







二叉树的前序遍历
144. 二叉树的前序遍历 - 力扣(LeetCode) (leetcode-cn.com)
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:输入:root = []
输出:[]
示例 3:输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
示例 5:
输入:root = [1,null,2]
输出:[1,2]提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
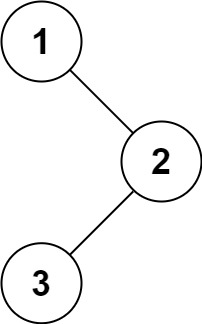
思路:非常简单的一题,运用递归就能解决。定义一个函数,因为是求前序遍历,如果该树节点不为空,先将该树节点的数据域插入到vector的容器中,然后再分别递归左子树和右子树。
class Solution {
public:
vector<int>s;
vector<int> preorderTraversal(TreeNode* root) {
PreTraversal(root);
return s;
}
void PreTraversal(TreeNode* x)
{
if(x!=NULL){
s.push_back(x->val);
PreTraversal(x->left);
PreTraversal(x->right);
}
}
};二叉树的中序遍历
94. 二叉树的中序遍历 - 力扣(LeetCode) (leetcode-cn.com)
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:输入:root = []
输出:[]
示例 3:输入:root = [1]
输出:[1]提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
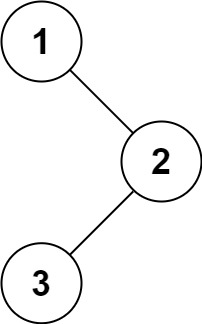
思路:跟之前的前序遍历做法完全一样,就是把根左右改成左根右的顺序即可
class Solution {
public:
vector<int>s;
vector<int> inorderTraversal(TreeNode* root) {
PreTraversal(root);
return s;
}
void PreTraversal(TreeNode* x)
{
if(x!=NULL){
PreTraversal(x->left);
s.push_back(x->val);//左根右
PreTraversal(x->right);
}
}
};二叉树的后序遍历
145. 二叉树的后序遍历 - 力扣(LeetCode) (leetcode-cn.com)
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[3,2,1]
示例 2:输入:root = []
输出:[]
示例 3:输入:root = [1]
输出:[1]
提示:
树中节点的数目在范围 [0, 100] 内
-100 <= Node.val <= 100
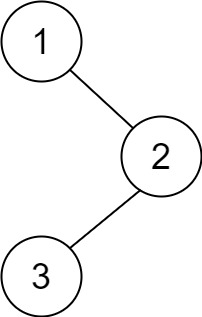
思路:其实跟前两题一样,把遍历顺序改为左右根即可。
class Solution {
public:
vector<int>s;
vector<int> postorderTraversal(TreeNode* root) {
PreTraversal(root);
return s;
}
void PreTraversal(TreeNode* x)
{
if(x!=NULL){
PreTraversal(x->left);
PreTraversal(x->right);
s.push_back(x->val);
}
}
};二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
示例 2:输入:root = [1]
输出:[[1]]
示例 3:输入:root = []
输出:[]提示:
树中节点数目在范围 [0, 2000] 内
-1000 <= Node.val <= 1000
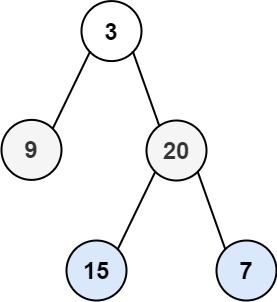
题解:层序遍历要求的输入结果和 BFS 是不同的。正常的BFS 的遍历结果是一个一维数组,无法区分每一层。而层序遍历要求我们区分每一层,也就是返回一个二维数组。解决办法就是在每一层遍历开始前,先记录队列中的结点数量 n(也就是这一层的结点数量),然后一口气处理完这一层的 n个结点。
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector <vector <int>> ans;
if(!root)return ans;
queue <TreeNode*> q;
q.push(root);
while(!q.empty()){
vector<int>t;
int n=q.size();
for(int i=0;i<n;i++){
TreeNode* node=q.front();
q.pop();
if(node->left!=NULL)q.push(node->left);
if(node->right!=NULL)q.push(node->right);
t.push_back(node->val);
}
ans.push_back(t);
}
return ans;
}
};然后总结一下在二叉树上进行 DFS 遍历和 BFS 遍历的代码比较。
DFS 遍历使用递归(Java):
void dfs(TreeNode* root) {
if (root == NULL) {
return;
}
dfs(root.left);
dfs(root.right);
}BFS 遍历使用队列数据结构(Java):
void bfs(TreeNode* root) {
queue <TreeNode*> queue;
queue.push(root);
while (!queue.empty()) {
TreeNode* node=queue.front();
queue.pop();
if (node.left != NULL) {
queue.push(node->left);
}
if (node.right != NULL) {
queue.push(node->right);
}
}
}














 6046
6046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









