







Wu H, Xiao B, Codella N, et al. Cvt: Introducing convolutions to vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 22-31.
(本文图片来自原论文)
文章目录
一、论文创新点总结
对于ViT模型进一步改进策略——通过引入卷积的方式:
- 新的embedding方式—— Convolutional token embedding
- 新的QKV映射方式——Convolutional projection
二、文章内容概述
1. Introduction
- Transformer从NLP到CV的发展过程,及其特点:全局关联性
- ViT在小规模数据集上表演不如CNN可能的原因:CNN所具有的捕捉二维局部结构特性的能力:CNN通过局部接收域、共享权值、空间子采样等方式来获取图像位移、缩放和失真不变性。从而同时获得图像低维边缘信息和高维语义信息
- 本工作将卷积合理的引入ViT当中,成为CvT网络模型。(模型结构上面已经介绍,这里不再赘述,后面还会详细介绍实验过程)
2. Related Work
- Transformer在视觉领域广泛应用
- Vision Transformers : 具体实现概述;后来的改进工作(针对位置编码、patch的embeding方式、通过滑动窗口实现token之间关联性的计算、多级设计)
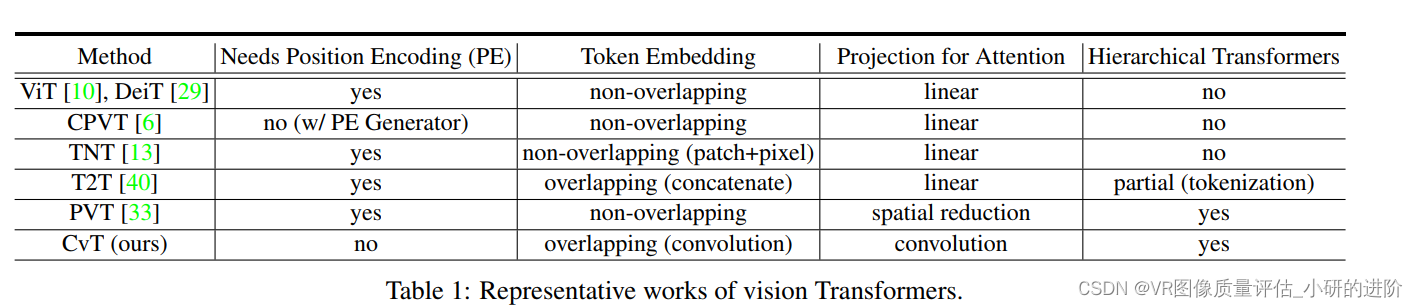
- Introducing Self-attentions to CNNs:工作——建立全局关联性。相关工作举例:将CNN中的卷积替换成全局自注意力在Resnet最后三层
- Introducing Convolutions to Transformers:相关工作:将多头注意力替换成卷积;增加平行的额外卷积层;通过残差层传递注意力权重图。我们的工作的不同点:将卷积引入到ViT两个关键的位置——QKV映射;使用多层级结构实现token maps的建立
3. Convolutional vision Transformer
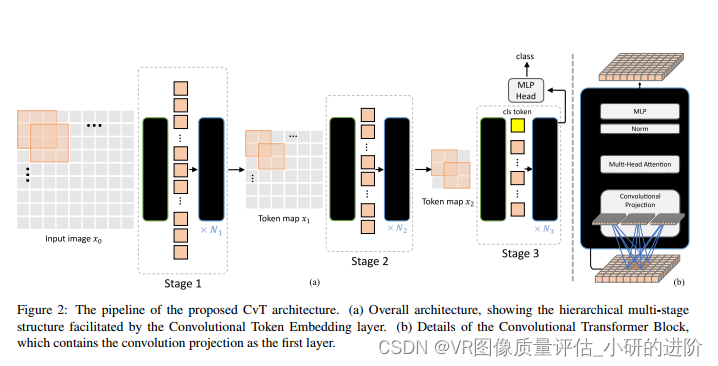
- 借鉴了CNN的多层级结构:
- 一共分三层;
- 每层有两部分:1. ConvolutioToken Embedding ——层输入图像或者转换得到的二维token maps(得到重叠的patch,也就是卷积操作)注意:不添加位置信息; 2. Convolutional Transformer Blocks——包括:一个卷积映射操作;cls_token只在最后一层加上去;MLP
3.1. Convolutional Token Embedding
输入:
过程:

- 二维卷积操作:
- 卷积核大小:
- 步长:
- padding:
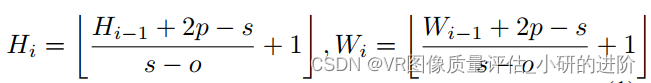
输出:
处理:
- 展平到:
- normalized: layer normalization
3.2. Convolutional Projection for Attention
3.2.1 Implementation Details

3.2.2 Efficiency Considerations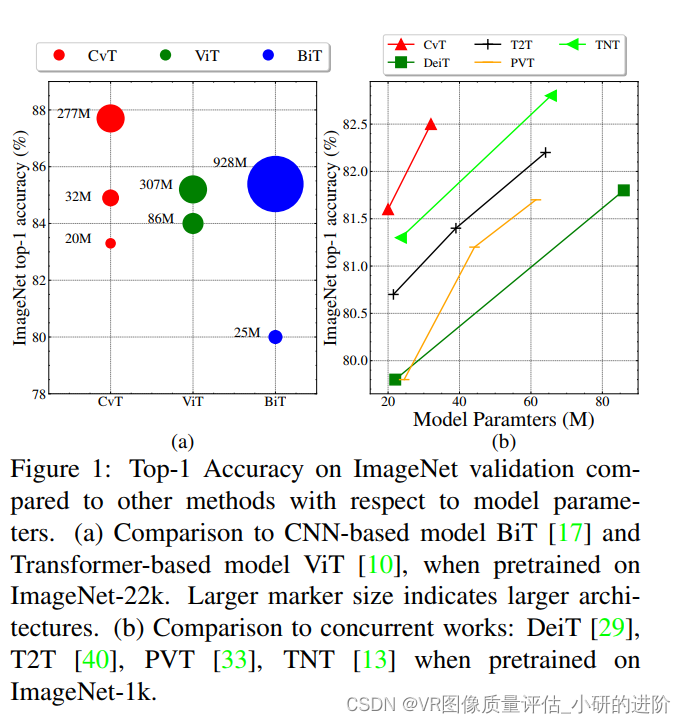
在尽量保证性能的前提下,减少了计算复杂度
3.3. Methodological Discussions
- Removing Positional Embeddings: 因为QKV的映射采用卷积的形式,因此模型对于局部空间关系有了建模能力,位置编码的工作就可以省略掉;
- Relations to Concurrent Work:
4. Experiments
4.1. Setup
- Model Variants

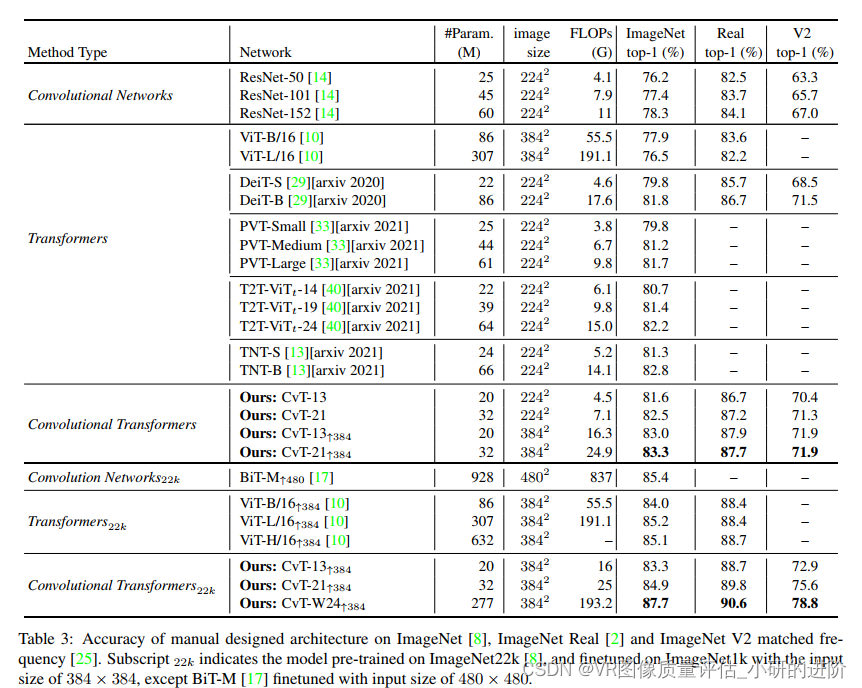
4.2. Comparison to state of the art
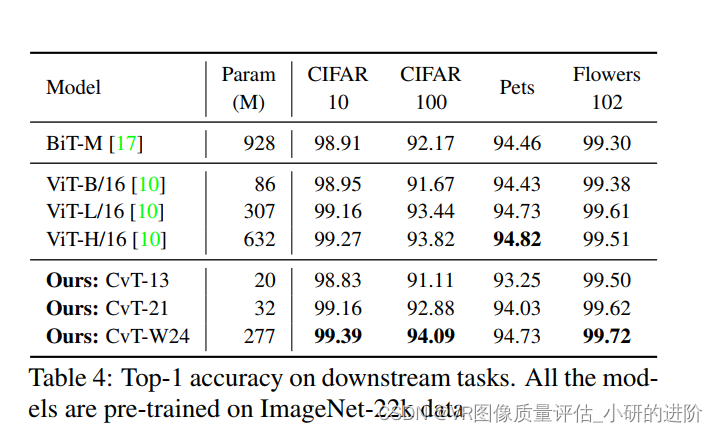
4.3. Downstream task transfer
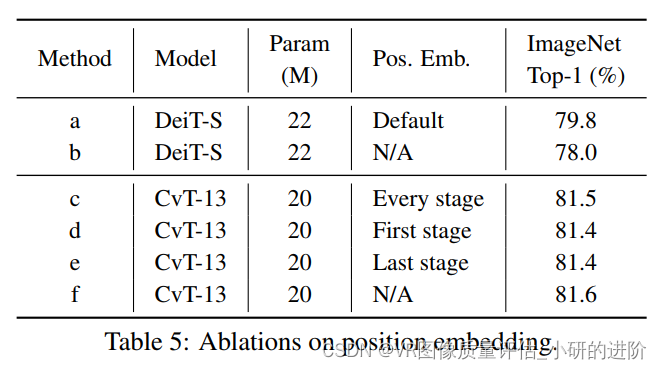
4.4. Ablation Study
- Removing Position Embedding
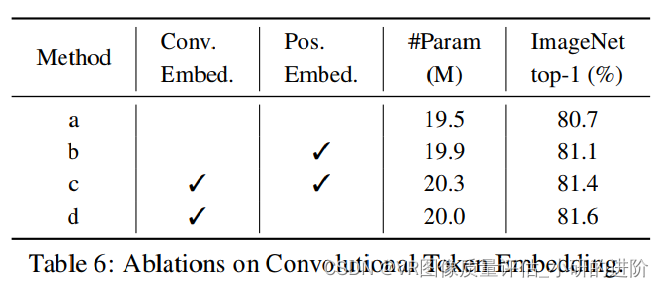
- Convolutional Token Embedding
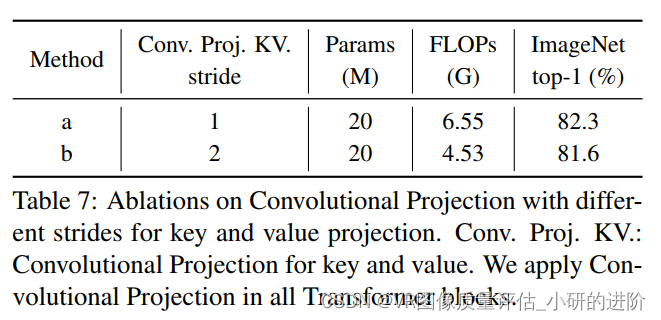
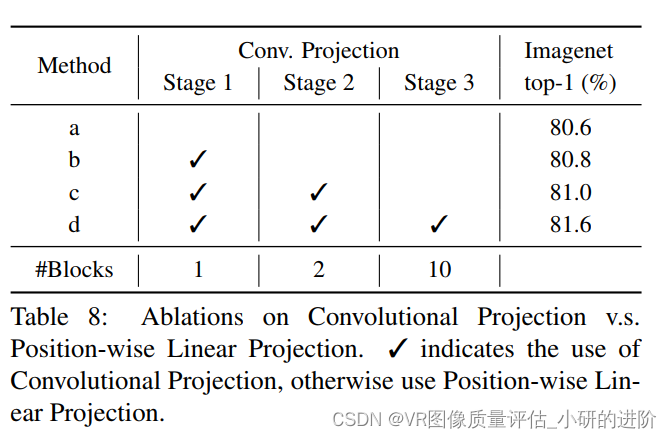
- Convolutional Projection















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









