






先把xml转txt
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['mouse' ]
# 2、voc格式的xml标签文件路径
xml_files1 = 'mydata/annotations'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = 'mydata/labels'
convert_annotation(xml_files1, save_txt_files1, classes1)再分开训练集和验证集
import os
import random
import shutil
# 原始数据存放路径
data_dir = "mydata/"
images_dir = os.path.join(data_dir, "images")
labels_dir = os.path.join(data_dir, "labels")
# 划分后的训练集和验证集路径
train_dir = "mydata/train"
train_images_dir = os.path.join(train_dir, "images")
train_labels_dir = os.path.join(train_dir, "labels")
val_dir = "mydata/val"
val_images_dir = os.path.join(val_dir, "images")
val_labels_dir = os.path.join(val_dir, "labels")
# 创建训练集和验证集目录
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)
# 获取所有图片文件名
image_files = os.listdir(images_dir)
# 随机打乱文件列表
random.shuffle(image_files)
# 计算划分的数量
total_images = len(image_files)
train_ratio = 0.9
num_train = int(total_images * train_ratio)
# 将图片和标签文件划分到训练集和验证集
train_file_list = []
val_file_list = []
for i, image_file in enumerate(image_files):
label_file = image_file.replace(".jpg", ".txt")
if i < num_train:
# 划分到训练集
shutil.copy(os.path.join(images_dir, image_file), os.path.join(train_images_dir, image_file))
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(train_labels_dir, label_file))
train_file_list.append(os.path.join("train", "images", image_file))
else:
# 划分到验证集
shutil.copy(os.path.join(images_dir, image_file), os.path.join(val_images_dir, image_file))
shutil.copy(os.path.join(labels_dir, label_file), os.path.join(val_labels_dir, label_file))
val_file_list.append(os.path.join("val", "images", image_file))
# 创建train.txt和val.txt文件
with open(os.path.join(data_dir, "train.txt"), "w") as train_txt_file:
train_txt_file.write("\n".join(train_file_list))
with open(os.path.join(data_dir, "val.txt"), "w") as val_txt_file:
val_txt_file.write("\n".join(val_file_list))
print(f"划分完成,训练集包含 {num_train} 个样本,验证集包含 {total_images - num_train} 个样本。")
目录:
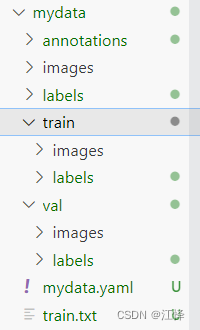
# 数据集配置文件
train: mydata/train/train.txt # 数据集里的训练集列表文件路径
val: mydata/val/val.txt # 数据集里的验证集列表文件路径
nc: 1 #类型数量
names: [ 'mouse' ] #类型名














 4125
4125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









