






最近复现stable diffusion等大模型的过程中需要保存该模型的pt文件,探索了一些方法,这篇帖子总结一下如何保存大模型的pt文件,针对大部分模型都很适用。
模型的pt文件有什么用
我们先来说下模型的pt文件有什么用:模型的.pt文件是PyTorch中用于保存模型的一种文件格式。这种文件通常包含了模型的结构和参数,使得模型可以被序列化存储到磁盘上,之后可以被重新加载和使用。以下是.pt文件的一些主要用途:
保存和加载模型:.pt文件可以保存整个模型或者模型的参数(state_dict)。这允许研究人员和开发者在训练完成后保存模型,以便将来进行推理或继续训练。
模型共享和复现:通过分享.pt文件,其他研究人员和开发者可以加载模型并复现实验结果,这对于学术交流和模型的进一步研究非常有用。
模型推理:在实际应用中,.pt文件可以被加载到PyTorch中,用于对新的数据进行预测。这是模型部署到生产环境的一个常见步骤。
模型微调:.pt文件中保存的预训练模型可以作为微调的起点,通过在特定任务上继续训练,可以提高模型在特定领域的性能。
模型结构和参数的备份:.pt文件不仅保存了模型的参数,还可以包含模型的结构信息,这对于备份和恢复模型至关重要。
总的来说,.pt文件是PyTorch中一个非常重要的组件,它使得模型的保存、共享、加载和使用变得简单和高效。
保存大模型pt文件的方法一(本地已经下载了大模型的源码,通过读取本地代码保存pt文件)
下面以stable diffusion 2.1为例,本地的源码文件名是sd2-1,像保存在ptsave文件夹,命名为model.pt,下面直接上代码
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"/XXXX/sd2-1", torch_dtype="auto", device_map="auto"
)
# 保存模型
torch.save(model, '/XXXXXXX/ptsave/model.pt')
这里提出两点注意事项:
第一点:如果你本地端无gpu只有cpu,那可能会出现这个问题:
RuntimeError: Failed to import transformers.models.qwen2_vl.modeling_qwen2_vl because of the following error (look up to see its traceback):
Error loading libaom-3c98a6db777c6c7fedeac4ae87f4314b.dll; %1 不是有效的 Win32 应用程序。
这个问题大部分的解决方案是修改或者配置编译文件,处理起来也是有些难度的,我在本地遇到过,但是放到有gpu的服务器上就这个正常了。
第二点:在保存pt文件过程中,需要先读入模型,我推荐直接在hugging face官网使用逛网model card里的quick start这里给出的读模型方法,因为其他的模型读入方法可能都会报错,这一点注意事项对任何大模型都借鉴意义,读入模型的具体体现参考下面的图片,以这个模型为例,代码的前两行就是读入模型。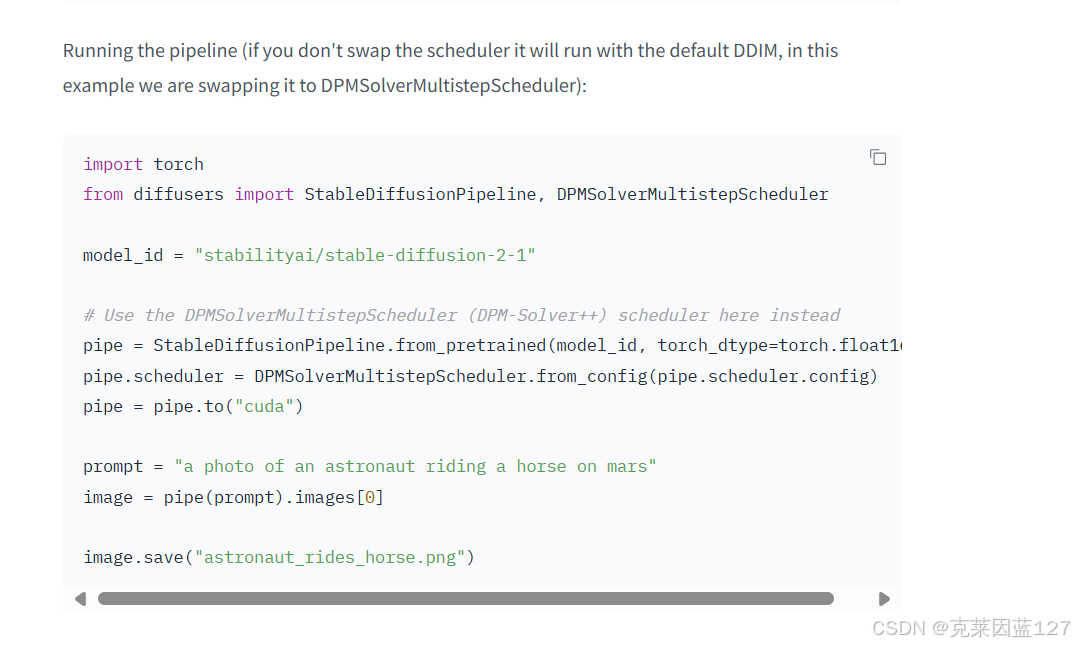
保存大模型pt文件的方法一(从hugging face在线链接读入模型并保存pt文件)
从hugging face上加载(注意关掉本地电脑的VPN),还是以stable diffusion 2.1为例,找到官方文件夹的名字放在model_name_or_path处,我们此时保存在ptsave文件夹,命名为model.pt

import os
os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig
from accelerate import init_empty_weights
import torch
#os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
model_name_or_path = "stabilityai/stable-diffusion-2-1"
with init_empty_weights():
config = AutoConfig.from_pretrained(
model_name_or_path,
device='cuda:0' # 加载
)
model = AutoModelForCausalLM.from_config(config)
torch.save(model, 'XXXX/ptsave/model.pt')
这里提出两点注意事项:
第一点:在线获取的时候需要关闭本地的vpn,不然会报错
第二点:一定要将
import os
os.environ[‘HF_ENDPOINT’] = “https://hf-mirror.com”
这段代码放在from xxx import xxx之前!!!!不然会报这个错误:
OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file, couldn’t find it in the cached files and it looks like Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4 is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at ‘https://huggingface.co/docs/transformers/installation#offline-mode’.
总之,把> import os
os.environ[‘HF_ENDPOINT’] = "https://hf-mirror.com"放代码最前面就好了。
另外,除了以上的过程,在复现或者保存大模型pt文件过程中都可能会遇到一些问题,可尝试通过安装或者更新transformers或者其他库来升级包,以解决一些问题,我把可能需要更新的包放在下面:
本地环境更新:
pip install --upgrade pip
pip install --transformers
pip install --upgrade transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install accelerate
pip install accelerate -i https://mirrors.aliyun.com/pypi/simple/
因为基本所有大模型LLM都用到了transformers库,而transformers库又推出了很多个新版本,所以要看清想要复现的大模型都需要transformers的哪个版本,以此来安装或者更新,下面给出两种查看当前环境transformers库的方法:
pip show transformers
或
import transformers
print(transformers.__version__)
如果安装包过程较慢,可以尝试添加源,加快下载包的过程:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install requests -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
以上过程仅供各位小伙伴参考学习!

















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









