









【模板】并查集
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
输入格式
第一行包含两个整数 N , M N,M N,M ,表示共有 N N N 个元素和 M M M 个操作。
接下来 M M M 行,每行包含三个整数 Z i , X i , Y i Z_i,X_i,Y_i Zi,Xi,Yi 。
当 Z i = 1 Z_i=1 Zi=1 时,将 X i X_i Xi 与 Y i Y_i Yi 所在的集合合并。
当
Z
i
=
2
Z_i=2
Zi=2 时,输出
X
i
X_i
Xi 与
Y
i
Y_i
Yi 是否在同一集合内,是的输出
Y ;否则输出 N 。
输出格式
对于每一个
Z
i
=
2
Z_i=2
Zi=2 的操作,都有一行输出,每行包含一个大写字母,为 Y 或者 N 。
样例 #1
样例输入 #1
4 7
2 1 2
1 1 2
2 1 2
1 3 4
2 1 4
1 2 3
2 1 4
样例输出 #1
N
Y
N
Y
提示
对于 30 % 30\% 30% 的数据, N ≤ 10 N \le 10 N≤10, M ≤ 20 M \le 20 M≤20。
对于 70 % 70\% 70% 的数据, N ≤ 100 N \le 100 N≤100, M ≤ 1 0 3 M \le 10^3 M≤103。
对于 100 % 100\% 100% 的数据, 1 ≤ N ≤ 1 0 4 1\le N \le 10^4 1≤N≤104, 1 ≤ M ≤ 2 × 1 0 5 1\le M \le 2\times 10^5 1≤M≤2×105, 1 ≤ X i , Y i ≤ N 1 \le X_i, Y_i \le N 1≤Xi,Yi≤N, Z i ∈ { 1 , 2 } Z_i \in \{ 1, 2 \} Zi∈{1,2}。
题解
并查集操作
并查集一共有两个常见的操作
- 查找
由于规定同一个集合中存在一个根节点,因此查找操作就是对给定的节点寻找根节点(也就是寻找父亲)
int findFather(int x)
{
while(x!=father[x])x=father[x];
return x;
}
- 合并
就是将两个无关的集合进行合并,首先先要判断两个集合元素是否属于同一个集合当中,也就是根节点是否相同,合并的过程一般就是把其中一个集合的根节点的父亲指向另一个集合的根节点
void Union(int a,int b)
{
int faA=findFather(a);
int faB=findFather(b);
if(faA!=faB)father[faA]=faB;
}
完整题解
#include<iostream>
const int N=100010;
using namespace std;
int p[N];
int find(int x)
{
if(p[x]!=x)p[x]=find(p[x]);
return p[x];
}
int main()
{
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;++i)p[i]=i;//初始化操作,自己是自己的父亲
while(m--)
{
int op,x,y;
scanf("%d%d%d",&op,&x,&y);
if(op==1)
{
p[find(x)]=find(y);//将两个集合合并
}
else
{//查看两个集合是否相同的父节点
if(find(x)==find(y))puts("Y");
else puts("N");
}
}
return 0;
}
路径压缩
路径压缩是并查集当中的一个常见操作,由于目标是找到每个节点的根节点,那么就可以把当前查询节点的路径上所有的结点的父亲都指向根节点
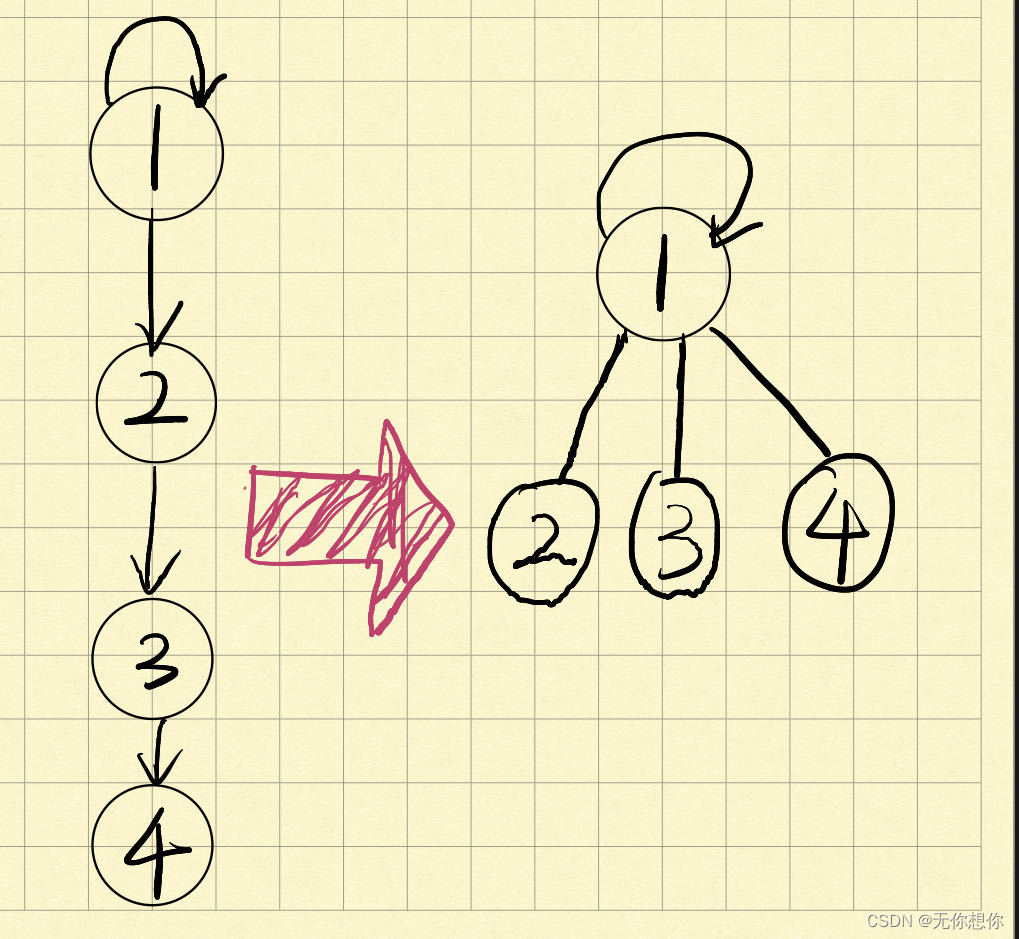
这样做的好处就在于可以将访问的时间下降到
O
(
1
)
O(1)
O(1)
int findFather(int x)
{
int a=x;//将原先的x保存
while(x!=father[x])x=father[x];
while(a!=father[a])
{
int z=a;
a=father[a];
father[z]=x;//原先的结点a的父亲改为根节点x
}
return x;//返回根节点
}
参考内容
- 算法笔记,推荐大家看一下
- 原题来自洛谷















 2144
2144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









