







目录
文章标题:《KAN: Kolmogorov–Arnold Networks》
文章地址:
KAN: Kolmogorov-Arnold Networks (arxiv.org)![]() https://arxiv.org/abs/2404.19756代码地址:
https://arxiv.org/abs/2404.19756代码地址:
KindXiaoming/pykan: Kolmogorov Arnold Networks (github.com)![]() https://github.com/KindXiaoming/pykan
https://github.com/KindXiaoming/pykan
1.研究背景
MLP作为深度学习模型中的基础模块,有很好的非线性函数逼近能力,但是作者认为MLP并不是最好的非线性回归器。例如在Transformer中MLP消耗了几乎所有的非嵌入参数,并且可解释性较弱。因此,作者提出用KAN来替代MLP
KAN有以下特点:
①全连接结构
②边上的可学习激活函数
③权重参数被替换成可学习的样条函数
④在节点处进行简单的相加操作
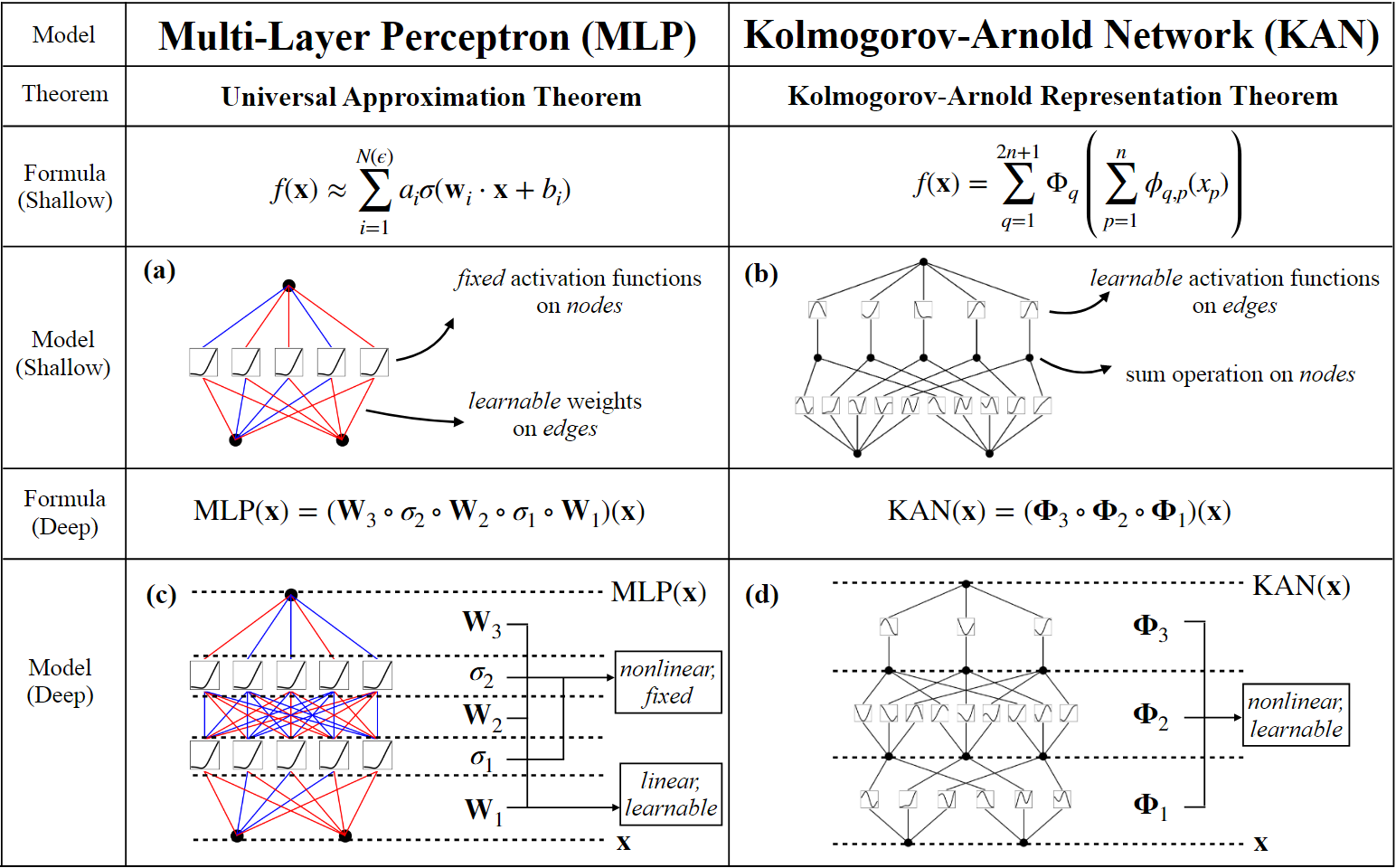
作者从理论上分析了为什么KAN有更好的效果:
其一,样条函数对于低维空间是精准,但是由于它不能利用复杂结构导致在高维的效果较差(维度灾难)
其二,由于MLP能够进行特征学习避免了维度灾难,但它无法优化单变量函数使得在低维空间不如样条函数 KAN利用了上述的两个结构,互相弥补了缺点

2.关键技术
2.1 原始公式
Kolmogorov-Arnold(KA) Representation Theorem假设是一个在有界域上的多元连续函数,那么
可以写成有限多个单变量连续函数相加
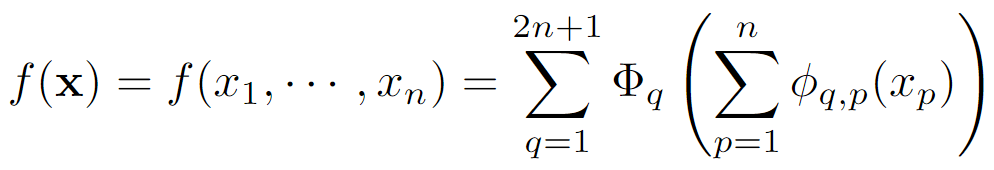
但是这个原始表达式只对应了一个拥有两层非线性激活函数,并且隐藏层只有2n+1个节点的网络

如果仅仅利用原表达式去做机器学习(拟合、回归等),由于一维函数可能非平滑,所以在实际操作中并非是可学习的
2.2 KAN结构
任务定义:找到函数,拟合输入输出对
,使得
,对应于原始公式只需要找到
和
即可
![]()
表示一维函数矩阵,定义q为输出维度,p为输入维度
定义KAN的形状表示为:
![]()
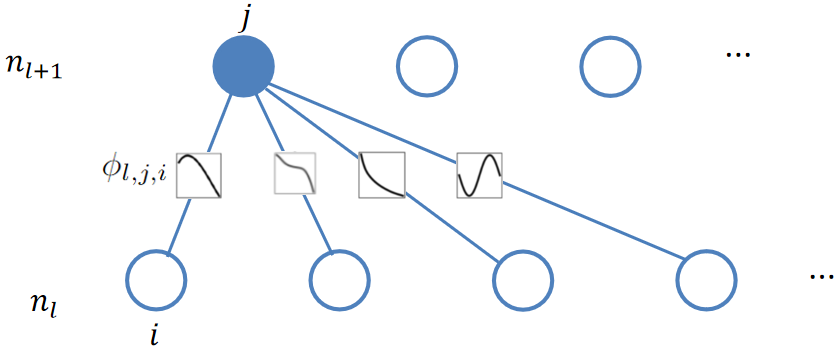
其中,ni表示第i层节点个数 定义第i个神经元在第l层表示为(l, i),表示(l, i)神经元的激活值,第l层和第l+1层之间有
个激活函数(因为激活函数在边上,并且为全连接),那么(l, i)和(l+1, i)之间的激活函数可以表示成
![]()
上述过程对应于下图:
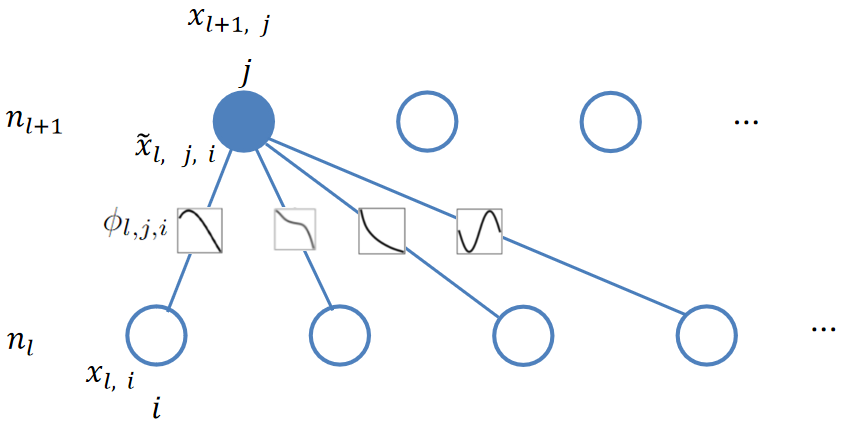
因此第l+1层的第j个节点可表示成:

写成矩阵形式为:

其中,表示第l层的激活函数矩阵,那么对应一个有L层的KAN网络,有:
![]()
写成与原始公式相似的形式:

在实现上,激活函数采用多个一维的B-Spline函数的结合,并利用残差激活函数
![]()
![]()

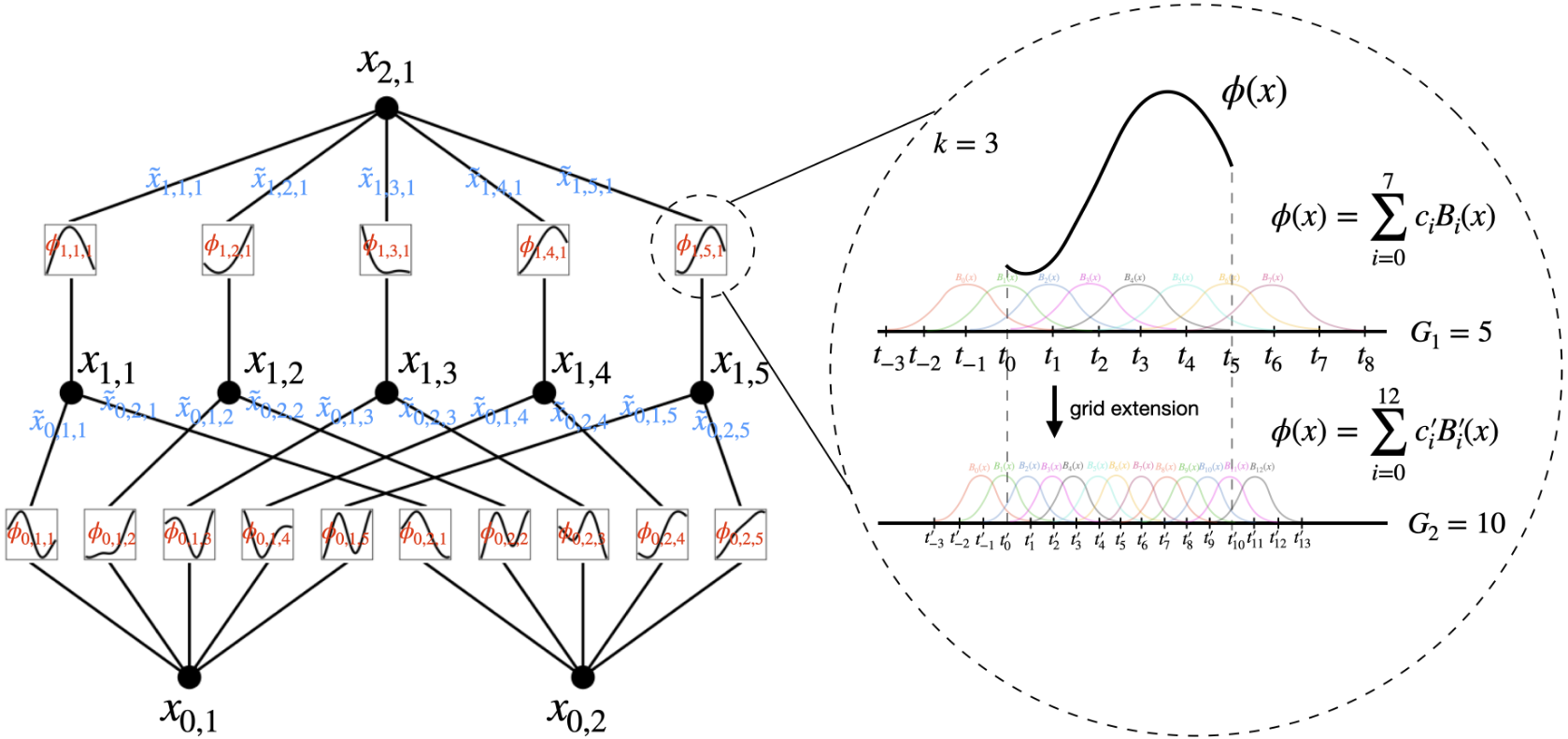
参数量对比,L层,宽度N(k表示样条函数为k阶)
KAN:(上限挺好推的,但是下限不太懂为什么是+k而不是*k)
![]()
MLP:
![]()
2.3 缩放定律
神经缩放定律是测试损失(test Loss)随着模型参数的增加而减小的现象,即![]() 其中 ℓ 是测试 RMSE,N 是参数数量,α 是缩放指数。也就是说,参数量越大,误差越小(精度越高)
其中 ℓ 是测试 RMSE,N 是参数数量,α 是缩放指数。也就是说,参数量越大,误差越小(精度越高)
KAN能通过细分数据域网络来提高B-Spline函数逼近的精度,从而使缩放更加自由,能够有效控制参数量。而MLP对于不同的网格划分需要重新进行训练
例如,可以先训练一个参数较少的 KAN,然后通过使Spline网格粒度更细,使其扩展到参数较多的 KAN,这一方式降低了复杂度
3.技术扩展
为了提高KAN的可解释性,作者提出了一些简化模型的技术:
①稀疏化
MLP:L1正则化
KAN:定义L1范数,去除线性权重,再加上熵正则化
因此可以得到整体的训练损失为:
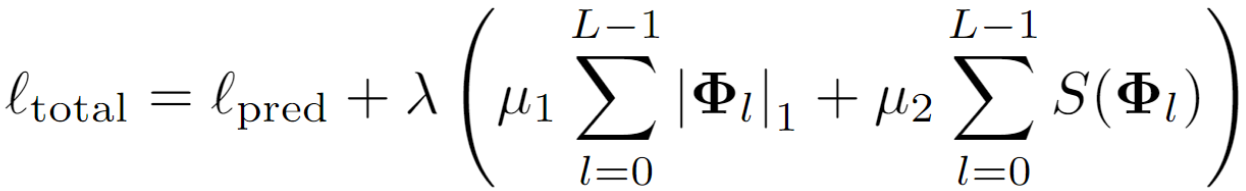
预测损失+L1正则化+熵正则化,通过λ控制正则化幅度
②可视化
将激活函数的透明度设置为与成正比,其中 β = 3
重要的函数会凸显出来
③剪枝
对每个节点定义输入输出分数,输入输出分数都大于阈值的节点会被保留下来,其余会被修剪掉
![]()
④符号化
如果猜测某些激活函数实际上是符号函数(例如 cos 或 log),则提供一个接口将其设置为指定的符号形式,后续只需要拟合参数即可

在剪枝完后,用户可以根据形状选择符号函数的公式,然后进一步训练,如果训练损失下降了,就表明选择了正确的符号表达式
4.模型效果
①拟合精度方面的比较
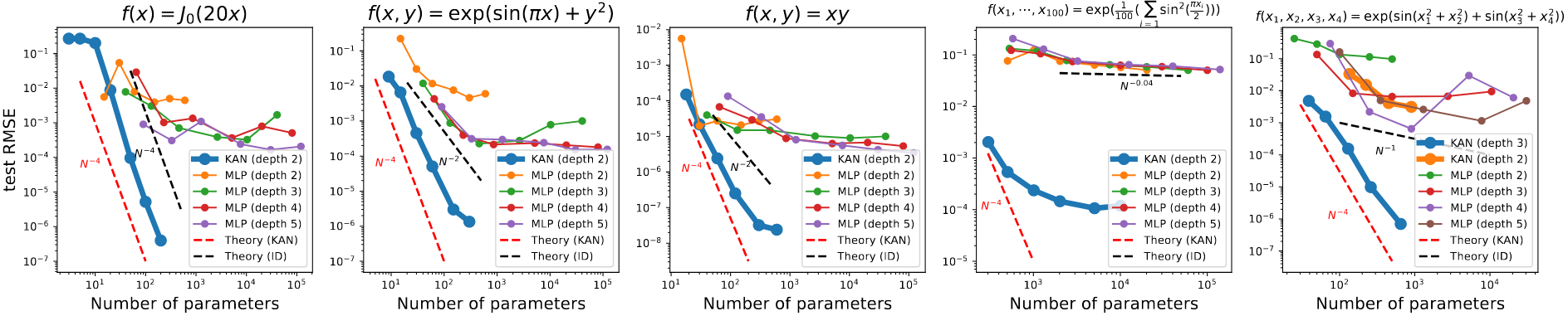
KAN有更好的放缩曲线,特别是高维,而MLP很快就饱和了,表明了KAN的扩展能力很强,并且KAN像MLP一样网络越深效果越好
②解决更复杂的偏微分方程

KAN 使用较小的网络和更少的参数实现了更好的误差缩放定律
作者还将KAN用在数学和物理领域的一些实际应用上,均表明KAN能用更少的参数量得到更好的效果
5.相关讨论
KAN还有一些可以改进的地方:
①在精度层面,还可以进一步研究模型结构和训练细节来提高效果
②对于KAN来说,最大的问题是训练太慢,因为无法利用batch计算,可以尝试对激活函数分组,同一组内使用相同的激活函数
③可以引入自适应性来提高KAN的精度和效率
④将KAN用在实际任务中,机器学习/理论科学
⑤由于KAN具有可解释性,可以尝试与AI4Science结合

6.总结
KAN基于Kolmogorov-Arnold Representation Theorem,并对两层网络进行扩展。通过将可学习激活函数设置在边上,而节点处进行简单的相加操作构建了KAN模型。由于KAN使用较少的参数量就能媲美MLP,并且还能通过简化技术使其具有良好的可解释性,因此KAN有望替代MLP作为神经网络中的基础模块。相比MLP而言,KAN有更好的缩放性能,但在相同的参数量下,KAN的训练速度过慢成为了最大的问题。
笔者的思考:
①作者强调了浅层的KAN就能达到甚至超过深层MLP的性能,是否意味着深层的KAN不太能实现(训练太慢,小模型适用)
②KAN不太适用于现在的深度学习框架,从硬件计算层面不太有优势
③从网络架构来看,其实KAN和MLP差不多(虽然原理不同),区别在于MLP是进行线性组合再进行激活,而KAN是先进行激活再线性组合,并且KAN中不同边上的激活函数并不相同,也正是这点带来了额外的计算复杂度,是否意味着KAN只是MLP更一般的形式
④笔者认为本文最大的特点是可解释性,适合用在较小的问题上,在AI4Science领域可能会有较大提高
















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











