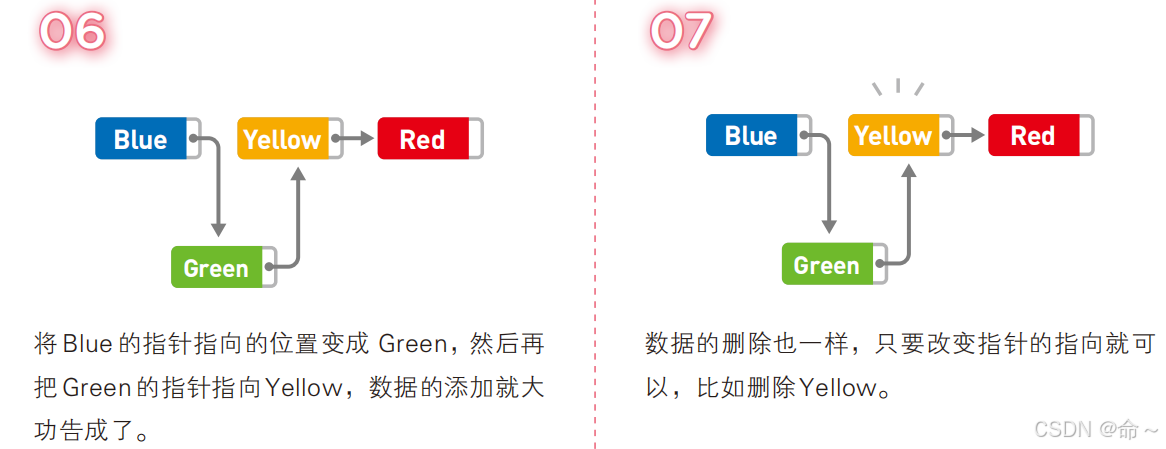
python中链表使用list()函数就可以完成
添加元素:
a.expend(x):在a的末尾添加可迭代元素(如列表)
a.insert(idx,x):在a的下标为idx位置添加x
删除元素:
del a[idx]:删除a[idx]
a.pop(idx):删除并返回a[idx]
a.remove(x):删除a中的第一个x
查找元素:
a.index(x,start,stop):在下标[start,stop]中第一次出现的位置
栈
python的栈同样可以用list()实现
添加元素:a.append(x)
获取栈顶元素:a[-1]
去除栈顶元素:a.pop()
队列
先进先出的数据结构
-
每次添加的元素放入队尾,每次取出的元素是队首
-
可以用List模拟,但是**
deque效率更高,即使用双端队列的方式**
from collections import deque
a = deque([1, 2, 3, 4, 5])
a.append(6) #队尾添加元素
a.appendleft(0) #队首添加元素
print("a1 = ",*a) # a1 = 0 1 2 3 4 5 6 这样就只会打印数字,而不会把deque也打印出来
a.popleft() #移去并返回队首元素
print("a2 = ",a)
a.pop() #移去并返回队尾元素
print("a3 = ",a)
a.extend([7, 8, 9])
print("a4 = ",a)
a.remove(9)
print("a5 = ",a)
列表
将一段字符串逐个转换为数字,并使用列表保存起来
#将字符串转换为列表
digits = []
for char in string:
if char.isdigit():
digits.append(int(char))
print(digits)
函数内部修改列表
在 Python 中,当你在函数内部修改一个列表(或其他可变对象)时,不需要显式声明为全局变量。这与普通变量的行为不同。
对于普通变量,如果在函数内部给一个普通变量赋值可能会产生歧义,因为它可以被解释为引用全局变量 a,也可以被解释为创建一个新的局部变量
使用enumerate()函数获取列表的值和索引
enumerate()函数通常在需要遍历列表(或其他可迭代对象)的同时获取每个元素的索引时使用。这种情况下,它非常有用,因为它可以同时提供元素的值和对应的索引。
enumerate([start=0],sequence)
参数:
- sequence : 一个序列、迭代器或其他支持迭代对象。
- start :下标起始位置的值。
使用:
for index,value in enumerate(s): #s为字符串或者列表
...
进制转换
十进制转换为其他进制
十进制转换为二进制:bin()
十进制转换为八进制:oct()
十进制转换为十六进制: hex()
# 获取用户输入的十进制数
dec = int(input("输入数字:"))
# 转换为二进制
print("十进制数为:", dec)
print("转换为二进制为:", bin(dec))
# 转换为八进制
print("转换为八进制为:", oct(dec))
# 转换为十六进制
print("转换为十六进制为:", hex(dec))
输出结果为:
输入数字:5
十进制数为:5
转换为二进制为:0b101
转换为八进制为:0o5
转换为十六进制为:0x5
其他进制转换为十进制
使用int(number, base)
其中,number是要转换的数字,base是原始数字的进制。
例如,如果要将一个二进制数转换为十进制,可以这样做:
binary_number = '1010'
decimal_number = int(binary_number, 2)
print(decimal_number) # Output will be 10
同样,将一个十六进制转换为十进制:
hexadecimal_number = '1A'
decimal_number = int(hexadecimal_number, 16)
print(decimal_number) # Output will be 26
排序
sort()方法
语法
list.sort(key=None, reverse=False)
参数
key:这是一个可选的函数,用于指定排序时用于比较的键。例如可以在二维数组中,确定要排序的具体是第几个参数reverse:排序规则
lambda是一个匿名函数,是固定写法;x表示匿名函数的输入,可以表示列表中的一个输入
实例
# 获取列表的第二个元素
# 列表
random = [[2, 2], [3, 4], [4, 1], [1, 3]]
# 指定第二个元素排序
random.sort(key=lambda x: x[1])
# 输出类别
print('排序列表:')
print(random)
展示下匿名函数lambda是如何使用的:
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
b = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 0]
a.sort(key = lambda x: (b[x - 1], x)) #按照b的大小对a进行排序
print(a)
# 结果为 [1, 10, 2, 11, 3, 12, 4, 13, 5, 6, 7, 8, 9]
这里使用key就对列表的第二个元组进行了排序,lambda被称为匿名函数
sorted()函数
语法
list = sorted(iterable, key=None, reverse=False)
参数
iterable表示指定的序列key参数可以自定义排序规则reverse参数指定以升序(False,默认)还是降序(True)进行排序。
防止栈溢出的方法
人为设置递归深度
如果程序使用递归算法,并且递归调用的层数过多,可能会导致栈溢出。默认情况下,Python 的递归深度约为 100
import sys
sys.setrecursionlimit(1000000) # 设置递归深度
但是需要注意的是pypy3不要设置太多的递归(超过50000),否则会报错
创建多维列表的方法
下面说明两种创建多维列表方法的不同,使用第二种创建列表的方式即可
vis = [[0] * N] * N
这种方式创建的是一个包含N个相同列表的列表。这些列表实际上是同一个列表的引用,所以如果改变其中一个列表的元素,所有的列表都会被改变。
vis = [[0]*N for _ in range(N)]
这种方式创建的是一个包含N个独立列表的列表。这些列表是独立的,所以改变其中一个列表的元素不会影响其他列表。
这是一个例子来说明这两种方式的区别:
N = 3
vis1 = [[0] * N] * N
vis1[0][0] = 1
print(vis1) # 输出:[[1, 0, 0], [1, 0, 0], [1, 0, 0]]
vis2 = []
for _ in range(N):
vis2.append([0] * N)
vis2[0][0] = 1
print(vis2) # 输出:[[1, 0, 0], [0, 0, 0], [0, 0, 0]]
在这个例子中,你可以看到改变vis1的一个元素会改变所有的列表,而改变vis2的一个元素只会改变一个列表。
通常情况下,第二种方式更适合创建独立的二维列表。
前缀和
前缀和(也称为累加和)是一种常见的计算技巧,用于计算数组中某个位置之前所有元素的和。
from itertools import accumulate
#求a的前缀和
def get_presum(a):
sum_ = list(accumulate(a))
return sum_
#求区间a[l]+...+a[r]之和
def get_sum(sum_,l,r):
if l == 0:
return sum_[r]
else:
return (sum_[r] - sum_[l-1])
a = list(map(int,input().split()))
print(get_sum(get_presum,l,r) #需要具体输入l和r都分别是什么
差分算法
对于一个数组a,差分数组的定义为:diff[i] = a[i] - a[i - 1]
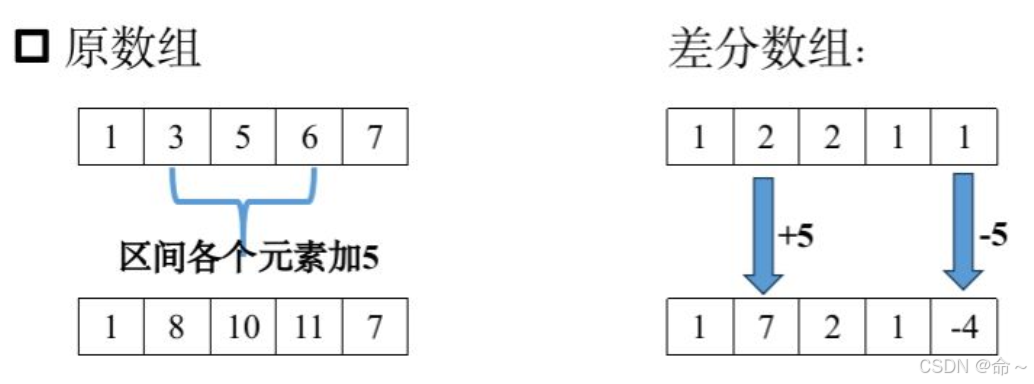
原数组执行区间[l,r]都加上x,对于差分数组而言:
diff[l] += x, diff[r + 1] -= x
使用完差分数组之后,再使用前缀和就可以得出原数组的值
贪心算法
概念
把整体问题分解成多个步骤,在每个步骤都选取当前步骤的最优方案,直至所有步骤结束;每个步骤不会影响后续步骤。
核心性质
每次采用局部最优,最终结果就全局最优
经典的贪心问题
- 石子合并问题:545题
- 分箱问题:532题
- 翻硬币问题:209题
双指针(同向扫描)
以1372为例
n,s = map(int,input().split())
a = list(map(int,input().split()))
min_len = n + 1
left,right = 0,0
tot = 0
while left < n:
while right < n and tot < s:
tot += a[right]
right += 1
if tot >= s:
min_len = min(min_len, right - left) #由于前面tot是先加了a然后再向右移位,所以这里不需要right-left+1
tot -= a[left]
left += 1
if min_len == n + 1:
min_len = 0
print(min_len)
二分法
浮点二分(用于精确求解次方)
# 以求解根号2为例
left, right = 1, 2
eps = 1e-4 #定义求解精度
while right - left > eps:
mid = (left + right) / 2
if mid**2 > 2:
right = mid
else:
left = mid
print("%2f" %mid) #保留两位小数
二分法的通用模板
def check(x):
#判断x是否合法,合法返回True,否则返回False
pass
left, right, ans = #初始化左右边界,以及答案
while left <= right:
mid = (left + right) // 2
#判断中间元素是否合法
if check(mid):
ans = mid
left = mid + 1 #或者right = mid - 1
else:
right = mid - 1 #或者left = mid + 1
print(ans)
位运算
判断二进制中有多少个1
x = int(input()) # 输入的x是内存空间为32位的整数
ans = 0
for i in range(32):
if (x >> i) & 1:
ans += 1
print(ans)
判断奇偶性
直接判断二进制的第0位是否为1或者0;相当于直接判断x&1
求出x
二进制的第i位: (x >> i) & 1
将二进制的第i位设置为1:x | (1 << i)
将二进制的第i位设置为0:x & (~(1 << i))
判断是否为2的若干次方:判断x & (x - 1)是否等于0
获取x的最低位的1:x & (-x)
-x就是对x取反加一,可以认为是x的补码
DFS 记忆化搜索
#以斐波那契数列为例
from functools import lru_cache
@lru_cache(maxsize = None)
def f(x):
if x == 0 or x == 1:
return 1
return f(x - 1) + f(x - 2)
lru的含义为:Least Recently Used,最近最少使用
图论
Floyd算法
求任意两点之间的最短路径,dp[i][j]存储的是
i
i
i 和
j
j
j 两点之间的路径长度
def floyd():
global dp
for k in range(1, n + 1):
for i in range(1, n + 1):
for j in range(1, n + 1):
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j])
排列组合:Permutations()函数
这个函数可以实现一串序列的排列组合
permutations(s,r):如果r未指定,则默认设置为序列的长度,即生成包含所有元素的全排列
对字符串进行premutations()排列组合
from itertools import permutations
a = 'abc' #对字符串进行permutations排列组合
for i in permutations(a,3):
x = ''.join(i) #join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串
print (x,end=' ')
输出结果:
abc acb bac bca cab cba
对元组进行premutations()排列组合
c = ('e','f','g')
for j in permutations(c,2):
print (j)
输出:
('e','f')
('e','g')
('f','e')
......
对列表进行
b = [1,2,3]
for j in permutations(b,3):
print (''.join('%d'%o for o in j))
输出结果:
123
132
213
...
对字典进行premutations()排列组合
需要注意的是,只能对字典的key部分进行排列组合
简单数论
快速幂
对于Python语言可以不用背快速幂模版,因为自带的pow(a, b ,mod)函数速度已经比快速幂还快了
内置pow函数用法:pow(x, y, mod)表示
x
y
%
(
m
o
d
)
x^y \% (mod)
xy%(mod),结果为整数
手写快速幂代码:
def fast_pow(a, n, mod): #表示a^n
ans = 1
a %= mod # 防止下面的a * ans 越界
while n > 0:
if n & 1 == 1:
ans = (ans * a) % mod
a = (a * a) % mod
n >>= 1
return ans
最大公因数GCD
import math
math.gcd(a, b) # 表示a和b的最大公因数
最小公倍数LCM
l c m ( a , b ) = a × b g c d ( a , b ) lcm(a, b) = \frac{a \times b}{gcd(a,b)} lcm(a,b)=gcd(a,b)a×b
import math
def lcm(a, b):
return (a * b) // math.gcd(a, b)
素数(质数)的判断
素数定义:只能被1和自己整除的正整数。其中1不是素数,2是素数
- 判断一个数n是不是素数:当 n ≤ 1 0 14 n \le 10^{14} n≤1014时,用试除法。n很大时用素数筛法
试除法:在 [ 2 , n ] [2,\sqrt n] [2,n]的范围内不断尝试
from math import sqrt
def is_prime(n):
if n <= 1:
return False # 表示不是素数
for i in range(2, int(sqrt(n)) +1):
if n % i == 0:
return False
return True
埃氏筛
逐个输出最小的素数,并筛除这个素数所有的倍数
N = 100000
bprime = [0] * N # 记录每个数字的状态
prime = [] # 记录都有哪些数字是素数
cnt = 0
def getprimes(n):
global cnt
bprime[0] = False # 表示不是素数
bprime[1] = False
for i in range(2, n + 1):
if bprime[i]:
prime.append(i)
cnt += 1
for j in range(i * 2, n + 1, i):
bprime[j] = False
for p in prime:
print(p, end=' ')
分解质因子


















 8052
8052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









