




文章目录
CCPD数据集介绍
CCPD(Chinese City Parking Dataset)数据集是一个专为车牌识别任务设计的开源数据集,它包含了大量在中国城市停车场中采集的车牌图像。这些图像涵盖了多种复杂环境,例如在不同天气条件下(如雨、雪等)、不同光照条件以及车牌的各种倾斜角度等。
CCPD数据集主要由两部分组成:CCPD2019和CCPD2020。CCPD2019主要包含普通车牌(蓝色车牌)的图像,而CCPD2020则专注于新能源车牌(绿色车牌)。
在使用CCPD数据集时,需要注意其标注方式的独特性。不同于传统数据集,CCPD并没有专门的标注文件,而是直接将标注信息嵌入到图像的文件名中。这意味着每张图像的文件名不仅包含了车牌的位置信息(如四个顶点的坐标)、倾斜角度以及车牌号码等,还包含了车牌的亮度以及模糊度等信息。
CCPD数据集标注说明
(1)官网原文描述翻译
官网原文描述
【数据集标注】
标注被嵌入在文件名中。
一个示例图像的名称为 “025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg”。每个名称可以被分割成七个字段。这些字段的解释如下:
- 区域(Area):车牌区域占整个图片面积的比率。
- 倾斜度(Tilt degree):水平倾斜度和垂直倾斜度。
- 边界框坐标(Bounding box coordinates):左上角和右下角顶点的坐标。
- 四个顶点位置(Four vertices locations):车牌四个顶点在整张图片中的精确(x,y)坐标。这些坐标从右下角顶点开始顺时针排序(右下 - 左下 - 左上 - 右上)。
- 车牌号码(License plate number):CCPD中的每张图片只有一个车牌。每个车牌号码由一个汉字、一个字母和五个字母或数字组成。有效的中国车牌由七个字符组成:省份(1个字符)、字母(1个字符)、字母+数字(5个字符)。“0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O而不是数字0。我们使用O作为“无字符”的标志,因为中国车牌字符中没有O。
省份数组(provinces)包括了中国所有省份的简称和一些特殊用途的车牌代码。
字母数组(alphabets)包括了所有可能出现在车牌第二个位置的英文字母。
字母和数字数组(ads)包括了所有可能出现在车牌后五位位置的英文字母和数字。
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W',
'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
- 亮度(Brightness):车牌区域的亮度。
- 模糊度(Blurriness):车牌区域的模糊度。
(2)图解说明

下载CCPD2020数据集
(1)谷歌云盘
Google Drive: CCPD2020.zip
(2)百度云盘
BaiduYun Drive(code: ol3j): CCPD2020.zip
CCPD2020数据格式转换为YOLO格式
(1)使用以下代码将CCPD2020数据格式转换为YOLO格式
将CCPD(Chinese City Parking Dataset)数据集中的图片和标注信息转换成YOLO(You Only Look Once)模型训练所需的格式。
# ConvertYOLOFormat.py
import os
import os.path
import re
import shutil
import cv2
from tqdm import tqdm
def listPathAllfiles(dirname):
"""
遍历指定目录下的所有文件并返回一个包含这些文件路径的列表。
"""
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
# 原始数据集的路径
data_path = "D:\\Users\\mks\\Desktop\\DeepLearningProjects\\YOLOv5-CCPD2020\\TempData\\LittleTrain"
# 转换后数据的保存路径
save_path = "D:\\Users\\mks\\Desktop\\DeepLearningProjects\\YOLOv5-CCPD2020\\TempData\\LittleData"
# 图片和标签文件的保存路径
images_save_path = os.path.join(save_path, "images")
labels_save_path = os.path.join(save_path, "labels")
# 如果不存在则创建图片和标签的保存文件夹
if not os.path.exists(images_save_path): os.makedirs(images_save_path)
if not os.path.exists(labels_save_path): os.makedirs(labels_save_path)
# 获取数据集中所有的图片文件路径
images_files = listPathAllfiles(data_path)
# 初始化计数器用于生成新的文件名
cnt = 1
# 使用tqdm显示进度条
for name in tqdm(images_files):
# 只处理图片文件
if name.endswith(".jpg") or name.endswith(".png"):
# 读取图片
img = cv2.imread(name)
# 获取图片的高度和宽度
height, width = img.shape[0], img.shape[1]
# 使用正则表达式从文件名中提取坐标信息
str1 = re.findall('-\d+\&\d+_\d+\&\d+-', name)[0][1:-1]
str2 = re.split('\&|_', str1)
# 提取边界框坐标
x0 = int(str2[0])
y0 = int(str2[1])
x1 = int(str2[2])
y1 = int(str2[3])
# 计算边界框的中心点坐标以及宽度和高度,并进行归一化
x = round((x0 + x1) / 2 / width, 6)
y = round((y0 + y1) / 2 / height, 6)
w = round((x1 - x0) / width, 6)
h = round((y1 - y0) / height, 6)
# 构建标签文件名和路径
txtfile = os.path.join(labels_save_path, "green_plate_" + str(cnt).zfill(6) + ".txt")
# 构建图片文件名和路径
imgfile = os.path.join(images_save_path,
"green_plate_" + str(cnt).zfill(6) + "." + os.path.basename(name).split(".")[-1])
# 写入标签文件
open(txtfile, "w").write(" ".join(["0", str(x), str(y), str(w), str(h)]))
# 移动图片到新位置
shutil.move(name, imgfile)
# 更新计数器
cnt += 1
(2)使用以下代码验证生成的YOLO格式的标签是否正确
它通过读取图像文件和相应的标签文件来绘制边界框,并在窗口中显示带有边界框的图像。
如果边界框的位置和大小与预期相符,那么可以认为YOLO格式的标签是正确的。
# CheckYOLOLabels.py
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
def listPathAllfiles(dirname):
"""
遍历指定目录下的所有文件并返回一个包含这些文件路径的列表。
"""
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
# YOLO标签文件的保存路径
labelspath = "D:\\Users\\mks\\Desktop\\DeepLearningProjects\\YOLOv5-CCPD2020\\TempData\\LittleData\\labels"
# YOLO图片文件的保存路径
imagespath = "D:\\Users\\mks\\Desktop\\DeepLearningProjects\\YOLOv5-CCPD2020\\TempData\\LittleData\\images"
# 获取所有标签文件的路径
labelsFiles = listPathAllfiles(labelspath)
# 逆序遍历标签文件,因为通常最新的文件在最后
for lbf in labelsFiles[::-1]:
# 读取标签文件的每一行,并将其分割成一个列表
labels = open(lbf, "r").readlines()
labels = list(map(lambda x: x.strip().split(" "), labels))
# 构造对应的图片文件名
imgfileName = os.path.join(imagespath, os.path.basename(lbf)[:-4] + ".jpg")
# 从文件中读取图片,cv2.imdecode函数可以将字节流解码为图像
img = cv2.imdecode(np.fromfile(imgfileName, dtype=np.uint8), 1)
# 遍历每个标签
for lbs in labels:
# 将标签字符串转换为浮点数,并去掉类别索引
lb = list(map(float, lbs))[1:]
# 根据标签计算边界框的左上角和右下角坐标
x1 = int((lb[0] - lb[2] / 2) * img.shape[1])
y1 = int((lb[1] - lb[3] / 2) * img.shape[0])
x2 = int((lb[0] + lb[2] / 2) * img.shape[1])
y2 = int((lb[1] + lb[3] / 2) * img.shape[0])
# 在图像上绘制边界框
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 5)
# 调整图像大小,使其最大边长为600像素
ratio = 600 / min(img.shape[0:2])
img = cv2.resize(img, dsize=(int(img.shape[1] * ratio), int(img.shape[0] * ratio)))
# 显示带有边界框的图像
cv2.imshow("1", img)
# 等待用户按键,按任意键继续
cv2.waitKey()
# 关闭所有OpenCV创建的窗口
cv2.destroyAllWindows()
修改yolov5-6.0源码
(1)在根目录下新建一个dataset文件夹
将处理后的CCPD2020数据集存放到该文件夹下,文件夹结构为:
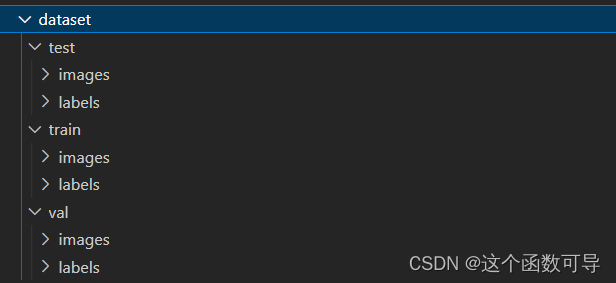
(2)在data文件夹中新建一个yaml文件
在data文件夹中新建一个yaml文件(文件名可自取,例如我的是:MyData.yaml),向MyData.yaml文件中复制以下内容:
path: D:/Users/mks/Desktop/DeepLearningProjects/YOLOv5-CCPD2020/dataset # dataset root dir
# path: /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/dataset # kaggle dataset root dir
train: train/images
val: val/images
test: test/images
# Classes
nc: 1 # number of classes
names: ["green_plate"] # class names
(3)修改 loss.py 文件
在 utils 文件夹中找到 loss.py 文件,把第173行代码进行修改。
gain = torch.ones(7, device=targets.device).long()

(4)修改 plots.py 文件
在 utils 文件夹中找到 plots.py 文件,如下图所示进行修改。

import PIL
def check_version(target_version):
"""
Check if the current PIL version is greater than or equal to the target version.
Args:
target_version (str): The target version string to compare against (e.g., '9.2.0').
Returns:
bool: True if the current PIL version is greater than or equal to the target version, False otherwise.
"""
current_version = PIL.__version__
current_version_parts = [int(part) for part in current_version.split('.')]
target_version_parts = [int(part) for part in target_version.split('.')]
# Compare version parts
for cur, tgt in zip(current_version_parts, target_version_parts):
if cur > tgt:
return True
elif cur < tgt:
return False
# If all parts are equal, the versions are equal or current version is shorter
return True
if check_version('9.2.0'):
self.font.getsize = lambda x: self.font.getbbox(x)[2:4] # text width, height
(5)修改datasets.py和general.py文件
在 utils 文件夹下找到 datasets.py和general.py文件
在 datasets.py 中,分别将第445行、第473行、第843行代码中的 np.int 改为 int
在 general.py 中,将第470行代码中的 np.int 改为 int
(6)修改模型配置文件

在models文件夹下选择一个你想要导入的模型文件,例如这里选择yolov5s.yaml,将yolov5s.yaml文件中的类别数(number of classes)更改为你自己的。
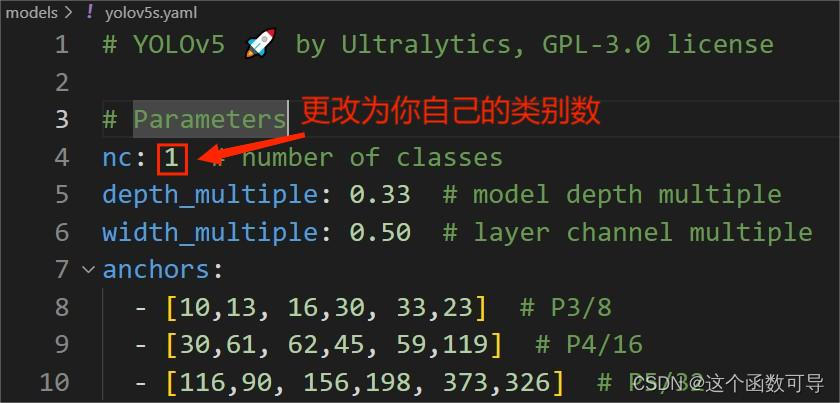
(7)Arial.ttf字体下载
- 从下面的链接中下载Arial.ttf字体文件
https://ultralytics.com/assets/Arial.ttf - 将下载的Arial.ttf字体文件放在根目录下
(8)下载预训练权重
预训练权重下载地址:https://github.com/ultralytics/yolov5/releases
根据自己需要选择预训练权重(注意要和源码版本对上)
下拉找到对应版本的 “Assets“ 导栏,在 “Assets“ 导栏 中选择所需文件进行下载。

(9)添加预训练权重文件
在项目的根目录下新建一个文件夹“weights”(名字可自取),将下载的预训练权重文件(如:yolov5s.pt)存放在该文件夹下。

(10)修改train.py文件
- 1、指定输出文件的保存路径

kaggle路径:/kaggle/working/runs/train - 2、修改data路径

自己data文件夹下的yaml文件路径:data/MyData.yaml - 3、修改模型配置文件(yolov5s.yaml)路径

指定yolov5s.yaml为默认的模型配置文件:default=ROOT / 'models/yolov5s.yaml' - 4、修改预训练权重文件(yolov5s.pt)路径

指定预训练权重文件(yolov5s.pt)路径:default=ROOT / 'weights/yolov5s.pt' - 5、调整batch-size大小

如果是在本地使用CPU进行训练,得调小batch-size(比如default=2)。
如果是使用GPU进行训练,可以适当调大batch-size(比如default=32)。 - 6、指定训练的轮数

根据自身需求修改训练轮数,如default=300表示训练300轮
环境配置
(1)使用Anaconda创建虚拟环境
1、打开 Anaconda Prompt
2、创建一个新的虚拟环境
conda create -n yolov5-ccpd python=3.8
3、激活新建的虚拟环境
conda activate yolov5-ccpd
4、切换到项目所在的根目录
4-1、切换到项目所在的盘下(如D盘)
d:
4-2、切换到项目的根目录下
cd D:\Users\mks\Desktop\DeepLearningProjects\YOLOv5-CCPD2020
5、部署环境(记得关代理/梯子)
pip install -r requirements.txt
5-1、如果下载速度慢,可更换国内源进行下载,如清华源:
pip install -r requirements.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --trusted-host=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
5-2、Kaggle中的命令:
!pip install -U -r /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/requirements.txt
运行测试
(1)本机运行测试
1、删除数据集中的 .cache文件
检查数据集文件夹dataset中的 train/test/val文件夹下是否存在文件 .cache,如果存在,需先进行删除。
2、先指定训练的轮数(epochs)为1,执行以下命令看代码是否能正常运行。
python train.py --epochs 1
(2)Kaggle上运行测试
1、先指定训练的轮数(epochs)为5,执行以下命令看代码是否能正常运行。
!python /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/train.py --data /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/data/MyData.yaml --batch-size 32 --epochs 5 --cfg /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/models/yolov5s.yaml --weights /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/weights/yolov5s6.pt
'''
!python /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/train.py
--data /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/data/MyData.yaml
--batch-size 32
--epochs 5
--cfg /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/models/yolov5s.yaml
--weights /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/weights/yolov5s6.pt
'''
2、如果遇到报错:OSError:[Error 30] Read-only file system
则把对应文件复制到 /kaggle/working/ 下(例如这里的weights文件夹下的yolov5s6.pt文件):
!cp -r /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/weights /kaggle/working/
然后执行以下命令看代码是否能正常运行。
!python /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/train.py --data /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/data/MyData.yaml --batch-size 32 --epochs 5 --cfg /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/models/yolov5s.yaml --weights /kaggle/working/weights/yolov5s.pt
'''
!python /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/train.py
--data /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/data/MyData.yaml
--batch-size 32
--epochs 5
--cfg /kaggle/input/yolov5-plate/YOLOv5-CCPD2020/models/yolov5s.yaml
--weights /kaggle/working/weights/yolov5s.pt
'''
下载Kaggle输出文件
如果是在Kaggle上训练,可以在Output进行输出文件的下载。
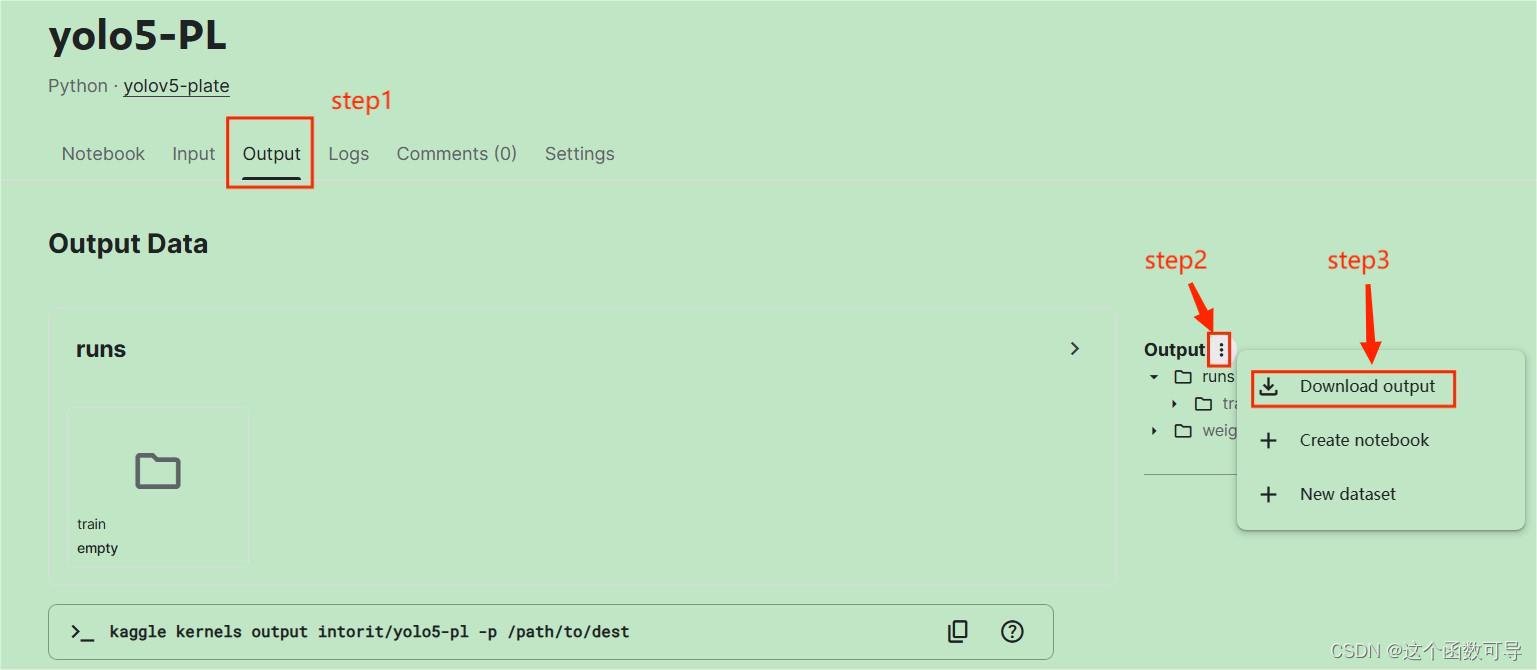
模型效果检验
(1)修改detect.py文件
# 读取照片
# parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
# 读取本地摄像机
parser.add_argument('--source', type=str, default='0', help='file/dir/URL/glob, 0 for webcam')
(2)执行detect.py文件
1、激活为项目配置的虚拟环境
conda activate yolov5-ccpd
2、运行代码
python detect.py
透视变换
import cv2
import numpy as np
import os
# 定义透视变换函数
def four_point_transform(image, pts):
# 获取一致顺序的点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算新图像的宽度和高度
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 构建目标点集
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
# 计算透视变换矩阵并应用
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后的图像
return warped
# 定义排序点的函数
def order_points(pts):
# 初始化一个列表,用于存储排序后的坐标
pts_ordered = np.zeros((4, 2), dtype='float32')
# 计算每个点的坐标之和
s = pts.sum(axis=1)
pts_ordered[0] = pts[np.argmin(s)]
pts_ordered[2] = pts[np.argmax(s)]
# 根据x坐标对点进行排序
diff = np.diff(pts, axis=1)
pts_ordered[1] = pts[np.argmin(diff)]
pts_ordered[3] = pts[np.argmax(diff)]
# 返回排序后的坐标
return pts_ordered
# 源文件夹路径
src_folder = r'D:\Users\mks\Desktop\source'
# 目标文件夹路径
dst_folder = r'D:\Users\mks\Desktop\target'
# 遍历源文件夹中的所有文件
for filename in os.listdir(src_folder):
# 只处理图片文件
if filename.endswith('.jpg'):
# 读取图片
image_path = os.path.join(src_folder, filename)
# print(filename)
image = cv2.imread(image_path)
# 从文件名中提取四个顶点的坐标
pts = np.float32([[int(x) for x in filename.split('-')[3].split('_')[0].split('&')],
[int(x) for x in filename.split('-')[3].split('_')[1].split('&')],
[int(x) for x in filename.split('-')[3].split('_')[2].split('&')],
[int(x) for x in filename.split('-')[3].split('_')[3].split('&')]])
# print(pts)
# 进行透视变换
warped_image= four_point_transform(image, pts)
# 保存变换后的图片
dst_path = os.path.join(dst_folder, filename)
cv2.imwrite(dst_path, warped_image)
一开始源文件夹路径(D:\Users\mks\Desktop\source)中的图片为:
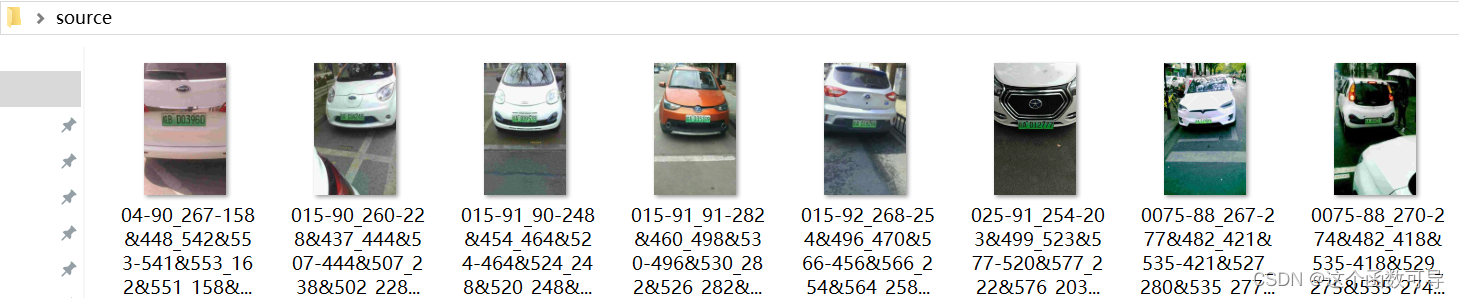
经过透视变换后存放在目标文件夹路径(D:\Users\mks\Desktop\target)中的图片为:



















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









