








概述
集成学习思想
- 线性回归、逻辑回归、决策树都是单一模型预测
- 我们想把多个相同模型、多个不同种类的模型组合起来,形成一个更强大的模型进行预测
集成学习概念:将多个学习器(也称为基学习器)组合成一个更强大的学习器的机器学习技术。
通过利用多个学习器的优势来提高预测的准确性和鲁棒性,从而达到更好的性能表现。

- 集成学习通过构建多个模型来解决单一预测问题
- 生成多基学习器,各自独立地学习和预测
- 通过平权或者加权的方式,整合多个基学习器的预测输出
基学习器使用的方法:
- 可使用不同的学习模型,比如:支持向量机、神经网络、决策树整合到一起作为一个集成学习系统
- 也可使用相同的学习模型,比如,多个基学习器都使用决策树,倾向于使用相同的学习模型
集成分类策略
- Bagging(集成、打包、袋装)
- 代表算法:随机森林
- Boosting提升树
- 代表算法:Adaboost、GBDT、XGBoost、LightGBM
Bagging思想

- 有放回的抽样(booststrap抽样)产生不同的训练集,从而训练不同的学习器
- 通过平权投票、多数表决的方式决定预测结果,基学习器可以并行训练
 Boosting思想
Boosting思想

- 每一个训练器重点关注前一个训练器不足的地方进行训练
- 通过加权投票的方式,得出预测结果,串行的训练方式
栗子:

随着学习的积累从弱到强 ,每新加入一个弱学习器,整体能力就会得到提升。
随机森林算法
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由多个树输出的类别的众数而定。

训练了5个树, 其中4个树的结果是True, 1个树的结果是False, 最终投票结果True ,弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果
随机森林算法 – API

import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
def fuc():
titan = pd.read_csv(“train.csv”)
x = titan[[“Pclass”, “Age”, “Sex”]].copy()
y = titan[“Survived”]
x[‘Age’].fillna(value=titan[“Age”].mean(), inplace=True)
x = pd.get_dummies(x)
x_train, x_test, y_train, y_test = \
train_test_split(x, y, random_state=22, test_size=0.2)
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
dtc_y_pred = dtc.predict(x_test)
accuracy = dtc.score(x_test, y_test)
rfc = RandomForestClassifier(max_depth=6, random_state=9)
rfc.fit(x_train, y_train)
rfc_y_pred = rfc.predict(x_test)
accuracy = rfc.score(x_test, y_test)Adaboost算法
Adaptive Boosting(自适应提升)基于 Boosting思想实现的一种集成学习算法,常用于二分类。
核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。
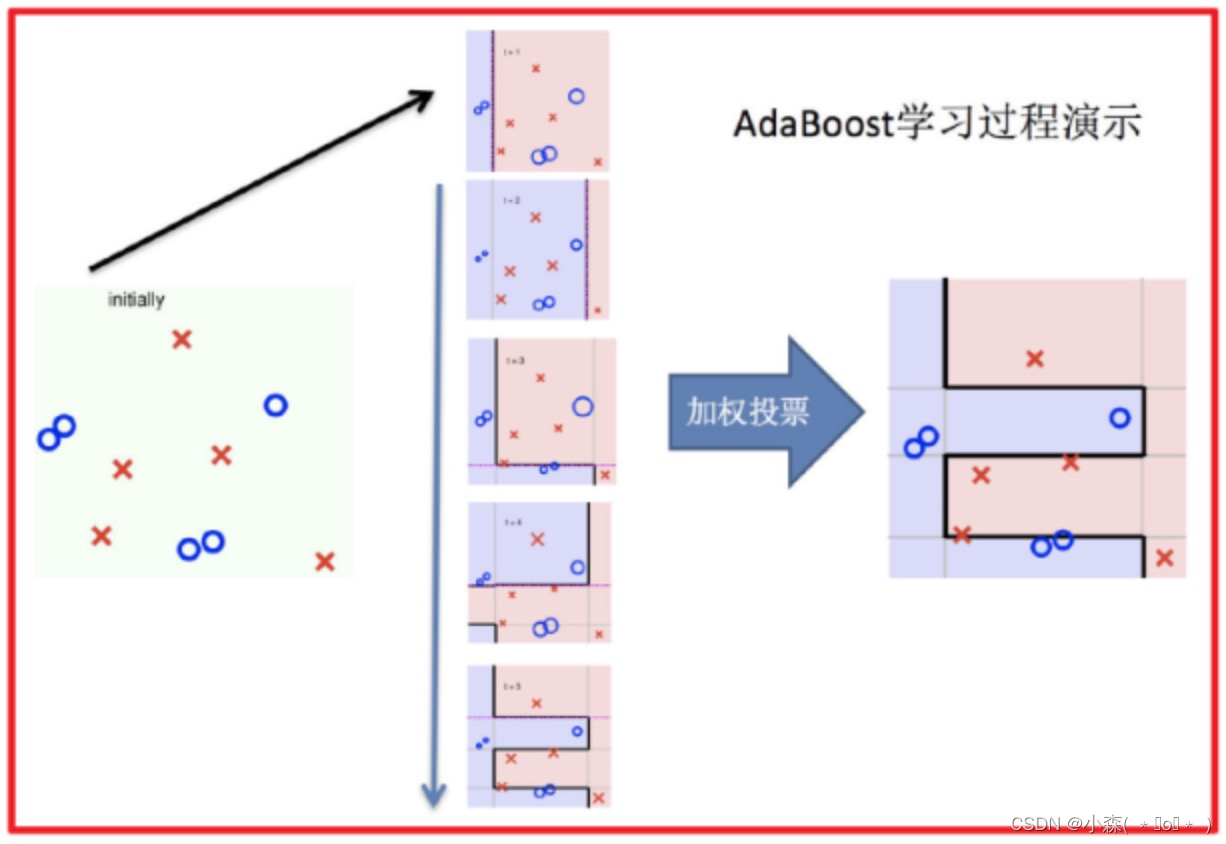
初始化训练数据(样本)权重相等,训练第 1 个学习器,根据预测结果更新样本权重、模型权重 。
迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器。
假设已训练了3个基学习器,第1个/2个/3个基学器模型权重分别为:0.4236,0.64963,0.7514。当输入x=3,计算最后的输出类别:
根据投票公式:H(x) = sign(0.4236 * ℎ 1 (𝑥) + 0.64963 * ℎ 2 (𝑥) + 0.7515 * ℎ 3(𝑥) )
= 0.4236*(-1) + 0.64963*(1) + 0.7514*(-1) = -0.52537 < 0
预测结果小于零,所以x=3的样本(4号样本)归为负类。
- Bagging分类中比如随机森林因采用随机抽样、随机抽特征,即使把模型训练的有一些过拟合,但是因为采用平权投票的方式,可以减少过拟合的发生。
- 随机森林中决策树可以不剪枝,因过拟合模型输出会更多元化,增加了数据的波动程度。通过集成学习平权投票可以有效降低方差。
从偏差-方差的角度看,Boosting主要用于提高训练精度,Bagging中每一个基学习器都对上一个基学习器分类不正确的样本,进行重点关注,相当不断的提高模型的准确度,让模型预测的更准,打的更准。
GBDT
残差提升树
提升树概念: 通过拟合残差的思想来进行提升。
预测某人的年龄为100岁:
- 第1次预测:对100岁预测,因单模型在预测精度上有上限,只能预测成80岁;100 – 80 = 20(残差)
- 第2次预测:上一轮残差20岁作为目标值,只能预测成16岁;20 – 16 = 4 (残差)
- 第3次预测:上一轮的残差4岁作为目标值,只能预测成3.2岁;4 – 3.2 = 0.8(残差)
- 80 + 16 + 3.2 = 99.2
- 通过拟合残差可将多颗弱学习器组成一个强学习器。
GBDT 使用 CART 回归树,GBDT每次迭代要拟合的是梯度值是连续值,所以要用回归树,CART 回归树使用平方误差。
梯度提升树计算过程
- 第1轮:拟合上一轮的负梯度(第1轮就是最原始的y目标值),然后计算负梯度(目标值 – 预测值=负梯度)
- 第2轮:拟合上一轮的负梯度 ,然后计算负梯度,目标值(上一轮的负梯度) - 预测值(利用平方损失最小化,找到最优分裂点而产生的预测值) = 负梯度
- 直到达到指定的学习器个数。
当输入未知样本时,将所有弱学习器的输出结果加起来作为强学习器的输出,最终的结
果 :7.31 + (-1.07) + 0.22 + 0.15 = 6.61 (为三个梯度)
















 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











