







系列文章目录
前言
这里HQL的初级练习,用于复习sql常用的函数等使用方法.
一、习题练习
8.根据商品销售情况进行商品分类
- 需求:销售件数0-5000为冷门商品,5001-19999为一般商品,20000以上为热门商品,统计不同类别商品的数量
- 分析表:需要知道商品和销售量,考虑订单详情表(order_detail).
- 分析题意:根据商品进行分组,用于求出某件商品的总销售数量,然后按照不同的数量进行分类.
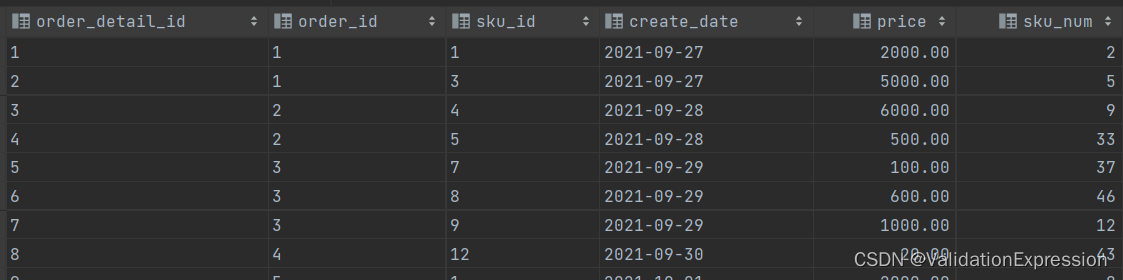
表结构
订单明细id-------------------订单id--------------商品id---------下单时间-------------下单时的价格----下单商品件数
- 使用的函数
- 条件判断函数
case A when B1 then C1 [ when B2 then C2] else D end
如果A=B1则返回C1,如果A=B2则返回C2,否则返回D.
case when A then A1 when B then B1 else C end
如果A判断后为Ture则返回A1,如果B判断后为Ture则返回B1,否则返回C.
代码演示
select t1.sku_type,count(*) count_num
from (
select case when sum( sku_num ) > = 0 and sum( sku_num ) <= 5000 then '冷门商品'
when sum( sku_num ) > 5000 and sum( sku_num ) <= 19999 then '一般商品'
when sum( sku_num ) > 20000 then '热门商品' end sku_type
from order_detail
group by sku_id
)t1
group by t1.sku_type;
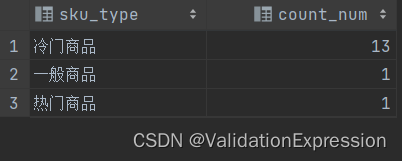
结果
9.查询有新增用户的日期的新增用户数和新增用户一日留存率
- 需求: 留存率=第一天登录后第二天也登录的数量/这第一天新增的用户数量
- 分析表: 需要知道用户是否为新增,只需要看这个用户是否有登录(user_login_detail)
- 分析题意:方式一可以按照时间来求,方式二分别求出某天的新增量和这一天的留存量,然后关联求出最终结果.
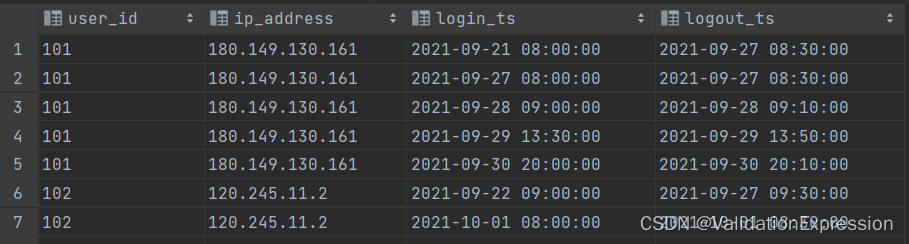
表结构(user_login_detail):
用户id---------------------用户登录ip地址------------登录时间-----------------------登出时间
- 涉及函数
- to_date(): 格式化时间,例子to_date(‘2011-12-08 10:03:01’)=2011-12-08
date_format( , ):格式化时间date_format(“2016-06-22”,“yy-MM-dd”)=2016-06-22- lag(A, B ,C)over(partition by … order by …): 偏移量用于查找当前行的向上偏移.(里面参数根据需求个人书写), A需要偏移的字段,B偏移量,C当前值没有偏移值,书写的替代值.
lead(A, B ,C)over(partition by … order by …): 偏移量用于查找当前行的向下偏移,(其他同上)- datediff(A,B): 计算两个日期的差值.
- rank() over (partition by … order by… ): 排序函数:排名相同时会重复,总数不会减少(1,2,2,2,5……)。
dense_rank() over(……): 排名相同时会重复,总数会减少(1,2,2,2,3……)
row_number() over(……) :行号(1,2,3,4,5,6,7……)
代码演示
--第一步:求每一个用户最开始登录的时间(注册时间),这里也可以使用排名=1的方式(如步骤2)得出.
select user_id, to_date(min(login_ts)) from user_login_detail group by user_id;
--第二步:得出当前时间下一个时间,这里可以根据时间差得出是否是第一天登录了第二天也登录的用户.
select t1.user_id,
t1.td,
lead( t1.td , 1 , t1.td ) over (partition by t1.user_id order by t1.td) second_login,
rank( ) over (partition by t1.user_id order by t1.td) rank_login
from (
select distinct user_id, to_date( login_ts ) td
from user_login_detail
) t1;
--第三步:过滤出排名=1.
select t2.user_id,
t2.td,
t2.second_login
from (
select t1.user_id,
t1.td,
lead( t1.td , 1 , t1.td ) over (partition by t1.user_id order by t1.td) second_login,
rank( ) over (partition by t1.user_id order by t1.td) rank_login
from (
select distinct user_id, to_date( login_ts ) td
from user_login_detail
) t1
)t2 where t2.rank_login=1;
--第四步:对时间进行分组,分别计算出每天新增数量,第二天留存数量
select t3.td,
count(*),
count(`if`(datediff(t3.second_login,t3.td)=1,1,null))/count(*)
from (
select t2.user_id,
t2.td,
t2.second_login
from (
select t1.user_id,
t1.td,
lead( t1.td , 1 , t1.td ) over (partition by t1.user_id order by t1.td) second_login,
rank( ) over (partition by t1.user_id order by t1.td) rank_login
from (
select distinct user_id, to_date( login_ts ) td
from user_login_detail
) t1
)t2 where t2.rank_login=1
) t3
group by t3.td;
------这里展示方式二,分别计算两者数量然后进行关联
select nvl(tt1.login,tt2.login), --nvl():null值替换
nvl(tt1.count_first_login,0),
nvl(tt2.count_second_login,0),
nvl(tt2.count_second_login,0)/nvl(tt1.count_first_login,0)
from (
select t2.login,
count( * ) count_first_login
from (
select t1.user_id,
t1.login,
rank( ) over (partition by t1.user_id order by t1.login) rank_login
from (
select distinct user_id, to_date( login_ts ) login
from user_login_detail
) t1
) t2
where t2.rank_login = 1
group by t2.login
) tt1
left join ( ---左关联(留存的用户数量<=新增的用户数量)
select t2.login,
count( * ) count_second_login
from (
select t1.user_id,
t1.login,
lead( t1.login , 1 , t1.login ) over (partition by t1.user_id order by t1.login) second_login,
rank( ) over (partition by t1.user_id order by t1.login) rank_login
from (
select distinct user_id, to_date( login_ts ) login
from user_login_detail
) t1
) t2
where t2.rank_login = 1
and datediff( t2.second_login , t2.login ) = 1
group by t2.login
)tt2 on tt1.login=tt2.login;
10.登录次数及交易次数统计
- 分析表: 登录次数(user_login_detail), 交易次数(这里就是已经形成订单的表:配送表(delivery_info))
- 分析题意: 可以分别计算登录次数和交易次数,按照相同用户id和时间进行分组,最后两个表进行关联.
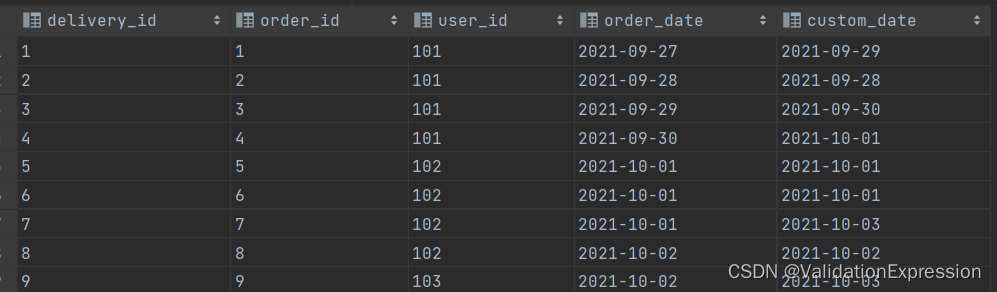
表结构(delivery_info)
配送id,-----------------------订单id---------------用户id----------------下单时间---------------预计配送时间
- 所需函数介绍:
- nvl(A,B): 用于将null值进行替换的函数,当A为null时,使用B值进行替换.
- to_date: 格式化时间
代码演示
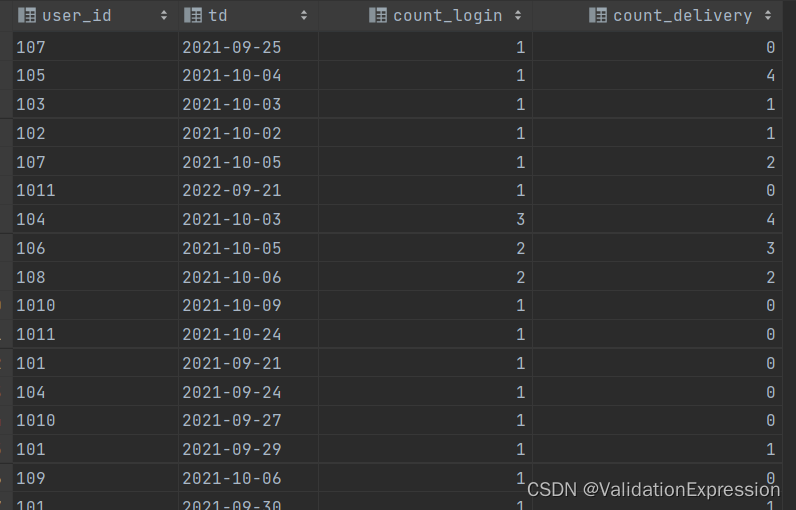
--第一步:统计登录次数(每一天),对用户和登录时间进行分组,统计登录的次数
select user_id,to_date(login_ts),count(*) from user_login_detail
group by user_id,to_date(login_ts);
--第二步: 统计用户交易的次数(有下单),
select user_id,order_date,count(*) from delivery_info
group by user_id,order_date;
--第三步:将两个表进行left join操作,关联条件是用户和时间,要保证一定是登录了,才会有下单
select t1.user_id,
t1.td,
t1.count_login,
nvl(t2.count_delivery,0)
from (
select user_id, to_date( login_ts ) td, count( * ) count_login
from user_login_detail
group by user_id, to_date( login_ts )
) t1
left join (
select user_id, order_date, count( * ) count_delivery
from delivery_info
group by user_id, order_date
) t2
on t1.user_id=t2.user_id and t1.td=t2.order_date;
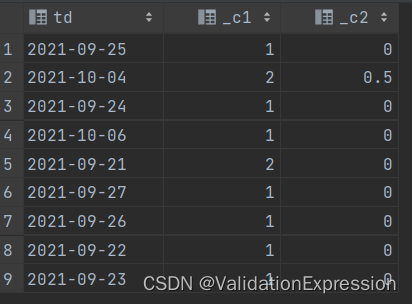
这个数据有点多,这里没有展示完全.(有28行)
11.某周内每件商品每天销售情况
- 需求: 查询2021年9月27号-2021年10月3号这一周所有商品每天销售件数.
- 分析表: 要的是商品的销售总的数量,订单详情表(order_detail),满足有时间有数量,有商品id.
- 分析题意: 对商品id和时间进行分组,从而计算出不同商品在同一天销售的总数量.然后条件判断计算在这一星期每一天销售的数量.
表结构(order_detail):
订单明细id-------------------订单id--------------商品id----------下单时间--------------下单时的价格-----下单数量

- 使用的函数介绍:
- dayofweek(date): 可以用于查看某一天是星期几,
----------------------星期一 ,星期二, 星期三, 星期四, 星期五, 星期六, 星期日
dayofweek(date): 2 ==== 3 ==== 4 ==== 5 ==== 6 ==== 7 ==== 1
这里的数字对应上述的星期.
但是hive自身关于这个函数有个bug存在,这个函数单独使用的时候就如同上述,但是当结合sum(dayofweek())的时候和上述不同,和正常的星期数一样..
经过测试和查询:
- 当再hive中使用dayofweek()的时候,如果要和正常函数用法相同的话,需要将时间进行数据类型转化,如果原时间类型为date则不需要考虑转化,如果为string类型,可以使用cast(‘时间’ as date)进行数据转化.
- 也可以不进行转化,直接按照正常的星期数字进行书写.(如下展示)
代码演示
--出现这个问题是sum()聚合,导致的,如果没有sum()函数可以正常使用.
--第一步:
select sku_id,
`dayofweek`( cast(create_date as date) ) flag, --这里就不用再考虑hive这个bug的问题,按照正常函数处理
sku_num
from order_detail
where create_date between '2021-09-27' and '2021-10-03';
--第二步(1): 子查询
select t1.sku_id,
sum(`if`(t1.flag=2,t1.sku_num,0)) monday,
sum(`if`(t1.flag=3,t1.sku_num,0)) tuesday,
sum(`if`(t1.flag=4,t1.sku_num,0)) wednesday,
sum(`if`(t1.flag=5,t1.sku_num,0)) thursday,
sum(`if`(t1.flag=6,t1.sku_num,0)) friday,
sum(`if`(t1.flag=7,t1.sku_num,0)) saturday,
sum(`if`(t1.flag=1,t1.sku_num,0)) sunday
from (
select sku_id,
create_date,
`dayofweek`(cast( create_date as date)) flag,
sku_num
from order_detail
where create_date >= '2021-09-27' and create_date <= '2021-10-03'
)t1
group by t1.sku_id;
--第二步(2): 不使用cast
select t1.sku_id,
sum(`if`(t1.flag=1,t1.sku_num,0)) monday,
sum(`if`(t1.flag=2,t1.sku_num,0)) tuesday,
sum(`if`(t1.flag=3,t1.sku_num,0)) wednesday,
sum(`if`(t1.flag=4,t1.sku_num,0)) thursday,
sum(`if`(t1.flag=5,t1.sku_num,0)) friday,
sum(`if`(t1.flag=6,t1.sku_num,0)) saturday,
sum(`if`(t1.flag=7,t1.sku_num,0)) sunday
from (
select sku_id,
create_date,
`dayofweek`(create_date) flag,
sku_num
from order_detail
where create_date >= '2021-09-27' and create_date <= '2021-10-03'
)t1
group by t1.sku_id;

12.同期商品售卖分析表
- 需求:统计同一个商品在2021年和2022年中同一个月的销量对比.
- 分析表: 时间,销量,商品(order_detail)
- 个人当时错误的思路: 当时写的时候分别计算了这两年月份和销售总量,然后将这两个表join操作(按照商品的id和月份), 最后发现少考虑一种情况: 要求的是20年21年同月的销售量,就有可能出现20年在某个月卖了A商品没有卖B商品,但是21年相同的月卖了B商品但是没有卖A商品的情况
如果只join,这里只求出了在20年和21年相同月份卖的相同商品(此时的商品只会有20年和21年都有销量的商品,并不是所有商品种类).因此注意这个情况.(但这里也可以使用full join计算出结果)
代码演示
--第一步: 计算21年的商品,在不同月份的销售量
select sku_id,month(create_date),sum(sku_num) from order_detail
where year(create_date)=2020
group by sku_id,month(create_date);
--第二步:计算22年商品,在不同的月份的销售量.
select sku_id,month(create_date),sum(sku_num) from order_detail
where year(create_date)=2021
group by sku_id,month(create_date);
--第三步:将上述的两个表进行full join
select nvl(t1.sku_id,t2.sku_id) sku_id,
nvl(t1.20_month,t2.21_month),
nvl(t1.20_skunum,0),
nvl(t2.21_skunum,0)
from (
select sku_id, month( create_date ) 20_month, sum( sku_num ) 20_skunum
from order_detail
where year( create_date ) = 2020
group by sku_id, month( create_date )
) t1 full join (
select sku_id, month( create_date ) 21_month, sum( sku_num ) 21_skunum
from order_detail
where year( create_date ) = 2021
group by sku_id, month( create_date )
)t2 on t1.sku_id=t2.sku_id and t1.20_month=t2.21_month
order by sku_id;
----------上述的方法,过于繁琐.
--可是使用如下方法,使用sum(),if()函数结合的方式.
select sku_id,
month(create_date),
sum(`if`(year(create_date)=2020,sku_num,0)) 20_skunum,
sum(`if`(year(create_date)=2021,sku_num,0)) 21_skunum
from order_detail
where year(create_date)=2020 or year(create_date)=2021
group by sku_id, month(create_date)
order by sku_id;
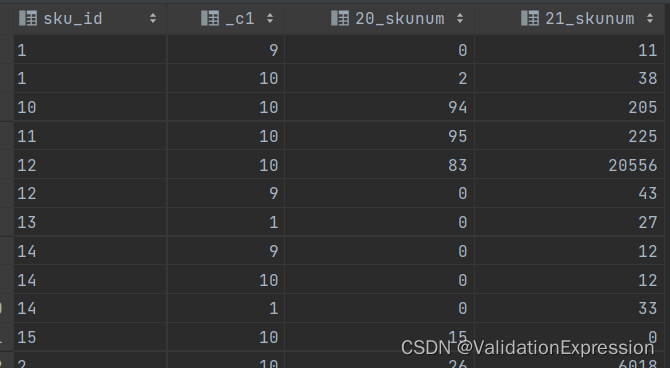
部分结果展示
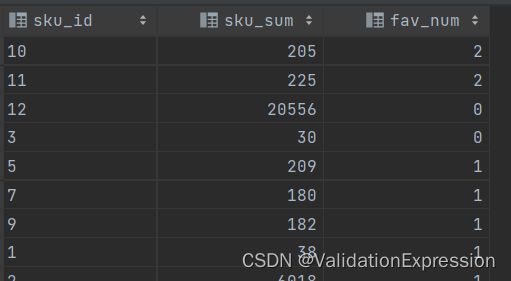
13.国庆期间每个sku的收藏量和购买量
- 需求:求2021年国庆节期间(10月1日-10月7日),每个商品的购买总数量和总收藏次数.
- 分析表: 收藏,商品,时间:(favor_info), 购买=销量,商品,时间(order_detail)
- 分析题意: 分别计算收藏量和购买量,最后根据商品的id进行关联, 注意还有时间范围在国庆期间(10-01~10-07)
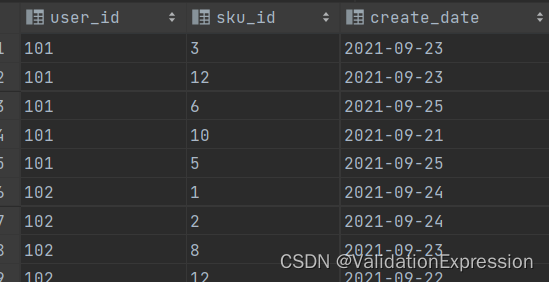
表结构展示(favor_info):
用户id---------------------------------商品id----------------------收藏日期
代码演示
--第一步: 计算销售量
select sku_id, sum( sku_num ) sku_sum
from order_detail
where month( create_date ) = 10
and day( create_date ) between 1 and 7
group by sku_id;
--第二步: 同上计算收藏量
select sku_id,count(sku_id) from favor_info
where month(create_date)=10 and
day(create_date) between 1 and 7
group by sku_id;
--第三步: 上述两个表join
select nvl(t1.sku_id,t2.sku_id),
nvl(t1.sku_sum,0),
nvl(t2.sku_sum,0)
from (
select sku_id, sum( sku_num ) sku_sum
from order_detail
where month( create_date ) = 10
and day( create_date ) between 1 and 7
group by sku_id
) t1 full join (
select sku_id, count( sku_id ) sku_sum
from favor_info
where month( create_date ) = 10
and day( create_date ) between 1 and 7
group by sku_id
)t2 on t1.sku_id=t2.sku_id;
计算结果:
14.21年国庆节期间各品类商品的7日动销率和滞销率
- 需求分析:
–动销率:有销量的商品种类数/已上架总商品种类数
–滞销率:没有销量的商品种类数/已上架总商品种类数
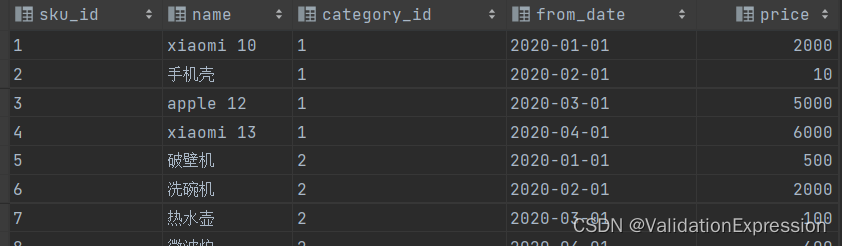
–解释: 同一类商品有的有销量,有的没有, 所以有销量的商品种类/总上架的商品种类= 动销率 ,总上架的可以有sku_info得出, - 分析表: 各品类商品(sku_info), 销量的商品(order_detail)
表结构(sku_info)
商品id-------------------商品名称---------商品品类id--------------------商品上架日期--------------商品上架时的价格
- 函数使用说明:
1.cast(A as B ): 将A数据类型转化为B类型
例如: cast(‘2021-10-10’ as date): 就是将字符类型的时间转化为date类型
2. 还有一种
cast(A as decimal(16,2)): 本质还是数据类型转化,这里A数据会保留2位小数,数总位数(整数位14,小数位2)为:16.
代码演示
--第一步: 先过滤在国庆期间,并进行去重,得到有销量的商品id
select distinct sku_id from order_detail
where create_date between '2021-10-01' and '2021-10-07';
select sku.category_id,
--解释: 先进行时间的确定,if判断语句会记录这里的商品id,最后利用去重+count得到在一个种类中的商品销量的情况, 第二个时间需要先判断上架时间要小于这一天的时间.
cast(count(distinct `if`(t1.create_date='2021-10-01',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-01',sku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-02',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-02',sku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-03',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-03',sku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-04',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-04',sku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-05',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-05',sku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-06',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-06',xiaosku.sku_id,null))as decimal(16,2)),
cast(count(distinct `if`(t1.create_date='2021-10-07',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-07',sku.sku_id,null))as decimal(16,2))
from sku_info sku
left join (
select sku_id,create_date
from order_detail
where create_date between '2021-10-01' and '2021-10-07'
)t1 on sku.sku_id=t1.sku_id
group by sku.category_id; ---对商品的种类进行分组
---这里只写了动销率:
--滞销率= (1-动销率) 可以直接在上述表添加相应的字段.
--(1-(cast(count(distinct `if`(t1.create_date='2021-10-01',t1.sku_id,null))/count(distinct `if`(sku.from_date<='2021-10-01',sku.sku_id,null))as decimal(16,2))))

总结
- 注重分析题意,不要遗漏题目中的条件,还有怎样将需求进行转化为可以计算的方式.
- 还有一些逻辑的转化(新增用户,就是第一次登录的用户).
- 双向表转单项表更容易解决问题(向用户推荐朋友收藏的商品).
- 最后,关于dayofweek()的bug问题,当时思考了许久.















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









