






Self-Attention的Input是一串Vector,这个Vector可能是整个Network中的Input,也可能是某个Hidden Layer的Output。
假设我们用一排向量a1,a2,a3,a4来表示这个Input,用b1,b2,b3,b4来表示Output。我们有一种机制,这个机制能够找出这一个Input中,哪一个向量和a1关联性最大,我们把这个关联记作α。
那么我们是如何找出这个关联性然后给他一个α呢?
方法有很多,此处列举一个比较常见的做法:Dot-product
假设计算a1和a2向量的关联性(绿色方框),分别给a1,a2乘上一个矩阵Wq和Wk,再把得到的结果进行点积得到α。
我们已经计算出α,但是如何把他套用在attention中呢?
我们按照此逻辑把a1到a4的关联性分数都计算出来记为,
,
,
。
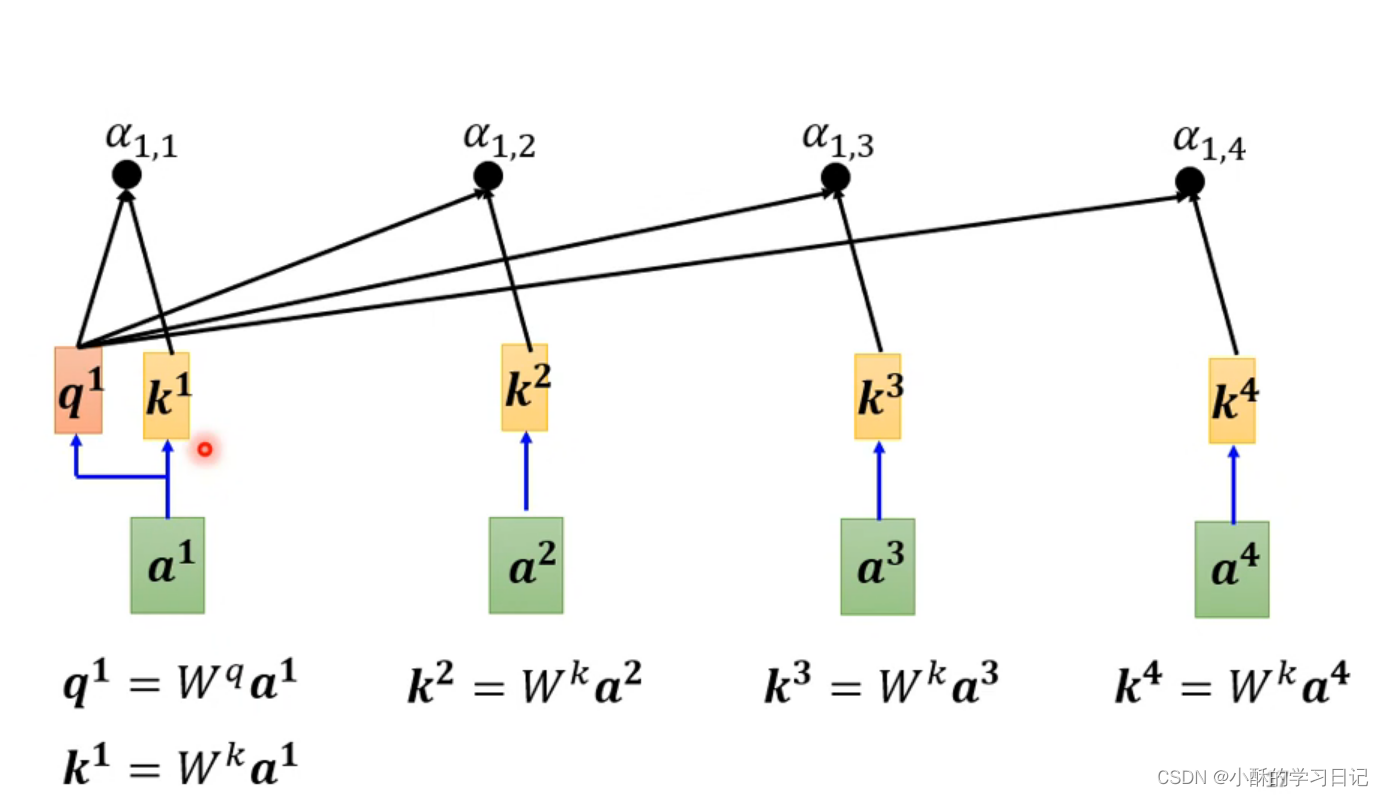
计算出关联性以后我们分别对它进行一下Soft-max,当然也可以使用其他函数,但是使用Soft-max效果最好。我们记为...
。
我们已经知道了向量之间的关联性了。现在开始抽取这一个sequence的重点。我们把a1,...a4分别乘上矩阵Wv,把得到的矩阵和上面得到的attention score相乘,再得到的数值相加得到b1 。
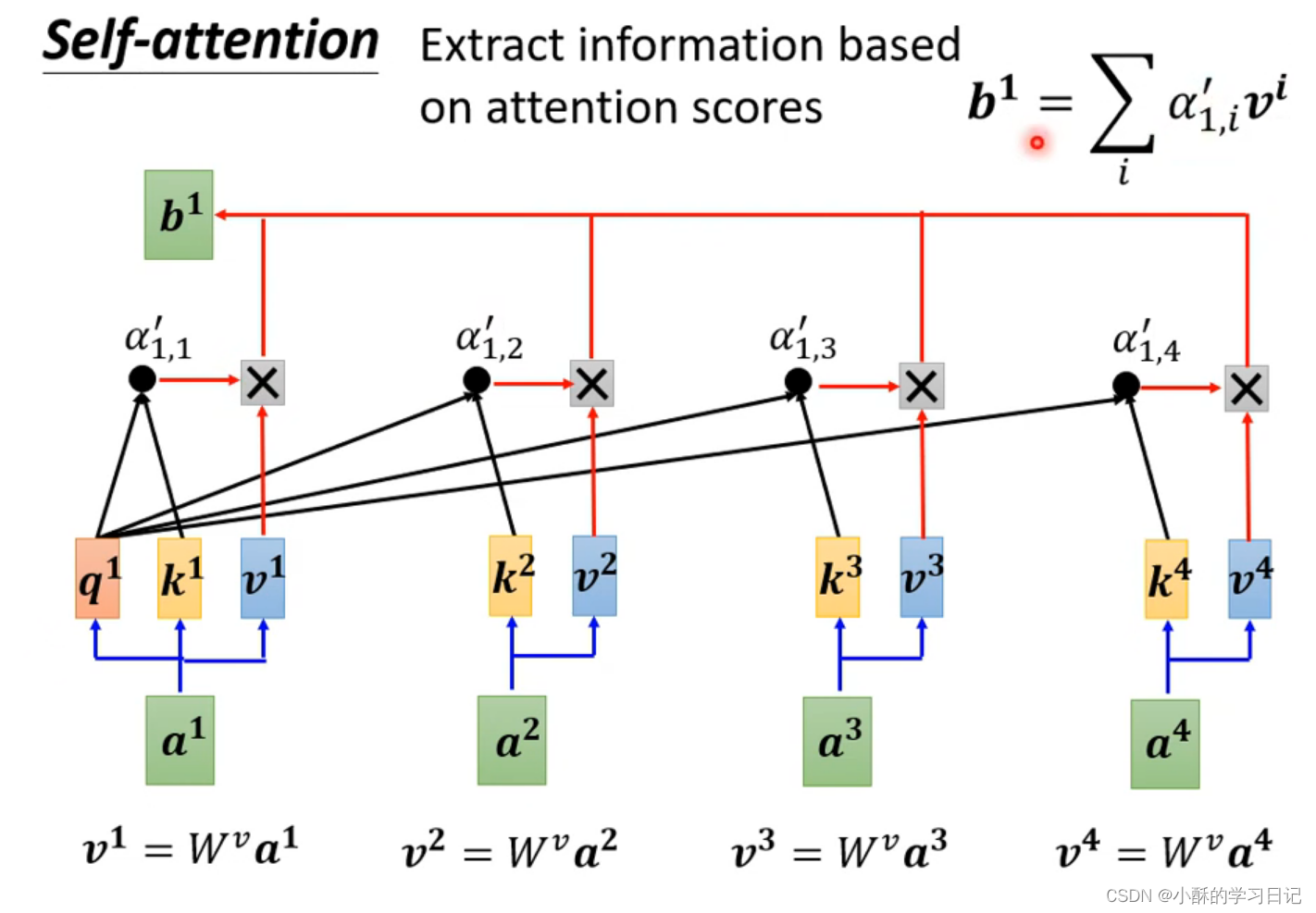
如果说a1和a2的关联性较强,那么他得到的attention score就会较高。所得到的b1的值就会接近v2
写完发现有一篇文章讲的很好,贴在这儿回头回头方便自己找:Seq2Seq中的Attention和self-attention_seqselfattention_我叫龙翔天翼的博客-CSDN博客















 3869
3869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









