






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
为什么要搭建hbase ha?
搭建三节点的HBase HA,可支持自动故障转移,即集群中HMaster进程意外中断后,备用HMaster进程可自动完成切换,不影响用户数据操作。
搭建环境
搭建环境:hadoop3.3.1+hbase2.4.4+zookeeper3.5.10
虚拟机名称:master1, master2, slave 三节点
一、hbase是什么?
HBase是针对谷歌BigTable的开源实现,是一个高可靠,高性能,面向列,可伸缩的分布式是数据库,主要用于存储非结构化和半结构化的松散数据。HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。
二、使用步骤
1.安装包准备
1.hadoop-3.3.1.tar.gz
2.hbase-2.4.4-bin.tar.gz
3.apache-zookeeper-3.5.10-bin.tar.gz
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/
安装过程这里不再赘述可以参考我的上两篇文章的安装过程。
Hadoop安装
hbase安装
注意:只看安装过程即可,配置过程可以看下面的。
2.建立虚拟机
代码如下(示例):
- 首先先建立三个虚拟机 ,不需要一个一个创建,创建一个然后进行复制
注意:修改ip 地址,不然会出错。

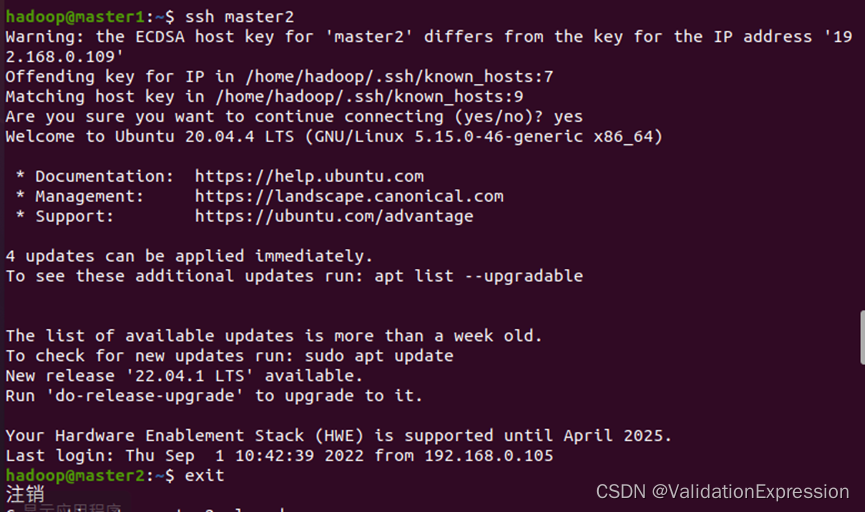
2.进入虚拟机,并修改各个主机名
—修改主机名sudo vim /etc/hostname //修改后需要重启虚拟机
改为桥接模式-查询ip—命令ifconfig—在写入ip如下命令
—进行三节点互通 //三节点都需配置
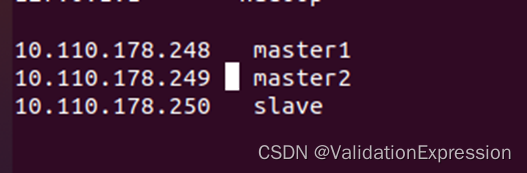
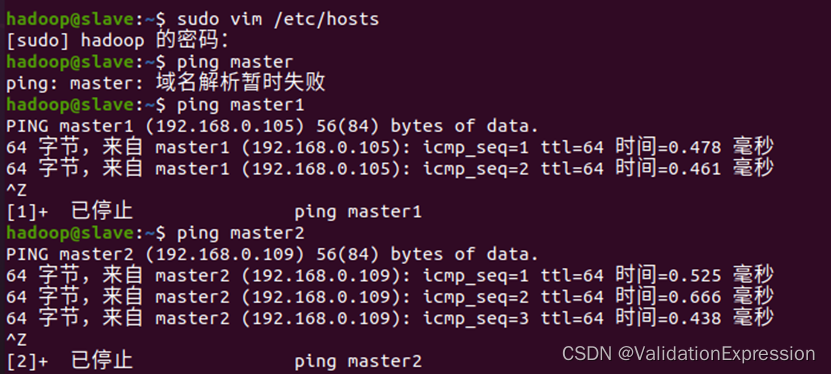
3.虚拟机之间可以相互ping通的准备
Master1

Master2
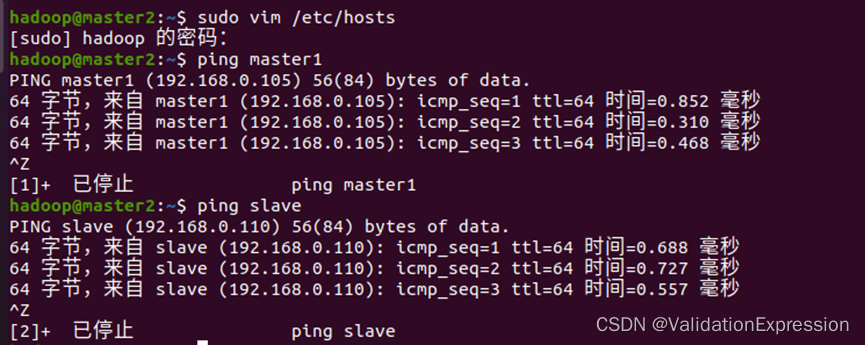
Slave
3.进行环境变量配置
- 进行环境配置sudo vim ~/.bashrc
结束后应使其生效source ~/.bashrc
# jdk
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=/usr/local/hadoop/bin:$PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lin/native
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# hbase
export HBASE_HOME=/usr/local/hbase
export PATH=${HBASE_HOME}/bin:$PATH
# hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
# zookeeper
export ZOOKEEPER_INSTALL=/usr/local/zookeeper/
export PATH=$PATH:$ZOOKEEPER_INSTALL/bin
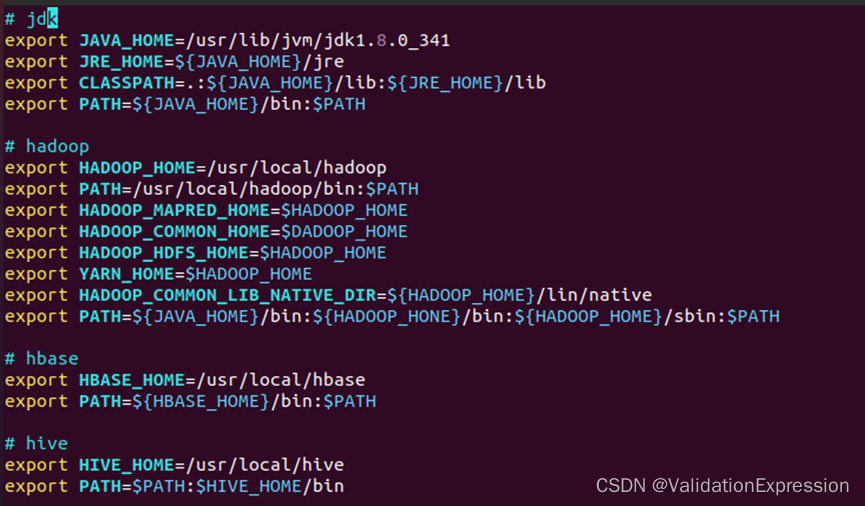

注意:三个节点都需相同配置
4.节点之间ssh免密登录
- 设置三个节点ssh免密登录
Master1 ,master2 可以ping通slave节点
Master1 和master2节点之间可以互相ping - 下载安装包
本地测试(exit退出)

- 生成公钥与私钥(一路回车)
–这个地方的截图忘记了
–大概方法如下,只需换成不同节点进行执行即可
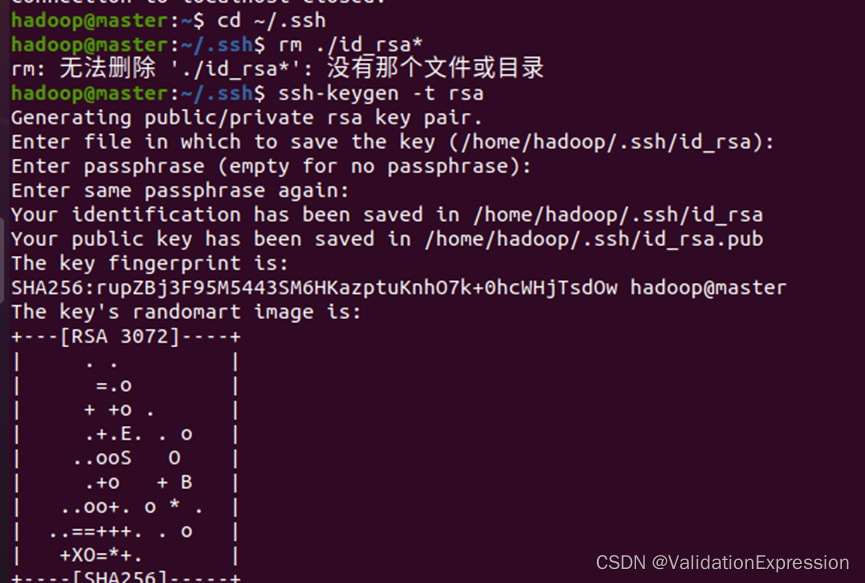
–进入后一路回车 - 密钥传输(注意两个虚拟机都应开着)
cat ./id_rsa.pub >> ./authorized_keys //将公钥放到autiorized_keys

–如果一个虚拟机没开则会出现

scp ~/.ssh/id_rsa.pub hadoop@slave:/home/hadoop //将meter节点到公钥复制到slave节点中
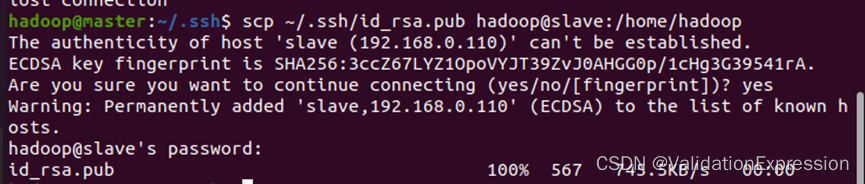
–可以查看是否传输成功—进入slave节点的目录下

5. 此时在slave节点虚拟机上操作
–输入mkdir ~/.ssh
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //密钥加入到slave节点
rm ~/id_rsa.pub //删除密钥文件
5.zookeeper安装
- 解压路径/usr/local

- 进入usr/local/zookeeper/conf安装目录下
–复制zoo_sample.cfg文件并修改名称为zoo.cfg;
Sudo mv zoo_sample.cfg zoo.cfg
由于我已经复制过了,这里展示结果。

修改zoo.cfg文件內容
Sudo vim zoo.cfg
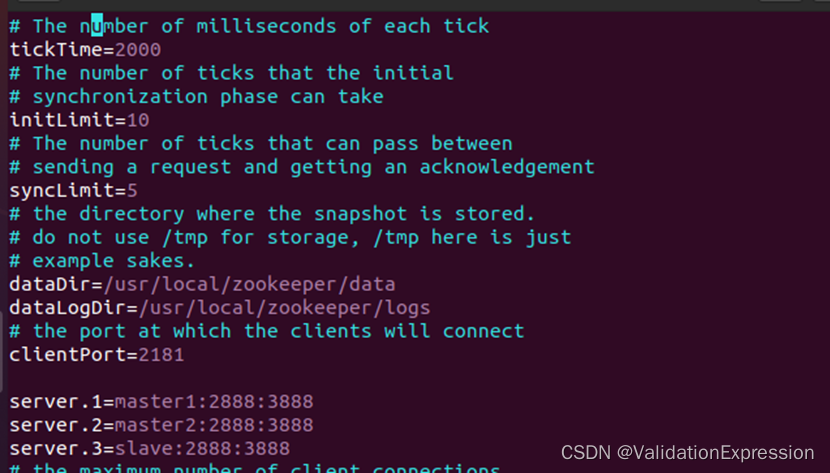
重要:以上配置在三个节点都需配置
可以利用文件打包发送到各个节点的方式(这里不再赘述)
在dataDir路径 /usr/local/zookeeper/data 创建myid文件
Sudo vim myid
//注意三个节点的myid文件內容不同按照上方配置的数字即可。

- 测试:三个节点都需启动(注意启动顺序:master1, master2 ,slave)


查看状态
zkServer.sh status



- 出现进程jps //三个节点都有

- 结束
zkServer.sh stop
6.Hadoop部署
1.配置Core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mtcluster</value>
<final>true</final>
</property>
<property>
<name>dfs.nameservices</name>
<value>mtcluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--zookeeper server的连接地址 hostname:端口,与zoo.cfg中一致-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slave:2181</value>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
2.配置重要:hdfs-site.xml
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mtcluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 ,这里给出了namenode,对后面起namenode进程及zookeeper主备切换都有作用-->
<property>
<name>dfs.ha.namenodes.mtcluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mtcluster.nn1</name>
<value>master1:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mtcluster.nn2</name>
<value>master2:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mtcluster.nn1</name>
<value>master1:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mtcluster.nn2</name>
<value>master2:50070</value>
</property>
<!--保存FsImage镜像的目录,即namenode里的metadata-->
<property>
<name>dfs.namenode.name.dir.mtcluster</name>
<value>/usr/local/hadoop/tmp/data01/nn</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;master2:8485;slave:8485/mtcluster</value>
</property>
<!-- journalnode 上用于存放edits日志的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/dfs/journalnode</value>
</property>
<!--开启HDS HA 实现namenode层的主备切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mtcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 这里添加shell(bin/true)>可以参看“相关引用”的第三条-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录,注意的是这里需要master1 和master2的双向
ssh-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master2:9001</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master1:9001</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.配置Mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
</configuration>
4.配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
</configuration>
- 修改worker文件(不同的版本可能不同slaves)
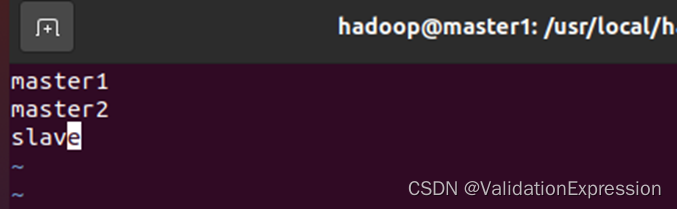 将如上Hadoop配置整体发送给各个节点
将如上Hadoop配置整体发送给各个节点
tar -xcf ~/hadoop.master.tar.gz ./hadoop
scp hadoop.master.tar.gz hadoop@master2:/home/hadoop
scp hadoop.master.tar.gz hadoop@slave:/home/hadoop
7.Hbase部署
1.我的解压路径/usr/local
将hadoop中的hdfs-site.xml复制到HBase的conf路径下
sudo cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/
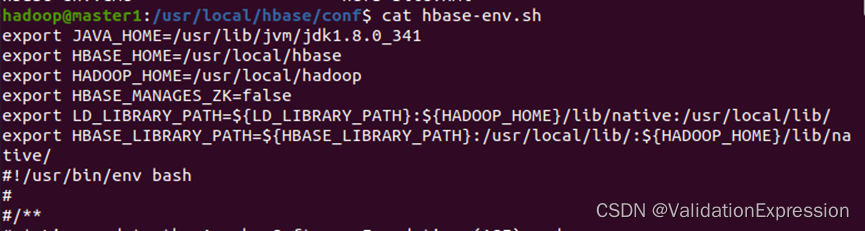
 2. 配置hbase-env.sh
2. 配置hbase-env.sh
在这里我只是查看了,需进入sudo vim hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export HBASE_HOME=/usr/local/hbase
export HADOOP_HOME=/usr/local/hadoop
export HBASE_MANAGES_ZK=false
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${HADOOP_HOME}/lib/native:/usr/local/lib/
export HBASE_LIBRARY_PATH=${HBASE_LIBRARY_PATH}:/usr/local/lib/:${HADOOP_HOME}/lib/native/
3.配置hbase-site.xml
<property>
<name>hbase.rootdir</name>
<!--mucluster集群名称,与hadoop中的配置保持一致-->
<value>hdfs://mtcluster/user/hbase</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/data01/hbase/hbase_tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/data01/hbase/zookeeper_data</value>
</property>
<property>
<name>hbase.master.port</name>
<value>61000</value>
</property>
<!--hbase的web页面-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1,master2,slave</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
- 配置regionservers
添加
Master1
Master2
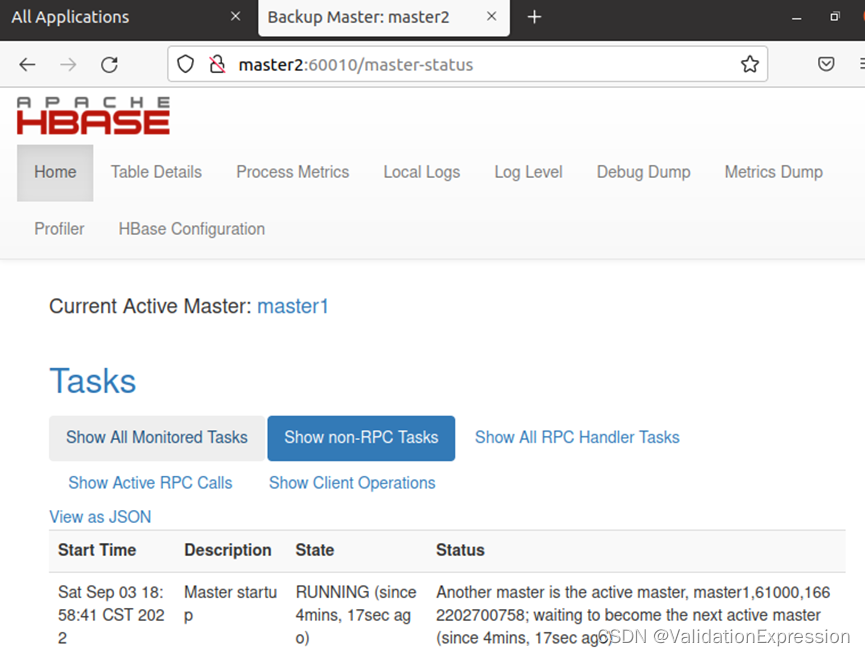
Slave - 在/usr/local/hbase/conf路径创建backup-masters
表示备用master节点,执行的适合,也会在该节点运行HMaster进程
master2
8.集群启动
- -三个节点zk的QuorumPeerMain进程已正常启动
- 启动JournalNode服务(三个节点)//注意改变目录
Master1
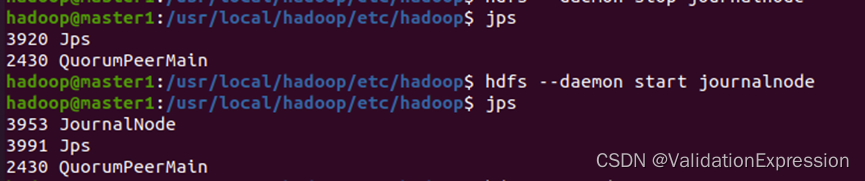
Master2

Slave

- 启动hadoop
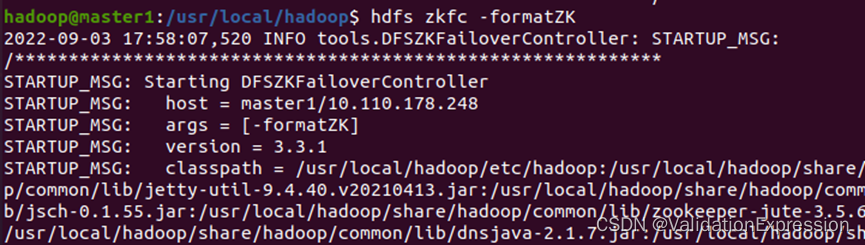
先进行初始化(主节点master1)

进行zkfc初始化
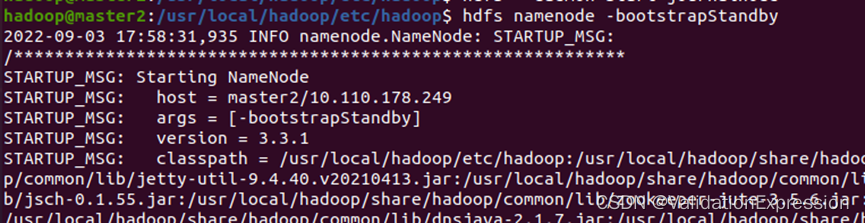
 4. 节点master2操作
4. 节点master2操作
执行fsimge元数据同步命令
- 启动DFSZKFailoverController进程(master1,master2节点)
hdfs --daemon start zkfc
master1

Master2

- 主节点进行master1
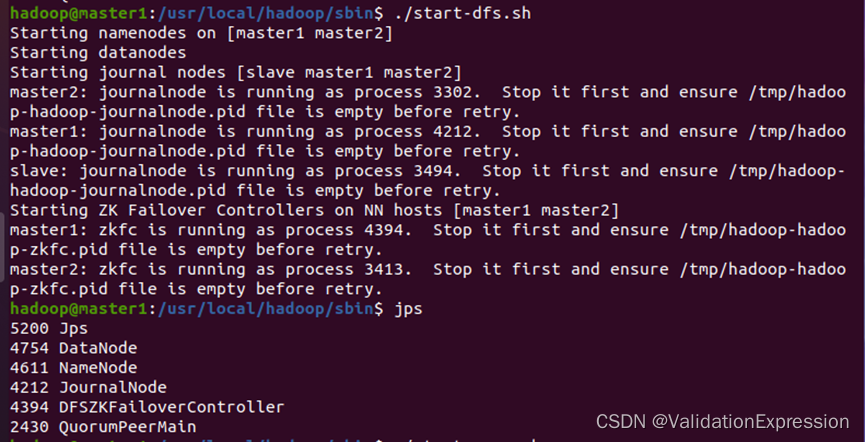
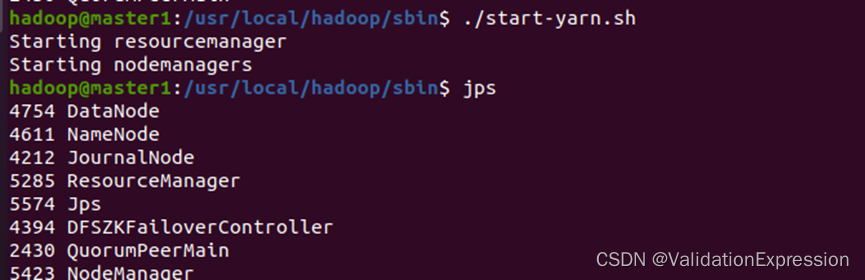
Master2
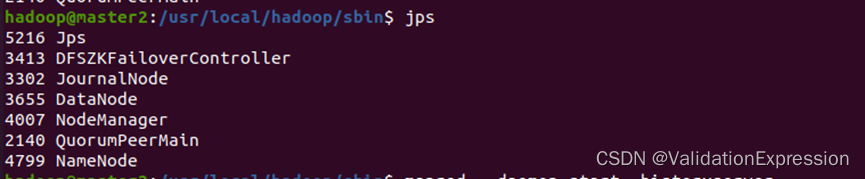
- Application(job)History进程服务(master1, master2 节点)

- 在Web页面验证
Master1
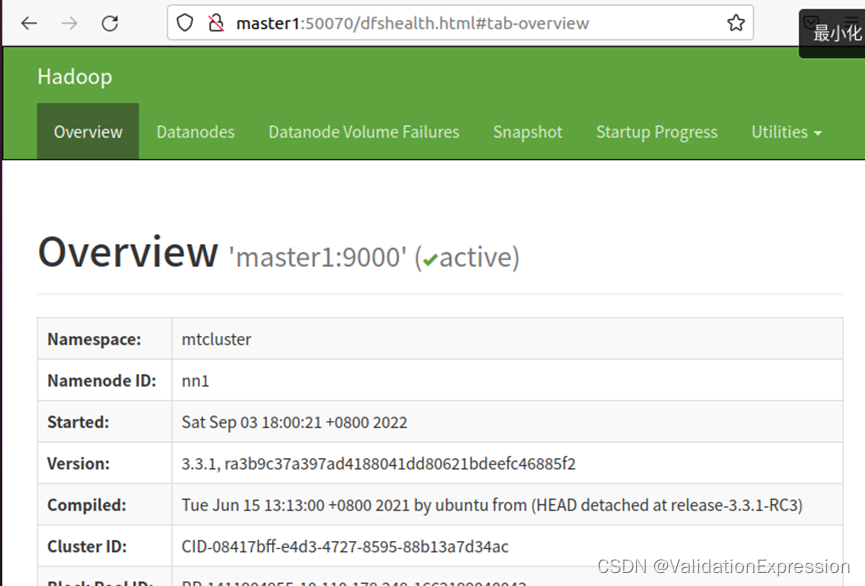
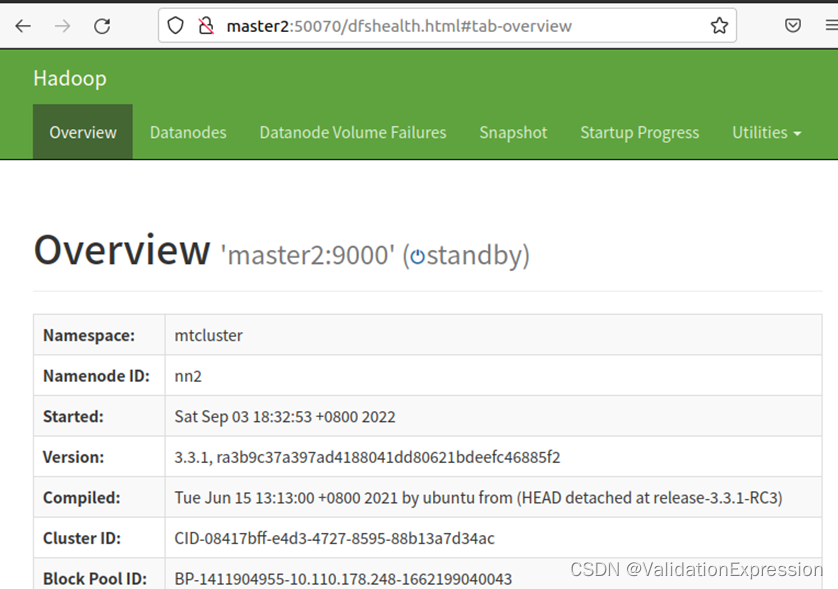
9.启动hbase
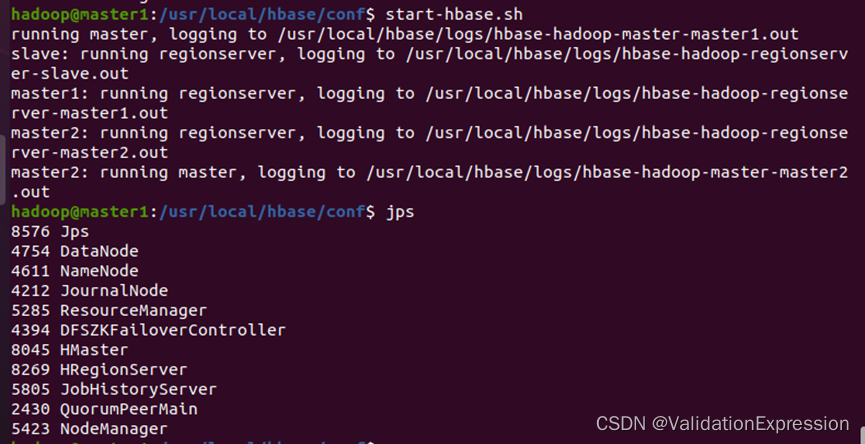
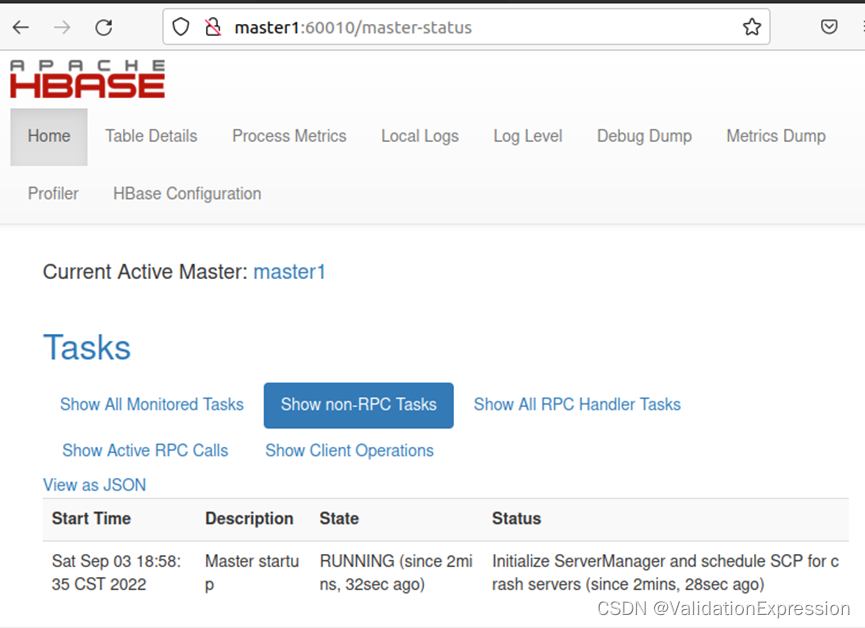
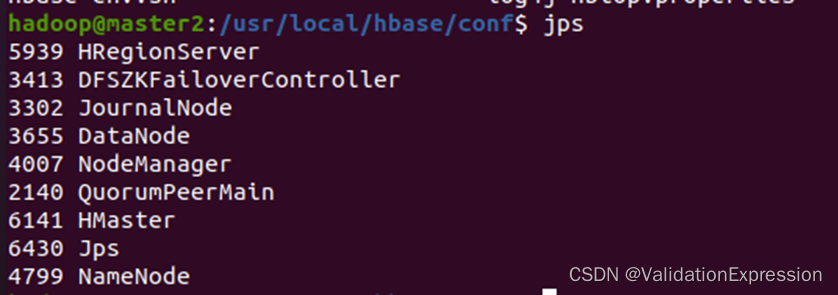
Master2
总结
新手创作,文章有什么问题欢迎大佬指点。















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









