






hugging face官方链接/国内镜像网站
今天给各位小伙伴介绍一个可以开放获取各种大模型(例如llama系列,qwen系列,OpenGVLabIntern系列,stable diffusion系列等大模型)权重以及复现代码的网站–hugging face
其官方链接:https://huggingface.co/,但是官方网站需要vpn,有一个国内镜像网站同样可用:https://hf-mirror.com/models
what is hugging face?
Hugging Face 是一个开源的机器学习平台,专注于自然语言处理(NLP)和人工智能(AI)。它提供了模型、数据集(文本、图像、音频、视频)、类库(比如transformers、datasets、accelerate)和教程等资源。
Hugging Face 起初是一家总部位于纽约的聊天机器人初创服务商,后来因为开源了一个Transformers库而在机器学习社区迅速火起来,目前已经共享了超过100,000个预训练模型和10,000个数据集,变成了机器学习界的github。
Hugging Face 的核心特点包括:
合作平台:提供无限模型、数据集和应用程序的托管和协作服务。
加速机器学习:通过其开源堆栈,帮助用户加速机器学习项目。
多模态探索:支持文本、图像、视频、音频甚至3D内容的机器学习任务。
构建个人作品集:用户可以共享自己的工作,构建自己的机器学习作品集。
企业级服务:提供企业级安全性、访问控制和专业支持的高级平台,帮助企业构建AI。
广泛应用:超过50,000个组织正在使用Hugging Face,其中包括Allen Institute for AI、Meta、Amazon Web Services、Google、Intel、Microsoft等。
开源精神:Hugging Face秉承开源精神,与社区一起构建机器学习工具的基础。
Hugging Face 社区包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。目前包括模型236,291个,数据集44,810个。
Hugging Face 也提供了一些核心组件,如Transformers、Dataset、Tokenizer等,这些组件支持了预训练的语言模型和相关工具,使得研究者和工程师能够轻松的训练和使用海量的NLP模型。
hugging face操作界面
首先进入网站,是这样的画面:
初次使用需要先登录,任何邮箱都可以,因为有的模型源码是需要登陆后才有权限下载的。
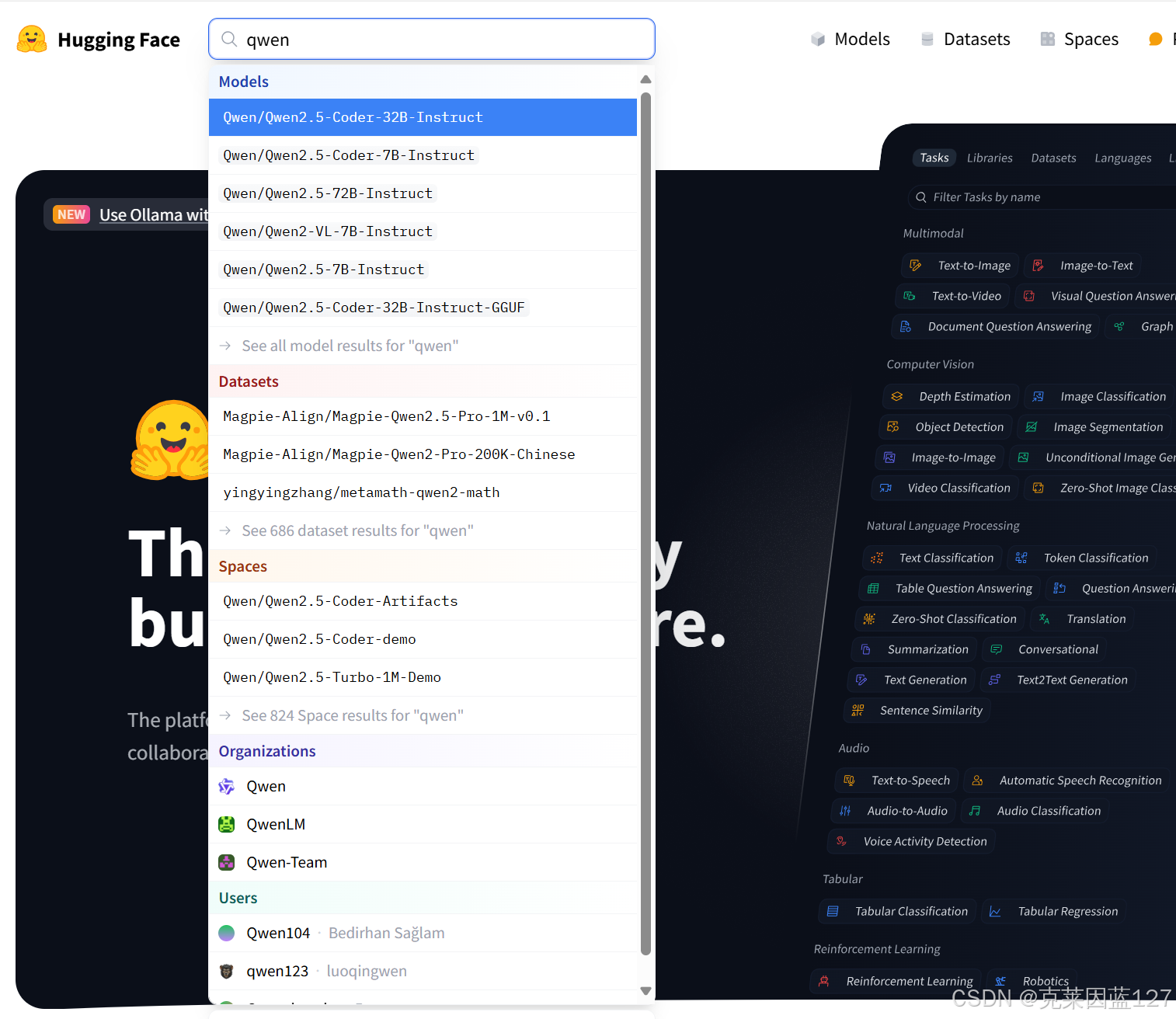
我们在搜索框,就可以按需求搜索大模型,以qwen为例,搜索关键词即可,或者准确输入完整模型名称:
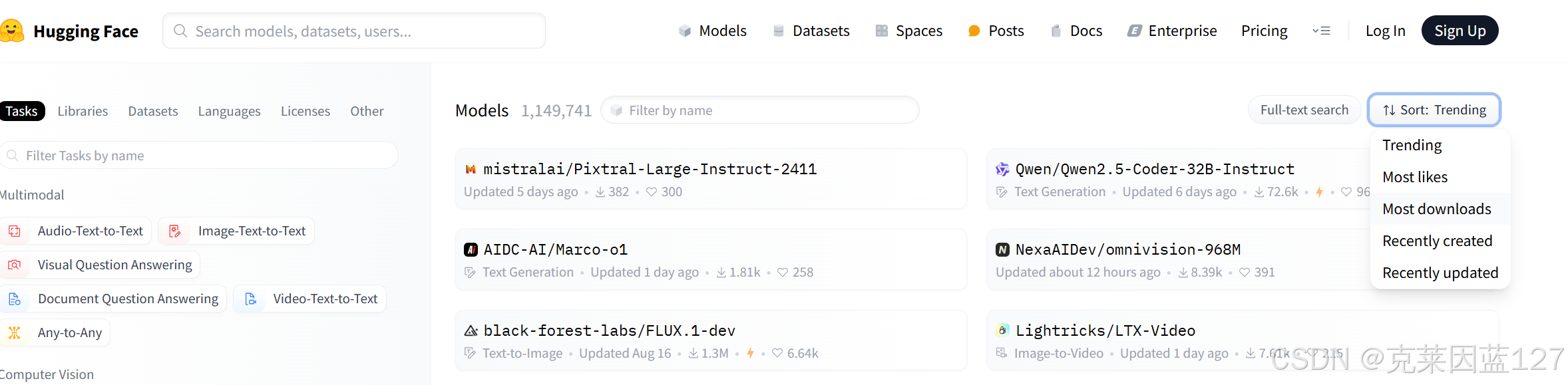
或者点击右上角的Models,然后点击旁边的sort,可根据偏好浏览要下载的模型;比如most like 大众最喜欢的,most downloads 下载最多的等等。
在hugging face下载源码
以下面这个模型为例,点击进去可以看到model card,files and versions, community,这三个分别是快速复现,模型源码,和社区讨论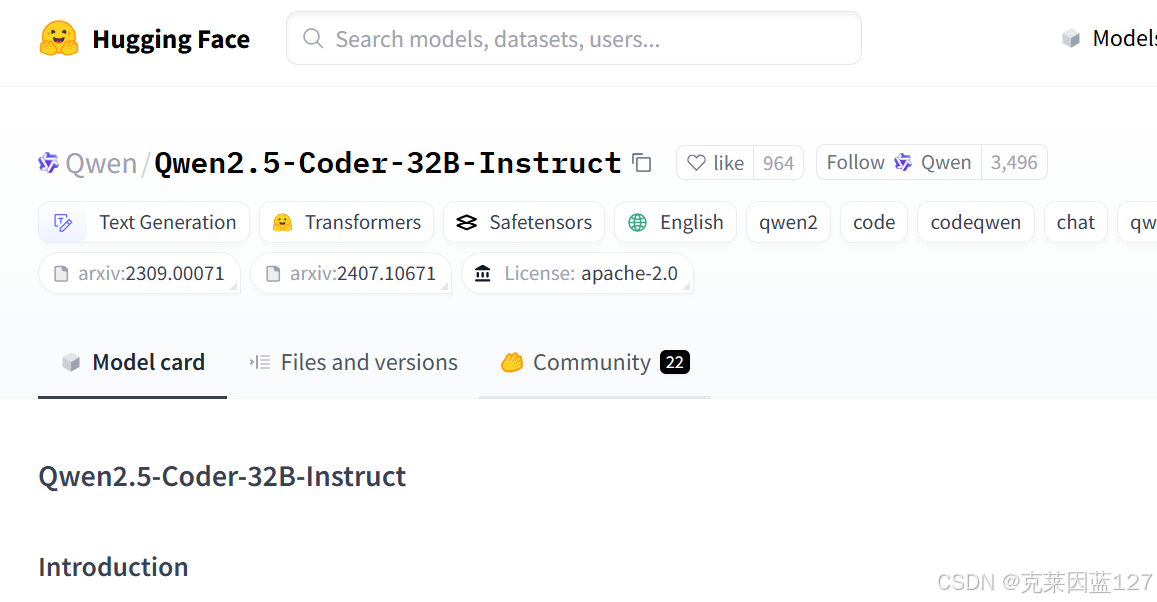
如果想要下载源码,就需要点击files and versions,但是hugging face不能够像GitHub一样打包下载,需要每个文件逐个下载,或者使用git clone这种克隆方式。
或者点击那三个点的标志,使用gitclone:

但是需要注意的问题是:当下载任意文件夹里的文件,该文件都会被在原始名字上加上该文件夹的前缀,这里需要在本地检查和更改每一文件名,不然代码复现过程中会运行失败。
hugging face快速复现大模型
在下载完了所有代码和权重后,点击model card,一般模型都会有,然后找到quick start,以上面这个模型为例,找到model card里的quick start,就是如下内容:

接下来把这个文件复制到本地,做成一个.py或者可执行的文件,然后运行该文件即可,但是需要注意,要在该段代码中修改你本地的代码路径,即;model name那行的双引号内容替换成你代码所在的路径就好了。
像llama系列,qwen系列,OpenGVLabIntern系列,stable diffusion系列等大模型都可以用这种方法复现。
好啦,以上就是关于hugging face网站的使用,感兴趣的小伙伴可以解锁下该网站,还是挺神奇的!
后期会给大家分享几个关于qwen ,stable diffusion等大模型的复现过程和大模型复现过程中会遇到的问题。

















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









