







 本文介绍了评估机器学习模型性能的关键指标,包括准确率、召回率、精度等,并详细解释了这些指标的具体含义及其计算方法。
本文介绍了评估机器学习模型性能的关键指标,包括准确率、召回率、精度等,并详细解释了这些指标的具体含义及其计算方法。
概念
准确率precision(查准率): 是针对预测为正的样本来说的,指的是,预测为正的样本中预测正确了的百分比。
召回率recall(查全率):是针对真实为正的所有样本来说的,指的是,所有为正的样本中,被正确识别出来了的样本的比例。
精度accuracy:指的是,预测正确了的样本占总样本的比例。
错误率:1-精度
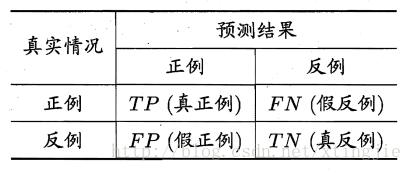
TP:真正例 (预测为正,真实为正)
TN: 真反例 (预测为反,真实为反)
FP:假正例 (预测为正,真实为反)
FN:假反例 (预测为反,真实为正)
准确率 precision=TPTP+FP
召回率 recall=TPTP+FN
可以发现分子都是TP,即真实为正预测也为正的样本
精度= TP+TNTP+TN+FP+FN

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









