







1、什么是迁移学习
关于什么是迁移学习,在回答这个问题之前我们需要思考一般情况下的学习任务会遇到哪些问题
a、训练集太少。在训练样本过少的情况下,我们的学习算法很容易过拟合,使得泛化误差过大
b、参数调整。在算法学习的过程中在参数的调整上会消耗大量的时间,尤其是超参数。而且算法也有可能陷入局部最优
c、参数太多。即便我们有各种手段来尽可能客服过拟合和局部最优的问题,但是大量的参数意味着我们需要大量的计算资源和时间
而迁移学习就是解决这些问题的学习方法。例如,曾经有人训练了一个算法,譬如CNN的图像分类,而现在我们也有一个图像分类的任务,并且分类的目标和他的目标近似。那么我们就直接拿这个训练好了的CNN网络作为我们的初始化网络,而不再随机初始化。其中的一些超参数,例如卷积池化,激活函数,就不需要我们进行调整。这种直接采用已经训练好的算法模型的部分参数作为自己的算法模型的初始化的学习算法,就是迁移学习。
2、残差网络的迁移学习
接下来利用残差网络对迁移学习进行应用
首先初始化GPU等
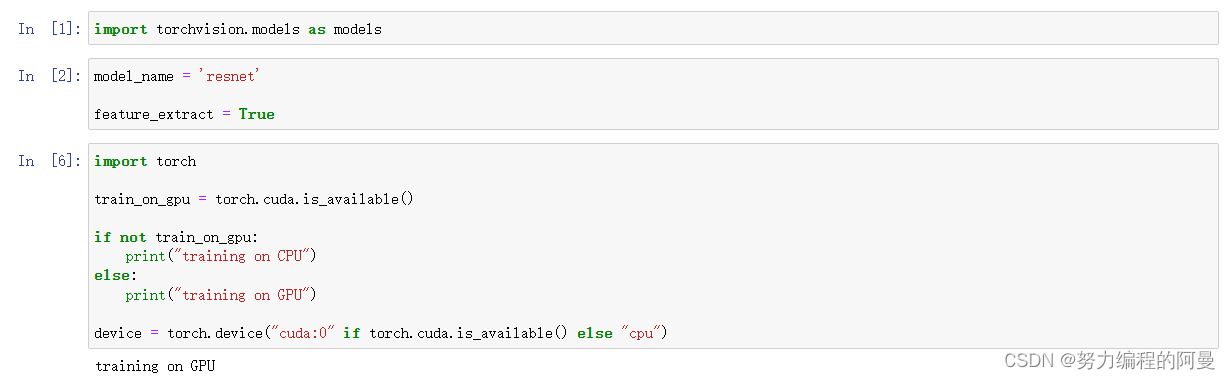
接着设定一个函数,这个函数的作用是在接下来的训练中表示,某一层是否需要进行训练

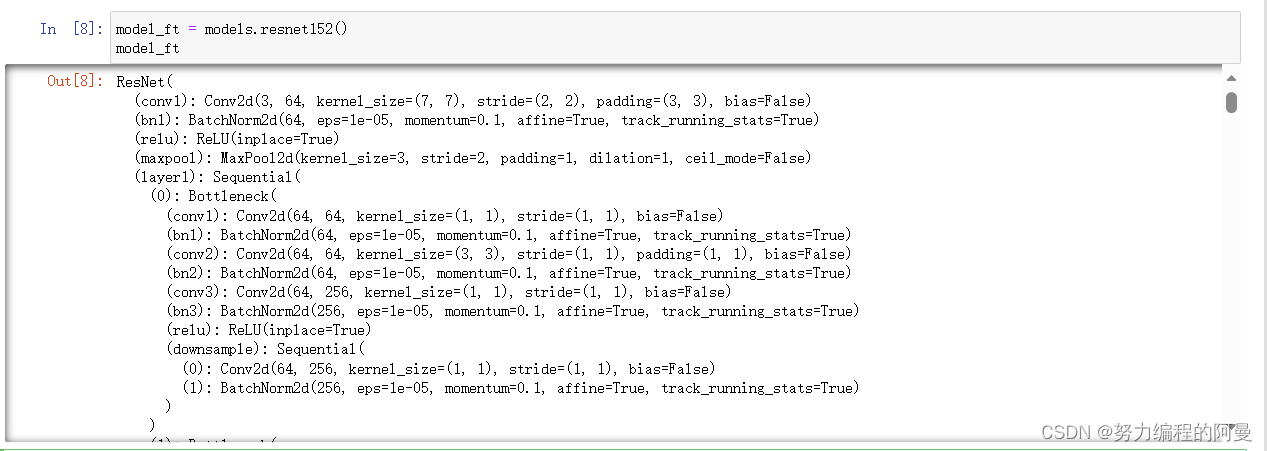
然后将模型放进来
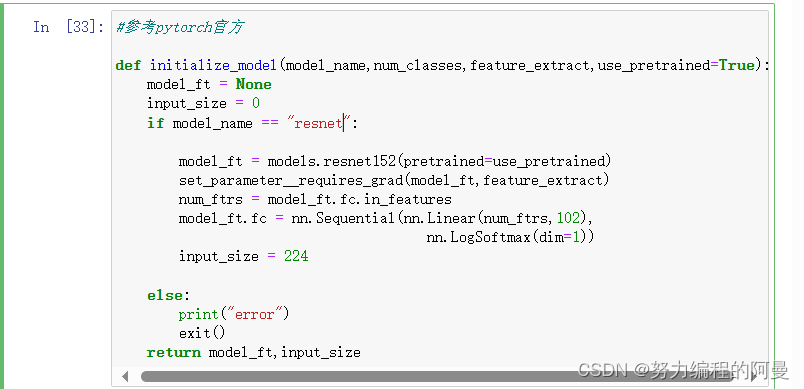
然后参考pytorch官方的代码,对模型初始化
然后运用到模型中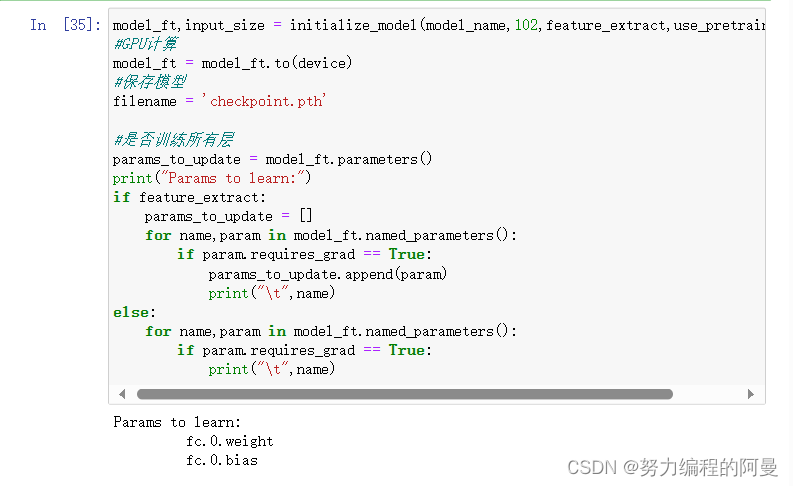
可以看到,只要全连接层的权重和偏差是需要学习的
对于优化器的设置
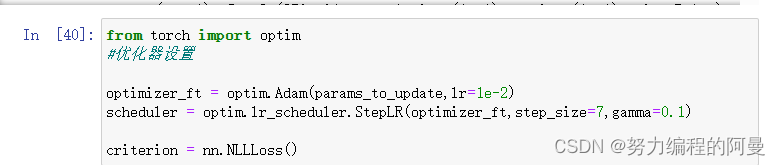
这里scheduler我们对于学习率进行了衰减,对于当前的学习器,每7步衰减为十分之一,然后损失函数有所改变,这是因为模型所导致的,因为这里主要是对于框架学习,所以不多阐述。
最好就是训练模块,首先需要的参数为:模型,数据集,损失函数,优化器,训练次数,(is_inception是是否选择其他的网络模型,由于这里参考的是pytorch官网所以这里保留,但是实际上用不到),和保存路径

最好是选择最好的一次模型参数copy到best_model_wts中
接下来是训练过程

最后,如果是在验证模式下发现了准确率更好的模型,则将此模型作为最好的模型进行保存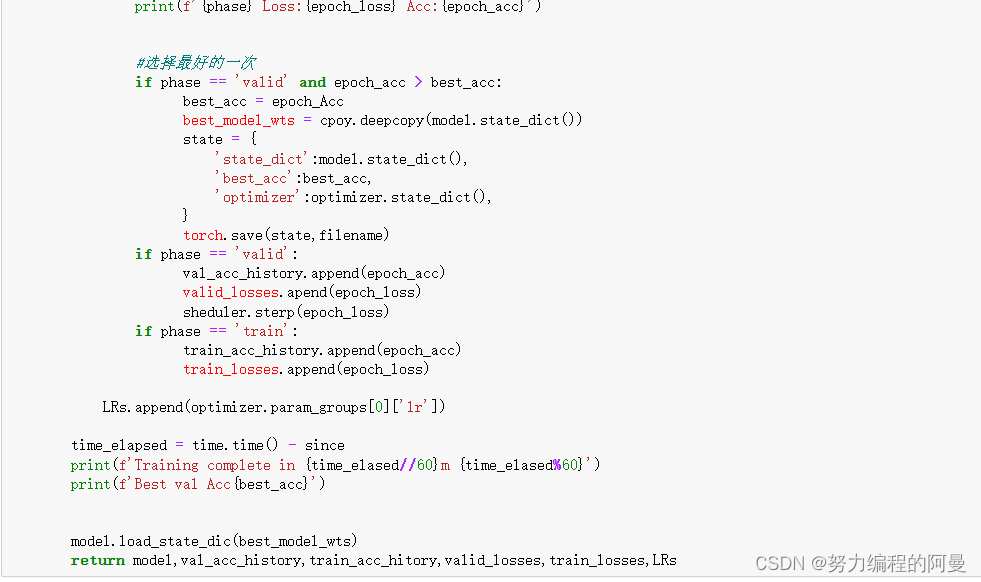
以上就是迁移学习的全过程。















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









