







小伙伴们在学习机器学习的时候这几个概念肯定是绕不开的,在这里就和小伙伴们用大白话分享一下这个东西~
1.错误率
我们在用机器学习做一些事情的时候,它毕竟不能保证百分之百正确嘛,这个是显而易见的,比如说,我有100个西瓜的照片,计算机识别出来了90个,那这个时候的错误率就是10%嘛,所以这个错误率很好理解,数学公式如下:
呀,咋公式这么复杂,别担心,其实很简单,咱们一个一个解释它里面各个字母的含义:
:你可以认为是机器学习的一种判断规则,就是你给它一个西瓜的照片,它怎么判断的,相当于数学上的一个函数呗。
: 哎就是那100个西瓜的照片,一个数据集。
: 100个西瓜照片的100。
: 就相当于一个布尔函数,如果计算机识别出来是西瓜那不就和实际值不一样,那就记为1,一样就记为0,这样把所有的1加起来就是计算机识别错误的总个数啦,这里我们算的是识别错误的哦,小伙伴们可别想错嘞。
:第
张西瓜照片计算机识别的结果。
: 第
张西瓜照片(我们这里只是举例方便,真实应该是识别正确就相等,并非两张照片相等)
怎么样不难吧,下面再说说精度。
2.精度
其实就是正确率,你看公式:
你看,是吧,这个就不用解释了哈,和错误率的公式差不多。
3.查准率和查全率
这俩个得一起说,我们为什么要有查准率和查全率,不用细想,那肯定是上面那俩不够用了呗,还拿西瓜举例,假如说我现在有60个西瓜照片,40个橘子照片,那计算机识别的西瓜照片有70个,橘子识别有30个,那肯定中间有识别错误的,我画个表,看下表

你看,如果说我们想知道我识别出来是西瓜的里面有多少真的是西瓜,那是不是错误率和精度就不够解释了,那从这张表里面来看就是50除以(50+20)呗,这就是查准率。那我们换一个角度,我们想知道,全部的西瓜中有多少被识别出来是西瓜,那这时候是不是就是50除以(50+10),这个就是查全率,其实都是字面意思就可以理解啦~
我们来看严谨的数学公式,先把上述的表给抽象一下:
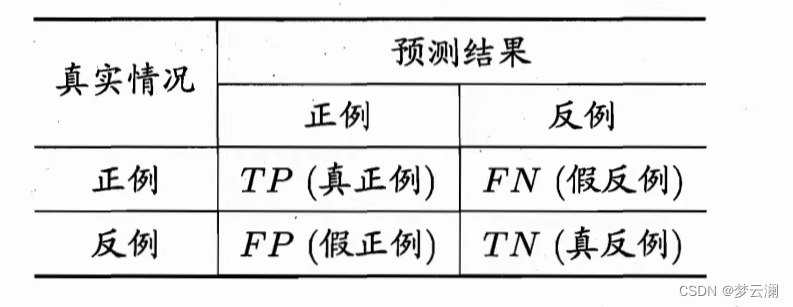
怎么样,经过上述的例子这个表不太难理解叭~
然后我们的查准率 和查全率
的定义如下:
这里的公式也只是把上述例子中的数字给换成字母了哦,不难的~
4.查准率和查全率的关系
我们这里举的例子只有100个数据量,那我们有100万个呢?这时候想看查准率和查全率一定要全部识别完嘛?可不是哦,先说结论:一般来说,查准率高时,查全率往往就低;查全率高,查准率往往就低。这是为啥?如果我们想尽可能的把西瓜的照片尽可能识别出来,那肯定增加识别照片的数量呗,如果100个照片都选上,那所有的西瓜照片肯定也都在其中,但这样的话查准率就下去了,反之,我想选出西瓜照片的比例尽可能的高,那肯定提高计算计算机的识别规则,“提高识别的把握”,那肯定会有一些照片识别错误(这个也好理解,比如说你现在只做有把握的事儿,那其实有些事你也能做成,但你给漏掉了,就是这个意思),那查全率就低了,我们来看一幅图
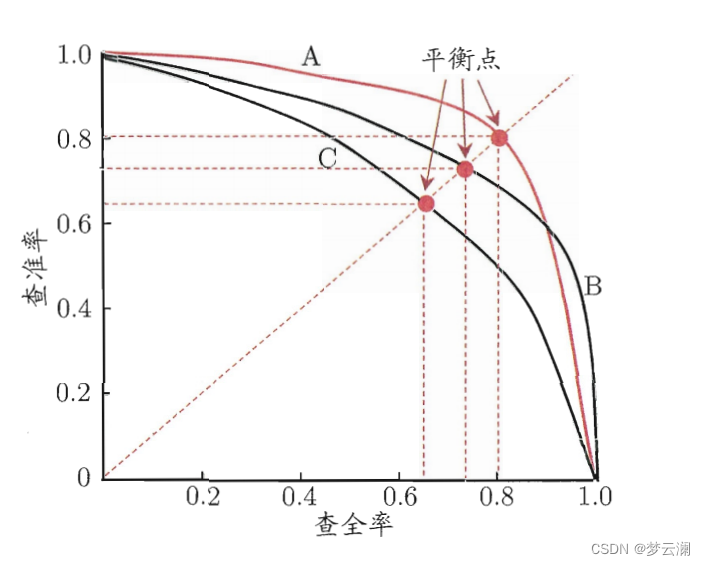
这个就是不同的机器学习“规则”下,查全率和查准率的一个关系,在一定的值下,查全率和查准率会出现相等的情况,这就是所谓的平衡点,至于你想要查全率高一点呢还是查准率高一点呢,这个看你实际情况的需要了,当然,这个取舍问题我们机器学习里面是有一定的方法的,这个我们其他文章再分享~
ok,这篇文章就分享到这里啦,欢迎小伙伴们批评指正~(知识图片都来自西瓜书)
















 2511
2511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











