







算法说明:
(1)用带权的邻接矩阵Cost来表示带权的n个节点的有向图,Cost[i,j]表示弧 的权值,如果从vi到vj不连通,则Cost[i,j]=∞;若连通则权值为两个节点的距离。引进一个辅助向量Dist,每个分量Dist[i]表示从起始点到每个终点vi的 最短路径长度。假定起始点在有向图中的序号为i0,并设定该向量的初 始值为: Dist[i]=Cost[i0,i] vi∈V。令S为已经找到的从起点出发的最短路径的终点的集合。
(2)选择Vj,使得 Dist[j]=Min{ Dist[i]|Vi∈V-S} vi∈V vj就是当前求得的一条从vi0出发的最短路径的终点,令 S=S∪{vj}。
(3)修改从vi0出发到集合V-S中任意一顶点vk的最短路径长度。 如果 Dist[j]+Cost[j,k]则修改Dist[k]为: Dist[k]=Dist[j]+Cost[j,k]。
(4)重复第2、3步操作共n-1次,由此求得从vi0出发的到图上各 个顶点的最短路径是依路径长度递增的序列。
实例:
程序说明:
1:定义无穷大inf:
double a = 1;
double inf = a / 0;//定义无穷大2:函数Dijkstra用来计算:以0号点为起点计算到其它点的最短距离输入参数有二个:一个为邻接矩阵,另外一个为所求的点号;
double Dijkstra(double m[6][6],int n)//计算以V0为起点到其他顶点的最短距离
//m为邻接矩阵
//n为终点的点号 即从V0到VN的点号结果:
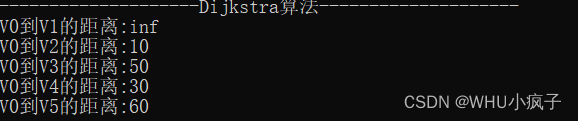
PS:
if (S[1] == n || S[2] == n || S[3] == n || S[4] == n || S[5] == n)
break;//若不加此判断条件,循环结束DIST中即为点0到其余各点的最短距离函数中删去此判断条件,循环结束DIST中即为点0到其余各点的最短距离。
代码:
#include<iostream>
using namespace std;
double Dijkstra(double m[6][6],int n)//计算以V0为起点到其他顶点的最短距离
//m为邻接矩阵
//n为终点的点号 即从V0到VN的点号
{
int S[6]; S[0] = 0;
int V[5][5]; V[0][0] = 1; V[0][1] = 2; V[0][2] = 3; V[0][3] = 4; V[0][4] = 5;
//V第几行就是减了几次点。
double DIST[5];//初始Dist矩阵
for (int i = 1; i < 6; i++)
{
DIST[i-1] = m[0][i];//从V0出发到各点的距离作为初始值
}
double min; int num[6];//min用来找其中的最小值进行V,S调整,num来存贮其对应点号
num[0] = 0;
for (int s=1;s<6;s++)
{
min = DIST[V[s-1][0]-1]; num[s] = V[s - 1][0];//以第一个点为初值
for(int i = 1; i < 6-s; i++)
{
if (DIST[V[s - 1][i]-1] < min)
{
min = DIST[V[s - 1][i]-1];
num[s] = V[s - 1][i];
}
}
S[s] = num[s];//更新S
int t = 0;
for (int i = 0; i < 6-s; i++)//更新V
{
if (V[s - 1][i] == num[s])
t++;
else V[s][i - t] = V[s - 1][i];
}
for (int i = 0; i < 5; i++)//更新DIST
{
if (DIST[i] > DIST[num[s]-1] + m[num[s]][i+1])
DIST[i] = DIST[num[s]-1] + m[num[s]][i+1];
}
if (S[1] == n || S[2] == n || S[3] == n || S[4] == n || S[5] == n)
break;//若不加此判断条件,循环结束DIST中即为点0到其余各点的最短距离
}
return DIST[n - 1];
}
int main()
{
double a = 1;
double inf = a / 0;//定义无穷大
double m[6][6] = {
inf,inf,10,inf,30,100,
inf,inf,5,inf,inf,inf,
inf,inf,inf,50,inf,inf,
inf,inf,inf,inf,inf,10,
inf,inf,inf,20,inf,60,
inf,inf,inf,inf,inf,inf
};//邻接矩阵
double L1, L2, L3, L4, L5;
L1 = Dijkstra(m, 1);//计算V0到V1的距离
L2 = Dijkstra(m, 2);//计算V0到V2的距离
L3 = Dijkstra(m, 3);//计算V0到V3的距离
L4 = Dijkstra(m, 4);//计算V0到V4的距离
L5 = Dijkstra(m, 5);//计算V0到V5的距离
cout << "--------------------Dijkstra算法--------------------" << endl;
cout << "V0到V1的距离:" << L1 << endl;
cout << "V0到V2的距离:" << L2 << endl;
cout << "V0到V3的距离:" << L3 << endl;
cout << "V0到V4的距离:" << L4 << endl;
cout << "V0到V5的距离:" << L5 << endl;
return 0;
}
















 3453
3453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











