






Hadoop3.3.1安装与配置(两个节点master,slave)
- 安装VM virtulBox软件(用于创建虚拟机)
链接: https://www.virtualbox.org/wiki/Downloads
选择你要下载的VM virtulBox虚拟机

2. 下载镜像文件用于加载虚拟机
----可以选择国内的一些镜像网站–清华大学镜像网站
百度网盘
链接:https://pan.baidu.com/s/1x9IHwEmx9t2g7M3CDybxzA
提取码:xong
3.进行一系列软件安装(不在赘述…)
4.创建虚拟机(此处我已经创建了了):master
-点击新建
-名称
-位置(尽量选择较大的盘)
-类型:Linux
-版本:ubuntu(64)
然后分配内存根据你的电脑配置适当分配即可
选项保持不变即可
稍微分配多点,因为是动态分配的,避免以后因为硬盘存储不够而重装ubuntu
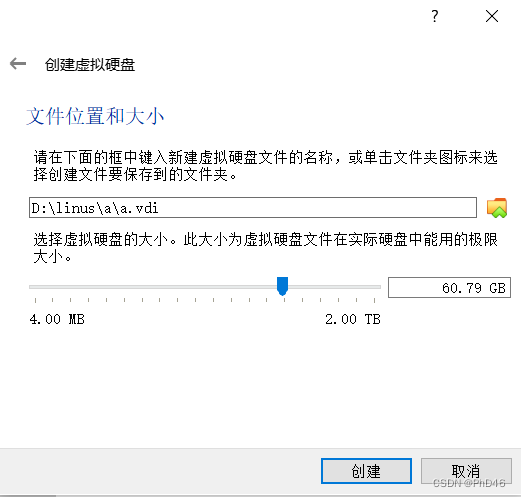
最终创建成功(第二个节点可以先不用创建,可以在master节点配置完成后进行复制)
点击启动
-选择语言
-点击安装
-按照指示进行安装即可(此过程较慢请耐心等待…)
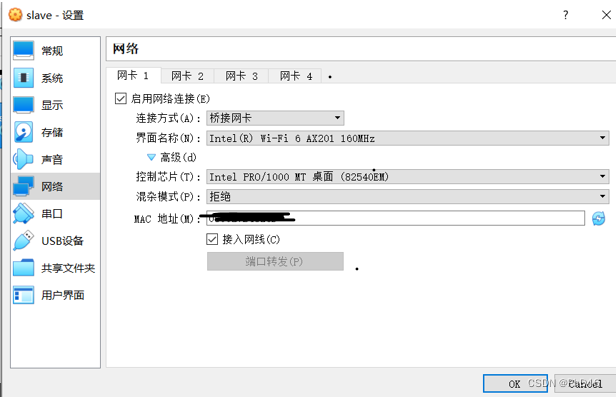
4. 复制虚拟机slave节点(注意更改ip地址,不然会造成连接不通的错误)
–记着对slave节点进行改名
-再打开slave节点
结束启动即可
起始工作创建用户,建立ssh连接,下载jdk.
- Hadoop在Ubuntu环境下的部署可以细分为以下五个部分,分别为:虚拟机网络配置、Java环境配置、SSH配置、Hadoop安装配置以及Hadoop的启动停止。
- 先创建一个hadoop用户以便后面使用。
- sudo useradd -m hadoop -s /bin/bash
- sudo passwd hadoop // 为"hadoop"用户设置密码;
- sudo adduser hadoop sudo //为"hadoop"用户添加管理员权限;
- 注销当前用户,使用"hadoop"用户登录。
-
虚拟机网络配置
-首先我们需要在Ubuntu安装net工具,执行 sudo apt install net-tools,之后可以使用ifconfig命令,查看当前节点的网络网卡信息;进入终端(注意切换到桥接模式)
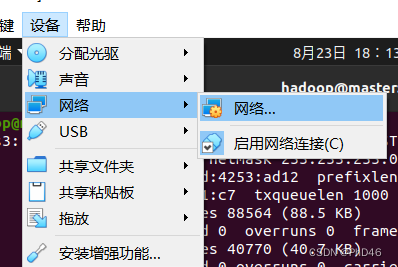
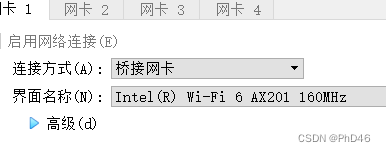
在slave节点也是如此。
-使用ifconfig前需更新一下 sudo apt install net-tools
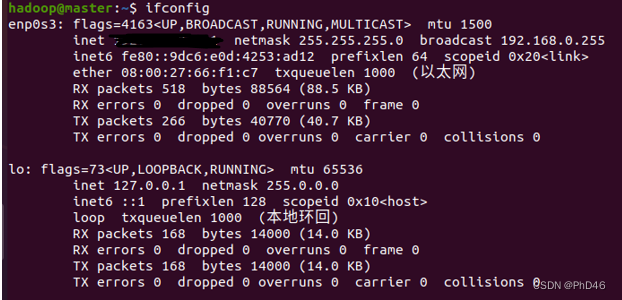
-
更新和安装apt,vim编辑器。
-sudo apt-get update
-sudo apt-get install vim -
安装SSH和配置SSH无密码登录。
-先进行master和slave互通
-sudo vim /etc/hosts
-master和slave都需配置
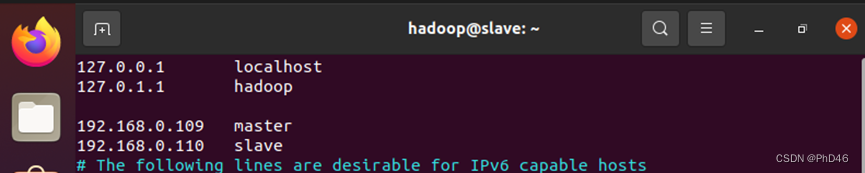
-
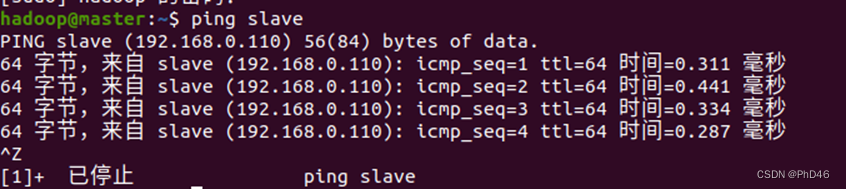
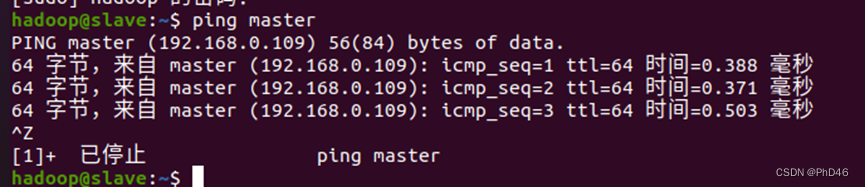
检验是否连接成功利用ping master或ping slave分别在不同的虚拟机上。
8.安装jdk
-在oracle官网下载jdk1.8.xx(账号密码可以在csdn上直接搜索即可有共享的)
-以上准备完成后 -
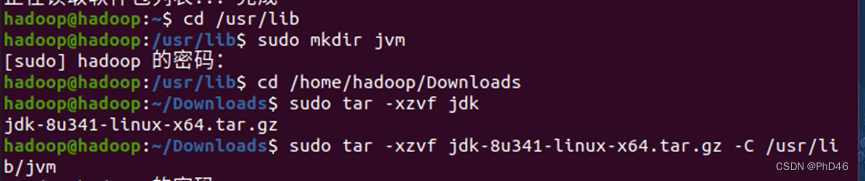
进入终端
-创建一个文件夹`
-并将jdk安装包解压到你创建文件的位置
-配置jdk文件

-写入命令source ~/.bashrc使配置文件生效
最后检查是否成功java -version

-
进行ssh免密登录操作
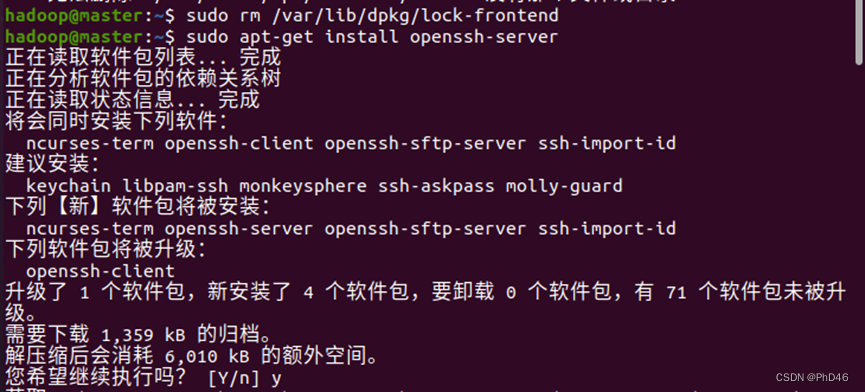
-下载sudo apt-get install openssh-server
出现问题

-可以利用命令(如果出现不同的原因可以直接复制出错的原因在网上搜索)
 -再次尝试
-再次尝试
-
ssh localhost实现本地登录
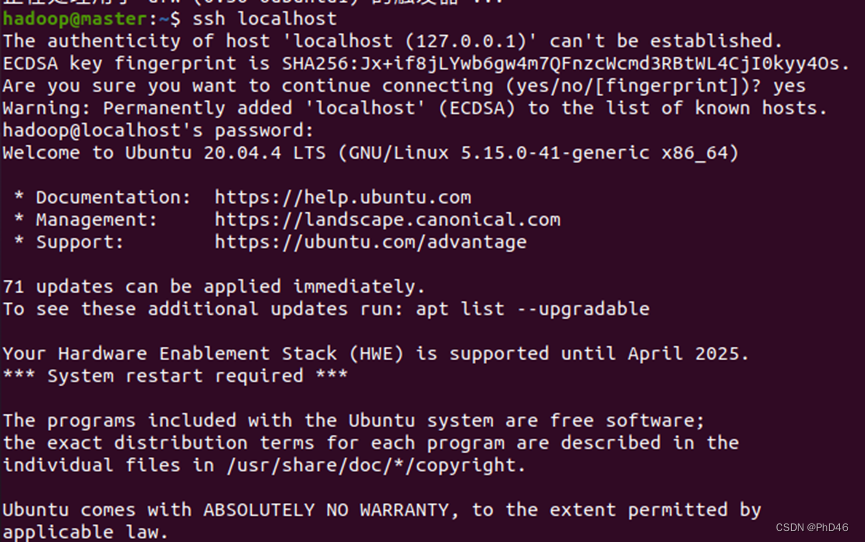
最后利用命令exit退出ssh -
ssh密钥生成,进入后一路回车即可
-rm ./id_rsa* //删除以前产生的密钥
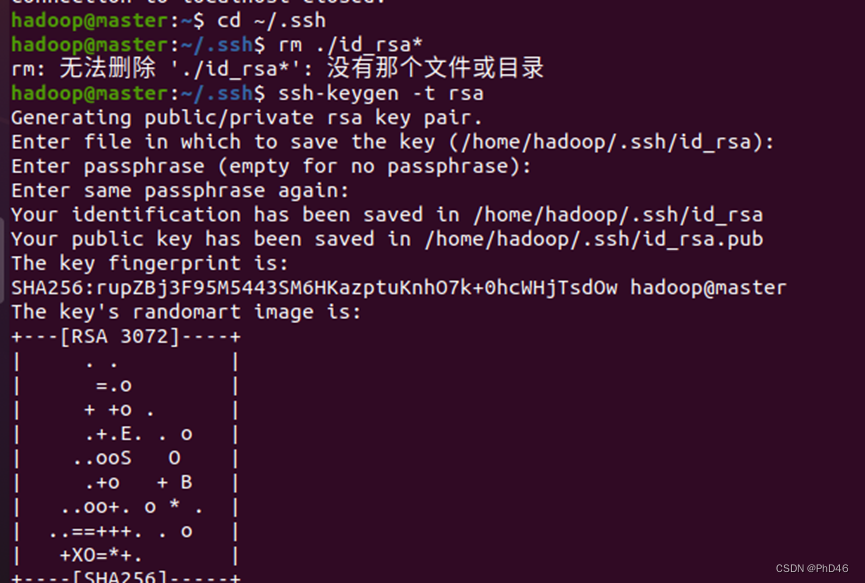
-
密钥传输(注意两个虚拟机都应开着)
-cat ./id_rsa.pub >> ./authorized_keys //将公钥放到autiorized_keys中
 如果一个虚拟机没开则会出现
如果一个虚拟机没开则会出现

-scp ~/.ssh/id_rsa.pub hadoop@slave03:/home/hadoop //将master节点到公钥复制到slave节点中
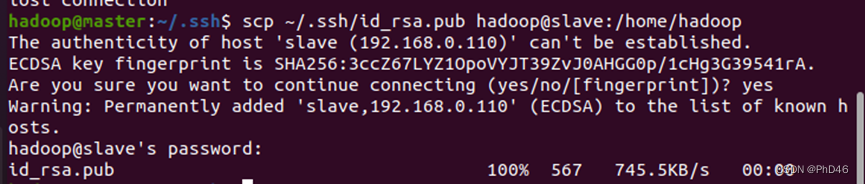
-可以查看是否传输成功—进入slave节点的目录下

12. .此时在slave节点虚拟机上操作
-输入mkdir ~/.ssh
-cat ~/id_rsa.pub >> ~/.ssh/authorized_keys //密钥加入到slave节点
-rm ~/id_rsa.pub //删除密钥文件
13. .回到master节点在终端进行测试
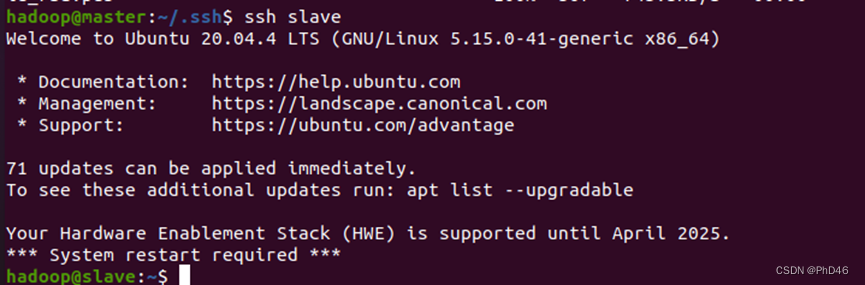
hadoop安装与配置
- 下载安装包在国内镜像网站https://mirrors.tuna.tsinghua.edu.cn/apache/Hadoop/common/Hadoop-3.3.1
- sudo tar -zxf~/download/hadoop-3.3.1.tar.gz -C /usr/lcoal //将Hadoop解压到/usr/lcoal下
cd /usr/local
sudo mv ./hadoop-3.3.1 ./hadoop //修改文件名为hadoop
sudo chown -R hadoop ./hadoop //修改文件权限

- 配置Hadoop文件
-sudo vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME= H A D O O P H O M E e x p o r t H A D O O P C O M M O N H O M E = HADOOP_HOME export HADOOP_COMMON_HOME= HADOOPHOMEexportHADOOPCOMMONHOME=HADOOP_HOME
export HADOOP_HDFS_HOME= H A D O O P H O M E e x p o r t Y A R N H O M E = HADOOP_HOME export YARN_HOME= HADOOPHOMEexportYARNHOME=HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR= H A D O O P H O M E / l i n / n a t i v e e x p o r t P A T H = {HADOOP_HOME}/lin/native export PATH= HADOOPHOME/lin/nativeexportPATH={JAVA_HOME}/bin: H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin:$PATH
-配置后需生效source ~/.bashrc

版本信息
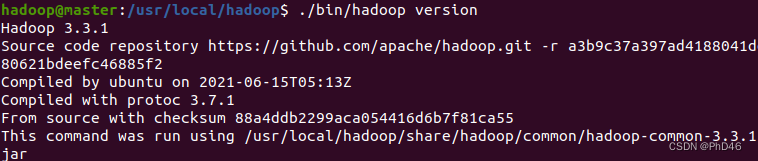
- 在usr/local/Hadoop/etc/hadoop目录下配置
-sudo vim core-site.xml
fs.defaultFS
hdfs://master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abasefor other temporary directories.
hadoop.proxyuser.spark.hosts
hadoop.proxyuser.spark.groups
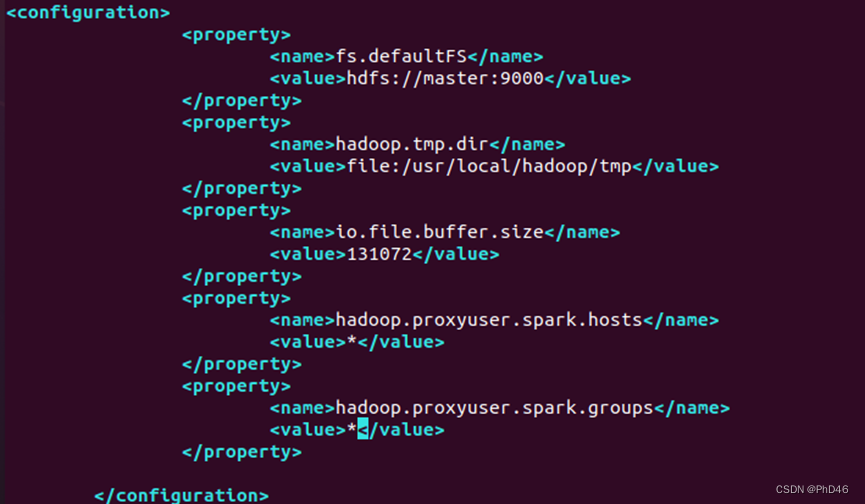
hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/usr/local/hadoop/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/dfs/data
dfs.replication
1(因为配置的为1个节点所以写1)
dfs.webhdfs.enabled
true
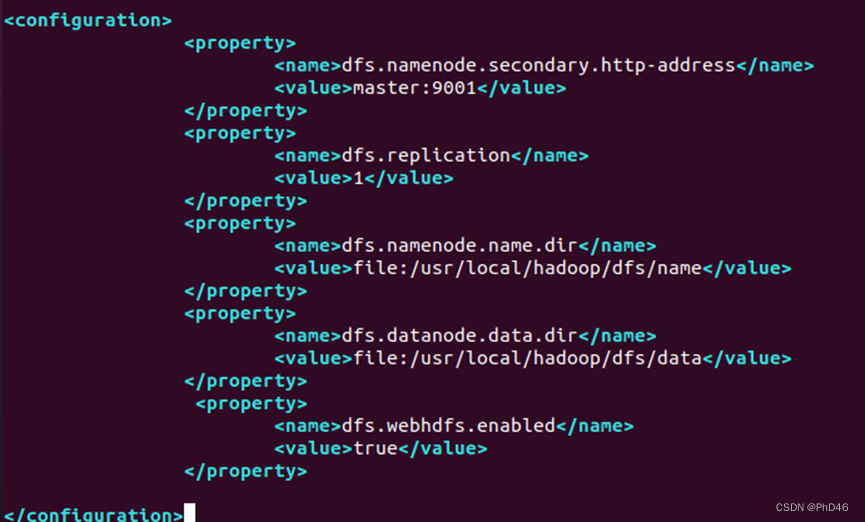
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8035
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
mapred-site.xml不同的版本可能有mapred-site.xml.template
可以重命名cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
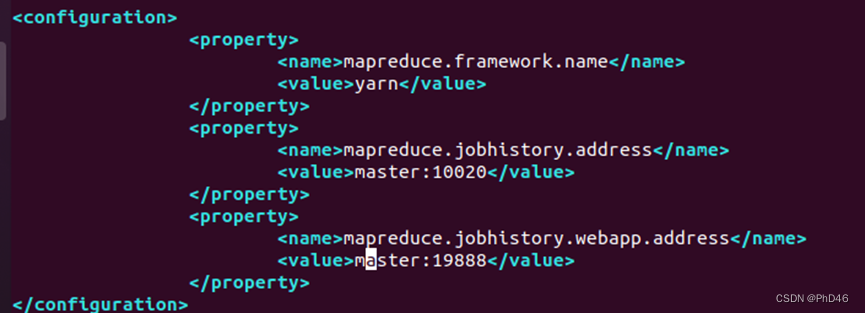
6. 注意修改workers文件有的版本可能有不同的利用ls 查看。
-修改文件—localhost改为 你的另一个节点名称slave(如果有两个则写两个)

两节点传输安装包
- 将master节点的hadoop文件进行压缩到主目录下(将master节点的安装包传到slave节点)

-将压缩的hadoop压缩包传输到slave节点

- 转到slave节点进行解压文件

- 查看hadoop版本
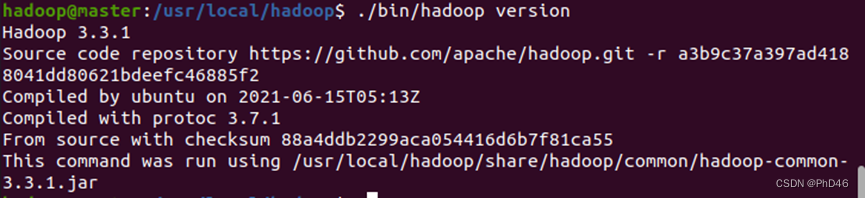
- hadoop启动
-先进行初始化-在/usr/local/Hadoop 目录下 ./bin/hdfs namenode -format
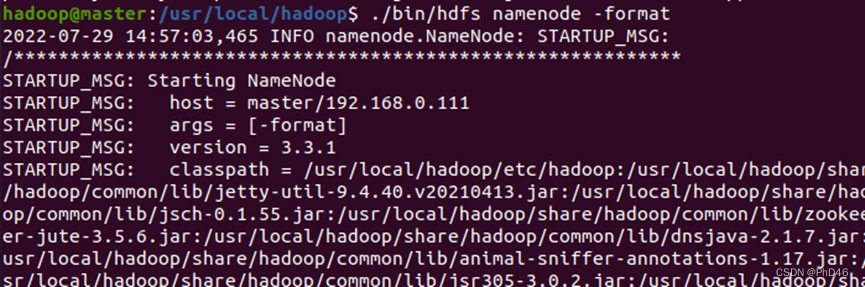
(如果你运行过后面Hadoop启动时有错误记得删除tmp文件下的所有文件,防止再次启动时不显示datanode)
-启动start-dfs.sh
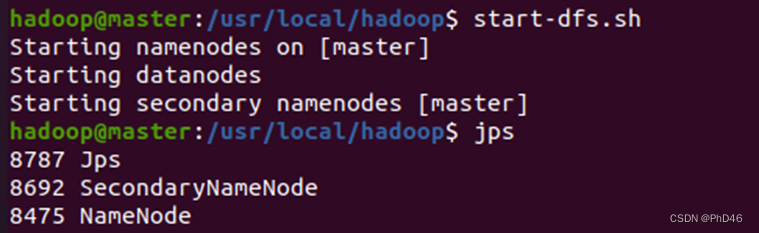
-start-yarn.sh
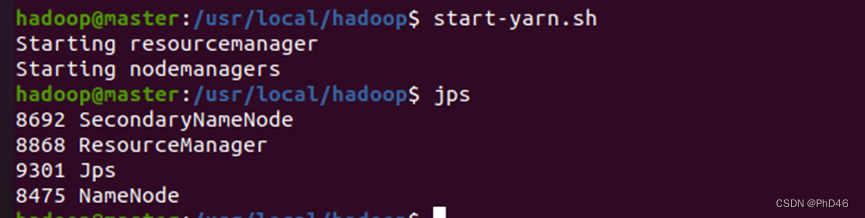
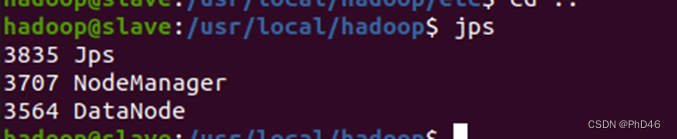
-4.查看slave节点jps状态
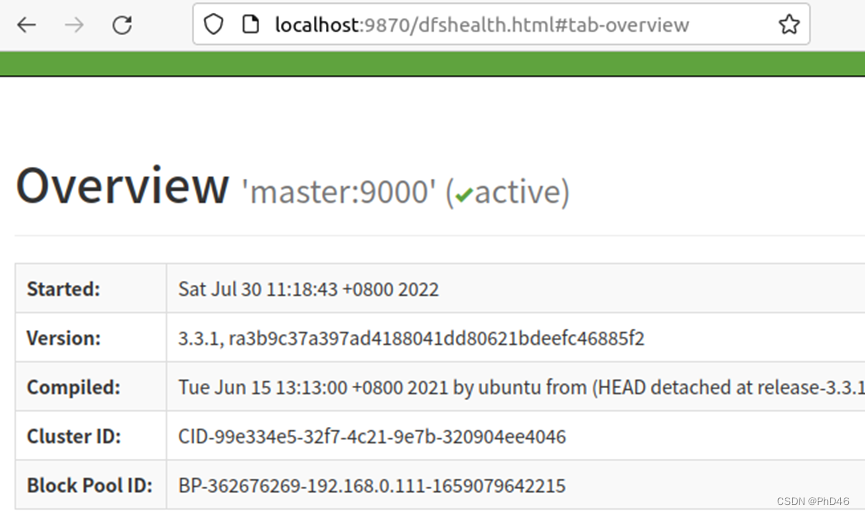
-5.输入http://localhost:9870 显示(前提hadoop启动)
可能出现的错误
1.错误一

用于2022-07-29 …
可以直接在文件中找/usr/local/hadoop/etc/hadoop/log4j.properties文件加上一句
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
(注:此错误可以忽略)
2. 错误2

注意你的虚拟机连接模式(桥接模式)
3.如果还是启动不了—注意你的Hadoop配置文件(两个节点都需要查看)














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









