







系列文章目录
第一章 HQL表创建
第二章 HQL初级练习1
第三章 HQL初级练习2
第四章 HQL中级练习1
第五章 HQL中级练习2
第六章 HQL中级练习3
前言
这里HQL的高级练习,用于复习巩固sql常用的函数等使用方法,还有个人分析问题的思路(仅供参考)
----创建表sql资源(如上)
一、习题练习
1. 同时在线人数问题
- 表说明: 现有各直播间的用户访问记录表(live_events)如下,表中每行数据表达的信息为,一个用户何时进入了一个直播间,又在何时离开了该直播间。
用户id-----------------------直播间id---------------用户进入直播间的时间-----------离开直播间的时间
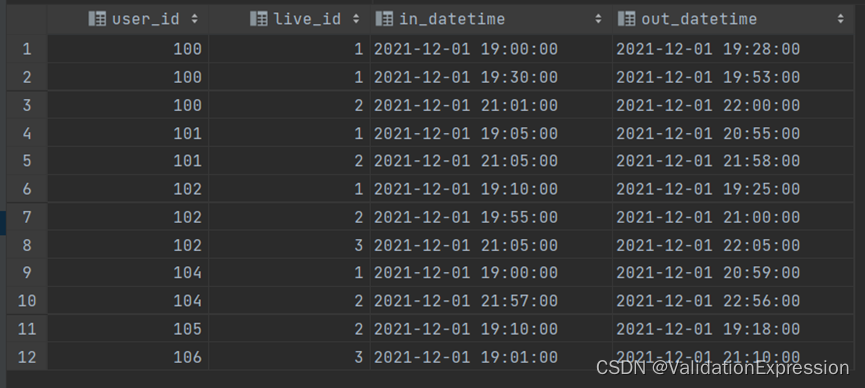
- 需求: 统计各直播间最大同时在线人数.
- 分析题意: 一个用户在同一个直播间,只能退出后才能再次进入. 一个用户进入直播间,人数+1,退出直播间人数-1, 根据这个情况按照进入直播间退出直播间的时间进行排序,并设置一个标签来代表此时是进入还是退出. 在使用窗口函数进行统计直播间的人数. 最后取最大即可.
- 函数介绍:
- 用于将连个表的数据进行上下拼接,(连接两个表的字段要一一对应).
Union : 去重
Union all :不去重- sum() over () : 窗口函数,求和.
代码演示
--第一步: 将登录和登出分离,这里使用的user_change: 表示的是用户是进入了直播间还是退出了
select user_id,live_id,in_datetime, 1 user_change from live_events
union --这里使用union和union all的结果一样,原因一个用户的登录和登出一定不会一样,如果没有user_id这个字段,就需要使用union all不能进行去重,(原因就是同一时刻可能有多人进入)
select user_id,live_id,out_datetime, -1 user_change from live_events;
--第二步: 使用窗口函数计算user_change人数
select t1.user_id,
t1.live_id,
--求和,按照live_id进行分区,按照(1)的时间进行排序, 从最开始到当前行数据.
sum(t1.user_change)over (partition by t1.live_id order by t1.in_datetime rows between unbounded preceding and current row ) user_sum
from (
select user_id, live_id, in_datetime, 1 user_change
from live_events
union
select user_id, live_id, out_datetime, -1 user_change
from live_events
)t1;
----使用hive+ spark可能会出现超时的情况,执行这个可以解决.
set hive.vectorized.execution.enabled=false;
--第三步: 找到上述user_sum最大的那个指
select t2.live_id,
max(t2.user_sum)
from (
select t1.user_id,
t1.live_id,
sum( t1.user_change )
over (partition by t1.live_id order by t1.in_datetime rows between unbounded preceding and current row ) user_sum
from (
select user_id, live_id, in_datetime, 1 user_change
from live_events
union
select user_id, live_id, out_datetime, -1 user_change
from live_events
) t1
---对直播间进行分区,找到最大的那个人数.
) t2 group by t2.live_id;
结果展示
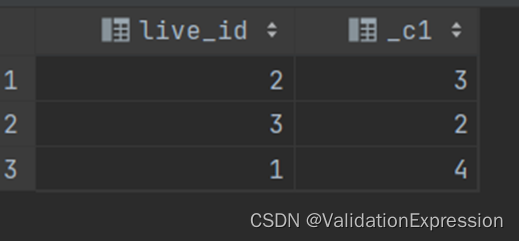
2. 会话划分问题
- 表说明: 现有页面浏览记录表(page_view_events)如下,表中有每个用户的每次页面访问记录.
用户id----------------------------------用户访问的页面-----------------访问时间
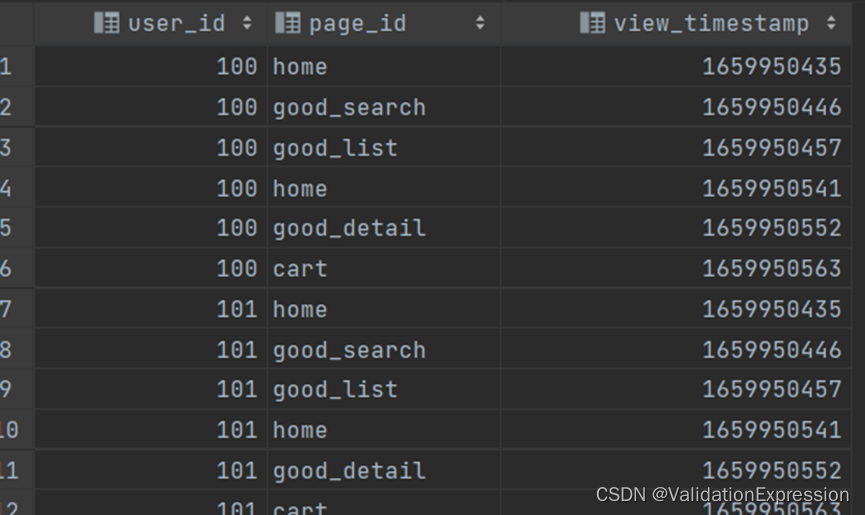
- 需求: 规定若同一用户的相邻两次访问记录时间间隔小于60s,则认为两次浏览记录属于同一会话。现有如下需求,为属于同一会话的访问记录增加一个相同的会话id字段.
- 分析题意: 主要就是根据条件,设置一个对应的标签. (1)先使用窗口函数,求出当前行的上一行数据的时间,间接可以求出相邻两次的访问时间间隔, 根据和60s比较得出一个标签. 然后再按照需要进行相应的拼接操作.
- 函数介绍:
- lag()over(): 求当前行的上一行数据.
- concat(): 字符串的拼接
代码演示
--第一步: 窗口函数,求当前行上一行数据,before_time表示的是当前行上一次访问时间
select user_id,page_id,view_timestamp,
lag(view_timestamp,1,0) over (partition by user_id order by view_timestamp) before_time
from page_view_events;
--第二步: view_timestamp- next_time <60 为同一会话
select t1.user_id,
t1.page_id,
t1.view_timestamp-t1.before_time vb
from (
select user_id,
page_id,
view_timestamp,
lag( view_timestamp , 1,0 ) over (partition by user_id order by view_timestamp ) before_time
from page_view_events
)t1;
--第三步: 找到<60的,设置标签,这里使用if(>60)原因,当vb时间>60的时候说明这个时间是不同会话的起始页面,从而达到一个标签会话的递增效果.
--same_conversational=1表示它是一个起始页面,也就是一个会话的开始
select t2.user_id,
t2.page_id,
`if`(t2.vb > 60 , 1, 0) same_conversational
from (
select t1.user_id,
t1.page_id,
t1.view_timestamp-t1.before_time vb
from (
select user_id,
page_id,
view_timestamp,
lag( view_timestamp , 1,0 ) over (partition by user_id order by view_timestamp ) before_time
from page_view_events
) t1
)t2 ;
---第三步: 拼接
select t3.user_id,
t3.page_id,
--使用sum会计算每一个会话的开始,进而达到会话递增的效果.
concat(t3.user_id,"-",sum(t3.same_conversational)over (partition by t3.user_id order by t3.view_timestamp)) cat
from (
select t2.user_id,
t2.page_id,
t2.view_timestamp,
`if`( t2.vb > 60 , 1 , 0 ) same_conversational
from (
select t1.user_id,
t1.page_id,
t1.view_timestamp,
t1.view_timestamp-t1.before_time vb
from (
select user_id,
page_id,
view_timestamp,
lag( view_timestamp , 1,0 )
over (partition by user_id order by view_timestamp ) before_time
from page_view_events
) t1
) t2
)t3;
结果展示
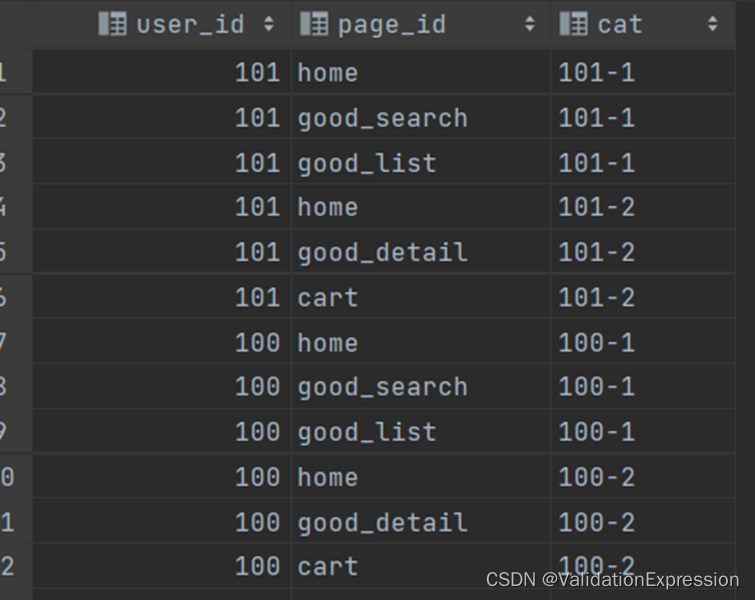
3. 间断连续登录用户问题
- 表说明:现有各用户的登录记录表(login_events)如下,表中每行数据表达的信息是一个用户何时登录了平台.
用户id--------------------------------------------------用户登录的时间
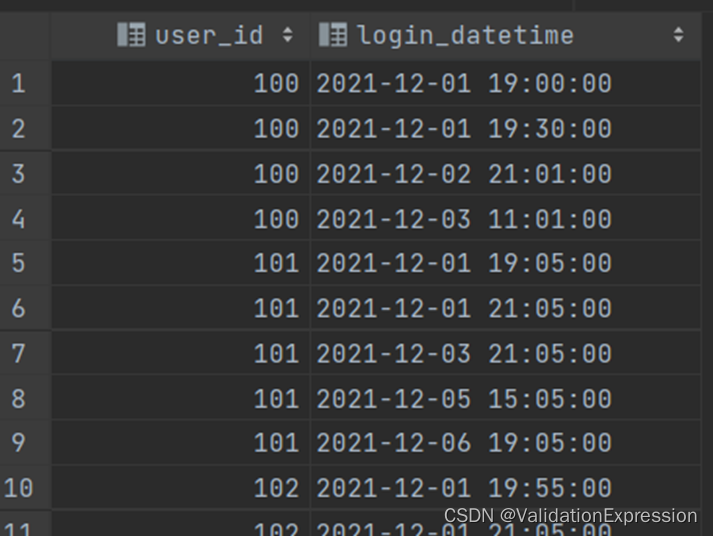
- 需求: 现要求统计各用户最长的连续登录天数,间断一天也算作连续,例如:一个用户在1,3,5,6登录,则视为连续6天登录.
- 分析题意: 本题的解决方法和第二题的解决思路类似,只是条件不同了,也可以使用划分的方法解决,就是将上述<60s的条件,换成当天到上一天的时间查<=2天. 只是这里多最后一步,划分后,找到一个会话的最大值和最小值,之间的差值就是连续登录的天数. 然后找到最大的那个.
- 函数介绍
- datediff(A,B): 用户计算A,B的时间查,返回的是天.
- lag()over(): 窗口函数,得到上行的数据.
- lead()over(): 窗口函数,得到下行的数据.
代码演示
--第一步: 先格式化时间并进行去重,就是由于有的用户在同一天登录多次的情况
select distinct user_id,to_date(login_datetime) login_date from login_events;
--第二步: 使用窗口函数获取前一行数据,并得到差值
select t1.user_id,
t1.login_date,
lag(t1.login_date,1,'1970-01-01') over (partition by t1.user_id order by t1.login_date) before_date,
datediff(t1.login_date,lag(t1.login_date,1,'1970-01-01') over (partition by t1.user_id order by t1.login_date)) df
from (
select distinct user_id, to_date( login_datetime ) login_date from login_events
)t1;
--第三步: 根据第二题的方式设置标签,same_conversational=1为一个标签的开始
select t2.user_id,
t2.login_date,
`if`(t2.df>2,1,0) same_conversational
from (
select t1.user_id,
t1.login_date,
datediff( t1.login_date , lag( t1.login_date , 1 , '1970-01-01' )
over (partition by t1.user_id order by t1.login_date) ) df
from (
select distinct user_id, to_date( login_datetime ) login_date from login_events
) t1)t2;
--第四步: 设置会话标签
select t3.user_id,
t3.login_date,
concat( t3.user_id , '-' ,
sum( t3.same_conversational ) over (partition by t3.user_id order by t3.login_date) ) cat
from (
select t2.user_id,
t2.login_date,
`if`( t2.df > 2 , 1 , 0 ) same_conversational
from (
select t1.user_id,
t1.login_date,
datediff( t1.login_date , lag( t1.login_date , 1 , '1970-01-01' )
over (partition by t1.user_id order by t1.login_date) ) df
from (
select distinct user_id, to_date( login_datetime ) login_date from login_events
) t1) t2
)t3;
--第五步: 根据标签,获取到一个标签内的最大值和最小值,做差就得到了一个标签内的连续登录天数,
select t4.user_id,
min(t4.login_date) min_time,
max(t4.login_date) max_time
from (
select t3.user_id,
t3.login_date,
concat( t3.user_id , '-' ,
sum( t3.same_conversational ) over (partition by t3.user_id order by t3.login_date) ) cat
from (
select t2.user_id,
t2.login_date,
`if`( t2.df > 2 , 1 , 0 ) same_conversational
from (
select t1.user_id,
t1.login_date,
datediff( t1.login_date , lag( t1.login_date , 1 , '1970-01-01' )
over (partition by t1.user_id order by t1.login_date) ) df
from (
select distinct user_id, to_date( login_datetime ) login_date from login_events
) t1) t2
) t3
) t4 group by t4.user_id,t4.cat;
--第六步: 但是这里会存在一个用户有两个标签都连续登录了,所以这里还要对用户和标签进行分组,找到dd最大的那个.
select t6.user_id,
max( t6.dd ) max_count
from (
select t5.user_id,
datediff( t5.max_time , t5.min_time ) + 1 dd --这里最大-最小的天数一定要+1
from (
select t4.user_id,
min( t4.login_date ) min_time,
max( t4.login_date ) max_time
from (
select t3.user_id,
t3.login_date,
concat( t3.user_id , '-' ,
sum( t3.same_conversational )
over (partition by t3.user_id order by t3.login_date) ) cat
from (
select t2.user_id,
t2.login_date,
`if`( t2.df > 2 , 1 , 0 ) same_conversational
from (
select t1.user_id,
t1.login_date,
datediff( t1.login_date ,
lag( t1.login_date , 1 , '1970-01-01' )
over (partition by t1.user_id order by t1.login_date) ) df
from (
select distinct user_id, to_date( login_datetime ) login_date
from login_events
) t1) t2
) t3
) t4
group by t4.user_id, t4.cat
) t5
) t6
group by t6.user_id;
结果展示:
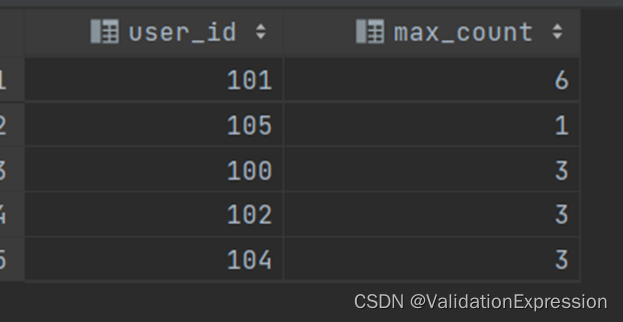
4. 日期交叉问题
- 表说明: 现有各品牌优惠周期表(promotion_info)如下,其记录了每个品牌的每个优惠活动的周期,其中同一品牌的不同优惠活动的周期可能会有交叉.
优惠周期id----------------------------品牌----------------------开始时间-----------------------结束时间
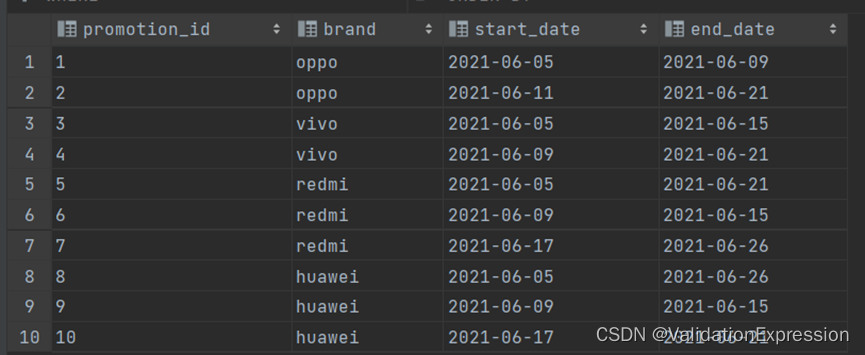
- 需求: 统计每个品牌的优惠总天数,若某个品牌在同一天有多个优惠活动,则只按一天计算.
- 分析题意:
1.分析可能出现的情况:
(1) 两个时间都独立oppo, (2)两个时间存在交叉时间关系,但是不是包含vivo,
(3) 时间存在包含,且存在跨行交叉redmi, (4)时间有交叉,有独立.
解决方案: 存在交叉(但是没有跨行2)的解决,
----‘vivo’, ‘2021-06-05’, ‘2021-06-15’
----‘vivo’, ‘2021-06-09’, ‘2021-06-21’
先进行判断是否产生了交叉,如果有将上一行的结束时间+1赋值到当前行的起始时间.
– (1,‘redmi’, ‘2021-06-05’, ‘2021-06-21’),
– (2,‘redmi’, ‘2021-06-09’, ‘2021-06-15’),
– (3,‘redmi’, ‘2021-06-17’, ‘2021-06-26’)
这里不适用上述的方法,因为这个产生了跨行交叉,且存在包含,
解释: 包含: 第二行的时间整体就在第一行之内,所以这里只需计算一次,
但是,当使用上述vivo的解决方案的时候变成了上一行的结束时间+1 赋值 -> 第三行的起始时间,这里就出现了差异,
解决方法: 求出最大的那个结束时间进行赋值操作.
代码演示
--第一步:按照开始时间,进行排序
select brand,
start_date,
--获得到上一行为止的最大结束时间
max(end_date) over (partition by brand order by start_date rows between unbounded preceding and 1 preceding ) max_date,
end_date
from promotion_info;
--第二步: 比较,上一行最大的结束日期和这一行的开始时间进行对比,进而求出每一个优惠时间(不含重合时间)的开始,结束时间
select t1.brand,
--if只有一行数据,max_date就没有上一行最大数据,就会以当前的开始时间填充,if结束的时间>=开始的时间,最大的结束时间+1当作当前行的开始时间(这个情况就是出现了交叉),否则还以原开始时间
`if`(t1.max_date is null,t1.start_date,`if`(t1.max_date>=t1.start_date,date_add(t1.max_date,1),t1.start_date)) start_date,
t1.end_date
from (
select brand,
start_date,
--获得到上一行为止的最大结束时间
max( end_date )
over (partition by brand order by start_date rows between unbounded preceding and 1 preceding ) max_date,
end_date
from promotion_info
) t1;
--第三步: end_date-start-date
select t2.brand,
sum(datediff(t2.end_date,t2.start_date)+1) sum_day
from (
select t1.brand,
`if`( t1.max_date is null , t1.start_date ,
`if`( t1.max_date >= t1.start_date , date_add( t1.max_date , 1 ) , t1.start_date ) ) start_date,
t1.end_date
from (
select brand,
start_date,
--获得到上一行为止的最大结束时间
max( end_date )
over (partition by brand order by start_date rows between unbounded preceding and 1 preceding ) max_date,
end_date
from promotion_info
) t1
--datediff(t2.end_date,t2.start_date)>=0去除掉包含的情况
)t2 where datediff(t2.end_date,t2.start_date)>=0 group by t2.brand;
结果展示:
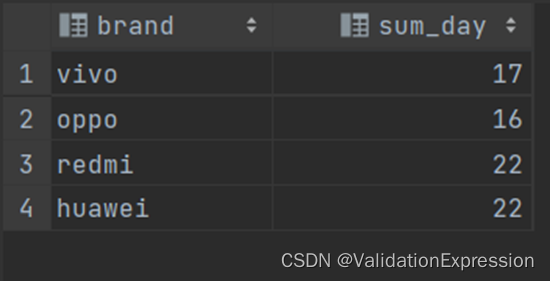
总结
- 这里又介绍了几种解决问题的方法.
- 要知道怎么转化问题.
- 不断进行不同的尝试,有的情况可能考虑的不全,要结合数据在具体考虑.















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









