







系列文章目录
第一章 HQL表创建
第二章 HQL初级练习1
第三章 HQL初级练习2
前言
HQL的中级练习,对于sql函数的使用更加全面.
二、习题练习
1. 查询累积销量排名第二的商品
- 需求: 找到所有销售的商品中,排名第二的商品.
- 分析表: 需要有商品,有销量 (order_detail)
- 分析题意: 对商品进行分组,然后对商品的销量进行求和, 然后对这个表按照销量进行排序操作.
- 表结构说明:
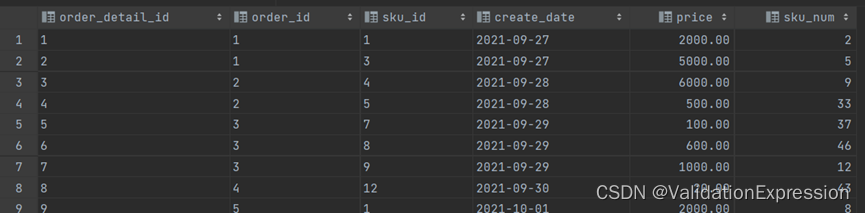
订单明细表(order_detail)
订单明细id ----------------------订单id-------------商品id --------下单时间-------------价格------------下单数量
- 函数介绍:
- 跳跃排序函数:rank : 排名相同时会重复,总数不会减少(1,2,2,2,5……)。
- 不跳跃排序函数:dense_rank: 排名相同时会重复,总数会减少(1,2,2,2,3……)。
- 顺序唯一的排序函数:row_number :行号(1,2,3,4,5,6,7……)。
代码演示
--第一步: 对商品进行分组,求出商品的下单总和
select sku_id,
sum(sku_num) sku_sum
from order_detail
group by sku_id;
--第二步: 对上述的数据加上一个不跳跃的排序(可能会出现多个排名相同的商品)
select t1.sku_id,
t1.sku_sum,
dense_rank() over (order by t1.num desc ) dr --dr:排名
from (
select sku_id,
sum( sku_num ) sku_sum
from order_detail
group by sku_id
)t1;
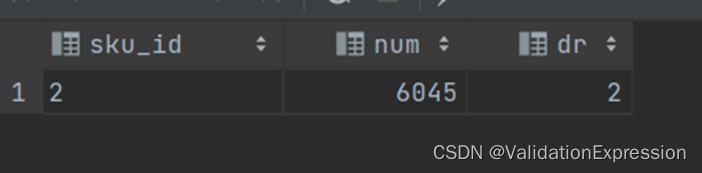
--第三步: 进行过滤,过滤出dr=2的就是排名第二的商品
select *
from (
select t1.sku_id,
t1.sku_sum,
dense_rank( ) over (order by t1.num desc ) dr
from (
select sku_id,
sum( sku_num ) sku_sum
from order_detail
group by sku_id
) t1
)t2 where t2.dr=2;
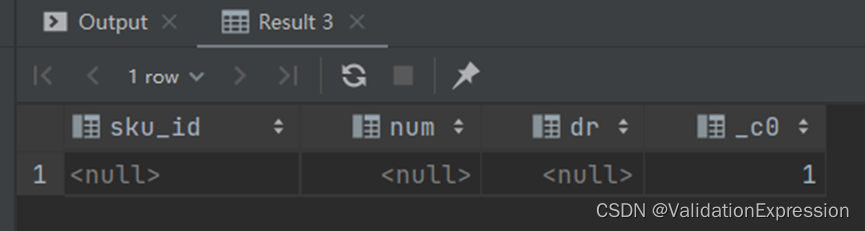
---拓展: 如果想要在没有查到这个排名的时候返回null, 可以join (select 1)
select *
from (
select *
from (
select t1.sku_id,
t1.num,
dense_rank( ) over (order by t1.num desc ) dr
from (
select sku_id,
sum( sku_num ) num
from order_detail
group by sku_id
) t1
) t2 where t2.dr=22
)t3 right join (select 1)t4 on 1=1 ; ---右连接,左边有值的时候,可以显示出,没有值的时候返回null,(确定需要那一方输出null)
结果展示
拓展当没有这个排名的时候返回的是null
2. 查询至少连续三天下单的用户
- 分析表: 用户, 下单 订单详情表(order_info)
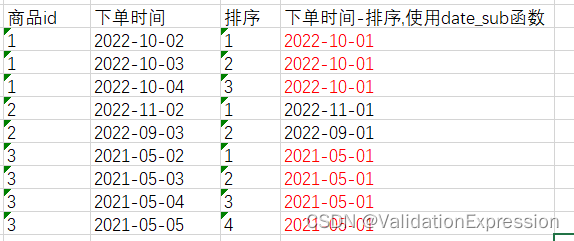
- 分析题意: 连续三天下单,可以使用等差数列(解释如下)的方式处理,
等差数列:只需要判断红色时间数量,就可以判断是否是连续的三天.
- 表结构
订单信息表(order_info)
订单id---------------------------用户id--------------------下单时间-----------------------下单总金额
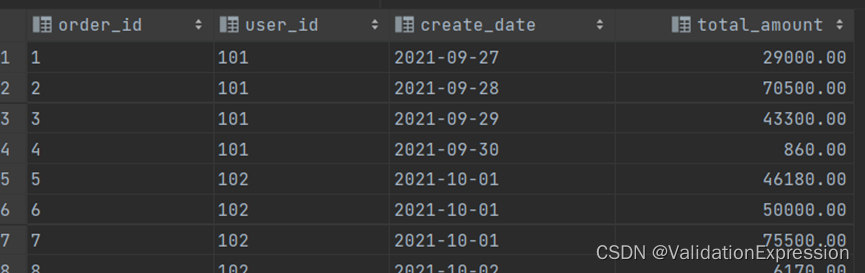
- 使用函数介绍:
- date_sub(A,B): 日期减少函数(A-B)
代码演示
--第一步:
select distinct user_id,create_date from order_info
group by user_id,create_date;
--第二步:排序并得出等差数列
select t1.user_id,
t1.create_date,
--进行排名使用rank
rank() over (partition by t1.user_id order by t1.create_date) rk,
---时间减去后面排序的数
date_sub(t1.create_date,rank() over (partition by t1.user_id order by t1.create_date)) drk
from (
select user_id,create_date from order_info
group by user_id,create_date
)t1;
--第三步:当进行完上述的方法后,这里就可以计算drk相同的数量,在同一id下, 但由于要保留时间,所以使用窗口函数进行计算
select t2.userid,
t2.createdate,
count( * ) over (partition by t2.userid,t2.drk) count_drk
from (
select t1.user_id userid,
t1.create_date createdate,
--进行排名使用rank
--rank( ) over (partition by t1.user_id order by t1.create_date) rk,
---时间减去后面排序的数
date_sub( t1.create_date , rank( ) over (partition by t1.user_id order by t1.create_date) ) drk
from (
select user_id, create_date
from order_info
group by user_id, create_date
) t1
) t2;
---第四步:再次过滤上述的count_drk>=3
select t3.userid,t3.createdate
from (
select t2.userid,
t2.createdate,
count( * ) over (partition by t2.userid,t2.drk) count_drk
from (
select t1.user_id userid,
t1.create_date createdate,
--进行排名使用rank
--rank( ) over (partition by t1.user_id order by t1.create_date) rk,
---时间减去后面排序的数
date_sub( t1.create_date , rank( ) over (partition by t1.user_id order by t1.create_date) ) drk
from (
select user_id, create_date
from order_info
group by user_id, create_date
) t1
) t2
)t3 where t3.count_drk>=3;
---方式二:
select distinct user_id
from (
select user_id
from (
select user_id,
create_date,
date_sub(create_date, row_number() over (partition by user_id order by create_date)) flag
from (
select user_id
, create_date
from order_info
group by user_id, create_date
) t1 -- 同一天可能多个用户下单,进行去重
) t2 -- 判断一串日期是否连续:若连续,用这个日期减去它的排名,会得到一个相同的结果
group by user_id, flag
having count(flag) >= 3 -- 连续下单大于等于三天
) t3;
这个运行可能会出现一个错误(测试使用的是hive + spark)

解决方法: 在DataGrip上执行: set hive.vectorized.execution.enabled = false;
结果展示:(这两种方法user_id是相同的)
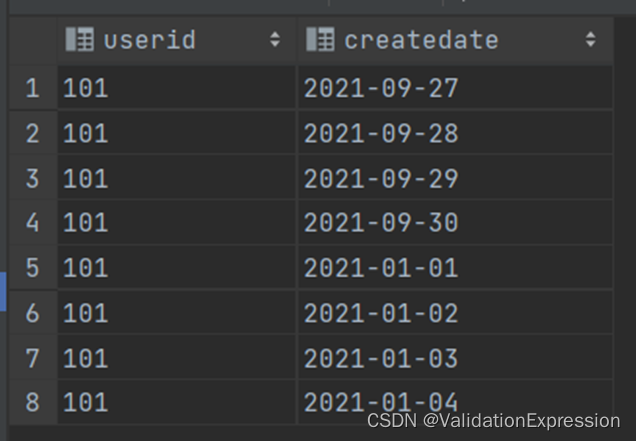
3. 查询各品类销售商品的种类数及销量最高的商品
- 需求: 要找到每一个品类中商品销量最高的商品.
- 分析表: 品类(sku_info), 商品种类, 商品销量 (order_detail),品类名称(Category_info)
- 分析题意:
(1)可以先计算出每个商品的销售总和,然后和品类表关联,在根据品类进行分组,找到销量最高的商品.
(2)也可以直接先将两个表进行关联,然后再分组计算. - 表结构
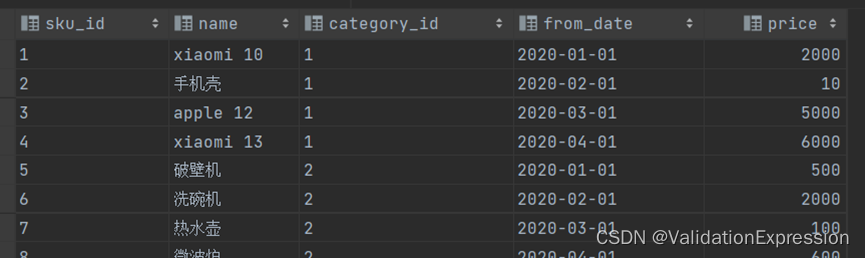
商品信息表(sku_info)
商品id------------------ 商品名称---------- 商品所属种类id------------ 上架时间------------------ 上架时的价格
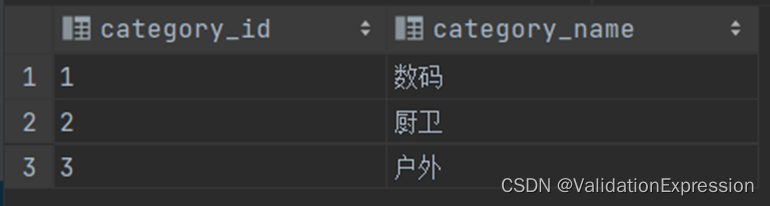
商品分类信息(category_info)
商品分类id-------------------------------------------------------商品分类名称
代码演示
--第一步:先按照商品的id进行分组,找出每件商品的销售数量.t1
select sku_id,sum(sku_num) sku_num_all from order_detail
group by sku_id;
--第二步:将上述表和商品表进行关联,商品表关联: t1 right join sku_info ,并进行商品分类分组,求出最大商品销量 ->t2
select sku.sku_id,
sku.name,
sku.category_id,
nvl(t1.sku_num_all,0) num_sku,
max( nvl( t1.sku_num_all , 0 ) ) over (partition by category_id) max_num
from sku_info sku
left join (
select sku_id, sum( sku_num ) sku_num_all
from order_detail
group by sku_id
)t1 on t1.sku_id=sku.sku_id;
--然后做一个子查询,找到每个品类最大的销售量
select t2.sku_id,
t2.name,
t2.category_id,
t2.num_sku
from (
select sku.sku_id,
sku.name,
sku.category_id,
nvl( t1.sku_num_all , 0 ) num_sku,
max( nvl( t1.sku_num_all , 0 ) ) over (partition by category_id) max_num ---最大的销量数量
from sku_info sku
left join (
select sku_id, sum( sku_num ) sku_num_all
from order_detail
group by sku_id
) t1 on t1.sku_id = sku.sku_id
)t2 where t2.num_sku=t2.max_num; ---这里按照销售的数量查询=最大的销售数量
---第三步: 上述表和商品分类表关联: t2 right join category_info(得到品类名称)
select ci.category_id,
ci.category_name,
t3.sku_id,
t3.name,
t3.num_sku
from category_info ci
left join (
select t2.sku_id,
t2.name,
t2.category_id,
t2.num_sku
from (
select sku.sku_id,
sku.name,
sku.category_id,
nvl( t1.sku_num_all , 0 ) num_sku,
max( nvl( t1.sku_num_all , 0 ) ) over (partition by category_id) max_num
from sku_info sku
left join (
select sku_id, sum( sku_num ) sku_num_all
from order_detail
group by sku_id
) t1 on t1.sku_id = sku.sku_id
) t2
where t2.num_sku = t2.max_num
) t3 on t3.category_id = ci.category_id;
-----方式二: 这里再求出每个商品数量后,再关联商品表和分类表,使用窗口函数排序得到最大销量.
select category_id,
category_name,
sku_id,
name,
order_num,
sku_cnt
from (
select od.sku_id,
sku.name,
sku.category_id,
cate.category_name,
order_num,
rank() over (partition by sku.category_id order by order_num desc) rk,
count(*) over (partition by sku.category_id) sku_cnt
from (
select sku_id,
sum(sku_num) order_num
from order_detail
group by sku_id
) od
join
sku_info sku
on od.sku_id = sku.sku_id
join
category_info cate
on sku.category_id = cate.category_id
) t1
where rk = 1;
结果如下: (方式二的方法:多了一个每个品类有多少商品的字段)

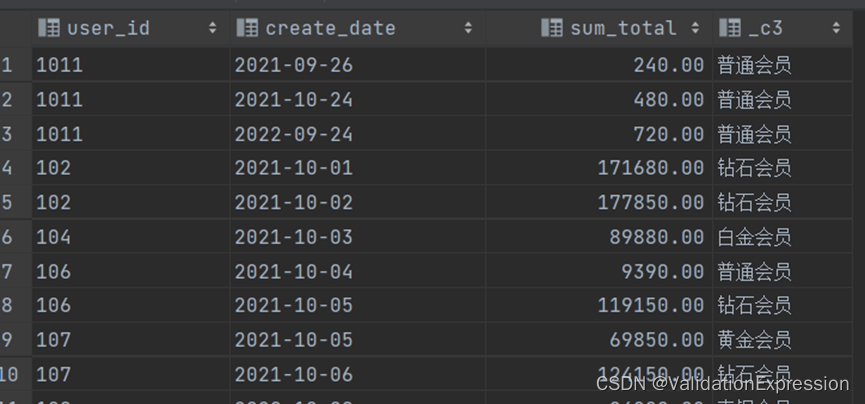
4. 查询用户的累计消费金额及VIP等级
- 需求: 统计每个用户截止其每个下单日期的累积消费金额,以及每个用户在其每个下单日期的VIP等级。
若0=<X<10000,则vip等级为普通会员
若10000<=X<30000,则vip等级为青铜会员
若30000<=X<50000,则vip等级为白银会员
若50000<=X<80000,则vip为黄金会员
若80000<=X<100000,则vip等级为白金会员
若X>=100000,则vip等级为钻石会员 - 表分析: 用户,下单, 下单金额(order_info)~表结构如题2
- 题意分析: 每个用户,每个下单日期(需要进行分组), 有可能再同一天下单了多次,这里就需要对消费的金额进行求和. 然后使用窗口函数sum()over(),可以求出每个下单日期前的下单金额,再然后做一个标记如上条件.
- 使用函数介绍:
- sum() over (partition by A order by B rows between unbounded preceding and current row)
–求第一行到当前行的总共销售金额–unbounded preceding:第一行, current:当前行- case when 条件判断1 then 结果1 when 条件判断2 then 结果2 end
代码演示
---第一步:有可能一天下单了多次,所以先分组,求出同一天的销售额
select user_id,
create_date,
sum(total_amount)
from order_info
group by user_id, create_date;
--第二步: 使用窗口函数统计每一次下单前的销售额总数
select t1.user_id,
t1.create_date,
t1.sum_amount,
sum( t1.sum_amount )
over (partition by t1.user_id order by t1.create_date rows between unbounded preceding and current row ) sum_total
from (
select user_id,
create_date,
sum( total_amount ) sum_amount
from order_info
group by user_id, create_date
) t1;
--第三步:
select t2.user_id,
t2.create_date,
t2.sum_total,
case when t2.sum_total < 10000 then "普通会员"
when t2.sum_total < 30000 then "青铜会员"
when t2.sum_total < 50000 then "白银会员"
when t2.sum_total < 80000 then "黄金会员"
when t2.sum_total < 100000 then "白金会员"
when t2.sum_total >= 100000 then "钻石会员" end
from (
select t1.user_id,
t1.create_date,
t1.sum_amount,
sum( t1.sum_amount )
over (partition by t1.user_id order by t1.create_date rows between unbounded preceding and current row ) sum_total
from (
select user_id,
create_date,
sum( total_amount ) sum_amount
from order_info
group by user_id, create_date
) t1
) t2;
结果展示
5. 查询首次下单后第二天连续下单的用户比率
- 需求:查询首次下单后第二天仍然下单的用户占所有下单用户的比例.
- 分析表: 用户,下单 ,第二天连续下单 (order_info)
- 分析题意: 先对用户和下单时间进行分组,用于去除(同一天下单多次的数据),然后对这个数据进行按照用户分区,时间排序进行排名,然后找到排名1,2的,进而使用窗口函数(也可以使用max,min)来对两个时间进行做差判断是否是连续的两天,在统计总人数和连续两天下单的人数,进而求出%比.
- 函数介绍:
- rank()over(): 排序.
- lead() over(): 找到当前行下面的数据.(根据自己指定的进行查找).
- round(double a, int d):四舍五入,返回保留d位小数的近似值,四舍五入只考虑d+1小数位.
- concat( ,% ): 用于拼接%号.
代码演示
--第一步:先对用户数据进行去重操作,对同一天下单的数据.
select user_id,create_date from order_info
group by user_id,create_date;
--第二步:使用rank()over(partation by ... )排序
select t1.user_id,
t1.create_date,
rank() over (partition by t1.user_id order by t1.create_date) ran
from (
select user_id, create_date
from order_info
group by user_id, create_date
)t1;
--第三步:这里需求是首次下单,第二天也下单,所以根据上述排名只要1,2,(这里使用lead函数用于找到下一个时间)
select t2.user_id,
t2.create_date,
t2.ran,
lead(t2.create_date,1,t2.create_date) over (partition by t2.user_id order by t2.create_date) lea
from (
select t1.user_id,
t1.create_date,
rank( ) over (partition by t1.user_id order by t1.create_date) ran
from (
select user_id, create_date
from order_info
group by user_id, create_date
) t1
) t2 where t2.ran in (1,2) ; ---过滤第一次下单和第二次下单的时间
--第四步: 根据上述lea字段(为首次下单的第二次下单时间),两者相减=1,则表示首次下单后第二天也下单了
--这里可以使用文档上的过滤1,2后使用最大值,最小值,代替使用lead函数
select t3.user_id,
t3.create_date,
t3.lea,
t3.ran,
datediff(t3.lea,t3.create_date) df
from (
select t2.user_id,
t2.create_date,
t2.ran,
lead( t2.create_date , 1 , t2.create_date ) over (partition by t2.user_id order by t2.create_date) lea
from (
select t1.user_id,
t1.create_date,
rank( ) over (partition by t1.user_id order by t1.create_date) ran
from (
select user_id, create_date
from order_info
group by user_id, create_date
) t1
) t2 ---where t3.ran in (1,2) 有两种方式,可以先过滤
)t3 where t3.ran=1;
--第五步: 统计总人数和df=1的个数,求其比值=第一天下单第二天也下单的用户占总用户的比例. round( , 1)保留一位小数
select count(`if`(df=1,1,null)) count_1, --第二天也下单的用户人数
count(distinct t4.user_id) count_num, ---总下单人数
round(count(`if`(df=1,1,null))/count(distinct t4.user_id)*100,1) --百分比
---可以使用concat( ,% )用于拼接%号
from (
select t3.user_id,
datediff( t3.lea , t3.create_date ) df
from (
select t2.user_id,
t2.create_date,
lead( t2.create_date , 1 , t2.create_date )
over (partition by t2.user_id order by t2.create_date) lea
from (
select t1.user_id,
t1.create_date,
rank( ) over (partition by t1.user_id order by t1.create_date) ran
from (
select user_id, create_date
from order_info
group by user_id, create_date
) t1
) t2
where t2.ran in (1,2)
) t3
)t4;
---方法二: 使用最大值最小值的方式判断.
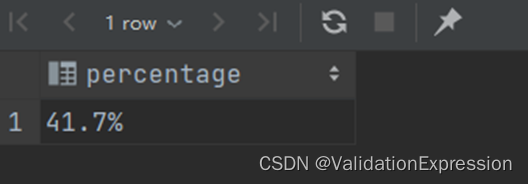
select concat(round(sum(if(datediff(buy_date_second, buy_date_first) = 1, 1, 0)) / count(*) * 100, 1), '%') percentage
from (
select user_id,
min(create_date) buy_date_first,
max(create_date) buy_date_second
from (
select user_id,
create_date,
rank() over (partition by user_id order by create_date) rk
from (
select user_id,
create_date
from order_info
group by user_id, create_date
) t1
) t2
where rk <= 2
group by user_id
) t3;
结果展示

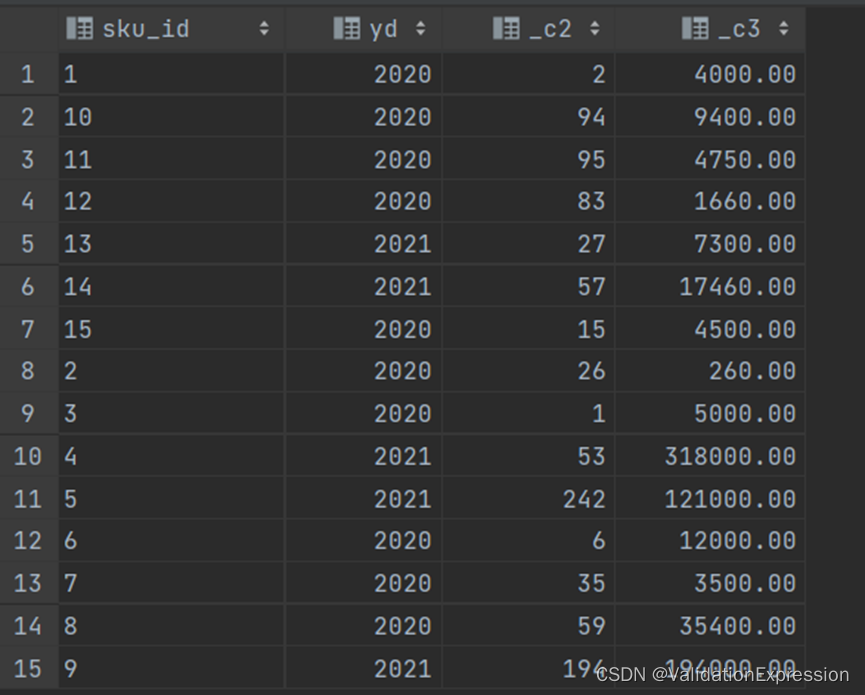
6. 每个商品销售首年的年份、销售数量和销售金额
- 需求: 这个销售数量要找满足首年全年的销售数量,
- 分析表: 商品,时间,销售数量=(相同年份相同商品的总销售量), 销售金额=(销售数量*商品单价)
所以这里考虑(order_detail) - 题意分析: 要找到每个商品最开始销售的那个时间就是首年,然后看商品有多少是在这一年的,格式化销售时间year(),然后可以使用mix()或进行按照商品分区年排序进行排名=1,然后将这个数据按照商品和year进行分组,计算相应的需求.
代码演示
--第一步:使用rank()进行份排序,---这里要的是首年一整年的那个商品,不能使用row_number ,同一年可能在同的时间卖出.
select sku_id,
year( create_date ) yd,
rank() over (partition by sku_id order by year(create_date)) year_row,
price,
sku_num
from order_detail;
--第二步:过滤出年份排名=1的
select t1.sku_id,
t1.yd,
t1.sku_num,
t1.price
from (
select sku_id,
year( create_date ) yd,
rank( ) over (partition by sku_id order by year( create_date )) year_row,
price,
sku_num
from order_detail
)t1 where t1.year_row=1;
--第三步:对id,年份进行分组, 同一年可能在同的时间卖出.
select t2.sku_id,
t2.yd,
sum(t2.sku_num),
sum(t2.price*t2.sku_num)
from (
select t1.sku_id,
t1.yd,
t1.sku_num,
t1.price
from (
select sku_id,
year( create_date ) yd,
rank( ) over (partition by sku_id order by year( create_date )) year_row,
price,
sku_num
from order_detail
) t1
where t1.year_row = 1
)t2
group by t2.sku_id,t2.yd
order by t2.sku_id;
结果展示
总结
- 对于一个需求要考虑全面.
- 窗口函数的使用.
- 例如题2,使用了一个等差数列的方式,可以更加容易的判断是否是连续的时间.
- 例如题4,打标签,拓展需求计算每个等级的用户数量等.
- 这里就是为了练习HQL,有什么错误欢迎指正.















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









