







1.自然语言是什么,就是我们平时交流的语言。那自然语言处理(natural language processing)是什么?
答:是一种能够让计算机理解人类语言的 技术。换言之,自然语言处理的目标就是让计算机理解人说的话,进而完成 对我们有帮助的事情。
那问题又来了,如何让计算机”理解“人类的语言,从而帮助我们提高工作效率?
比如,“WC”有时候是厕所的含义,而有时候又是汉语中词语的一个简称,表示惊讶或者愤怒等。
上面这个例子我们可以看出,自然语言是活着的语言,具有“柔软性”。因此,要让“头脑僵硬”的 计算机去理解自然语言,使用常规方法是无法办到的。但是!!如果我们能办 到,就能让计算机去完成一些对人们有用的事情。比如搜索引擎和机器翻译就是两个比较好理解的例子,还有问答系统、自动文本摘要和情感分析等,在我们身边就有很多已经使用了自然语言处理技术。
那么接下来就有一些巧妙地蕴含了单词含义的表示方法。这些方法都是前人的经验,不是我创造的哈,哪三种?
1.基于同义词词典的方法
2.基于计数的方法
3.基于推理的方法(word2vec)
接下来让我一一解读!
一,同义词词典.
这个方法比较冷门,其实大概说说概念就可以了,因为现在用的最多的是后面两个方法(尤其是第三个)。
首先在同义词词典中,具有相同含义的单词(同义词)或含义类似的单词(近义词)被归类到同一个组中。比如,使用同义词词典,我们可以知道car的同义词有 automobile、motorcar 等

另外,在自然语言处理中用到的同义词词典有时会定义单词之间的粒度 更细的关系,比如“上位-下位”关系、“整体-部分”关系。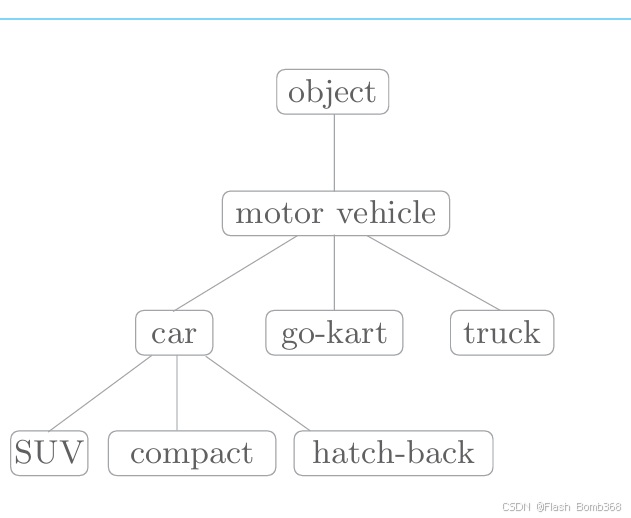
单词motor vehicle(机动车)是单词car的上位概念。 car 的下位概念有SUV、compact和hatch-back等更加具体的车种(如果有点难,请先停下来好好思考一番)
因此,我们可以将单词含义(间接地)教给计算机, 然后利用这一知识,就能让计算机做一些对我们有用的事情。
那么这里就有一个最著名的同义词词典是WordNet,他就是一个词典,别怕,他就是一个“类似”新华词典的东西。
WordNet 等同义词词典中对大量单词定义了同义词和层级结构关系等。 利用这些知识,可以(间接地)让计算机理解单词含义。但是呢,人工标记也存在一些较大的缺陷,什么缺陷?
首先最主要的是我上面举的例子,WC有时候是厕所,有时候是惊讶什么的,谁知道过了多长时间以后还会有什么新的含义?
其次人力成本高,制作词典需要巨大的人力成本。比如我草,原本一个人称代词我和名词草,合在一起成为了感叹词,在某些情况下还有别的含义(具体别的什么含义请各脑补),我不知道哈!像这样的字或者词还有很多,那对如此大规模的字与字之间进行关联,你想人得有多累!(牛马伤心)。
那么为了避免上面的问题,那么就主要运用以下两种方法:
基于计数的方法和利用神经网络的基于推理的方法。
二,基于计数的方法
慢慢有意思了,这个方法就是将使用语料库(corpus)。简而言之, 语料库就是大量的文本数据。但语料库并不是胡乱收集数据,它包含了大量的关于自然语言的实践知识,即文章的写作方法、单词的选择方法和单词含义等等。那么基于计数的方法的目标就是 从这些富有实践知识的语料库中,自动且高效地提取本质。
接下来上代码了要,首先来看一下作为语料库的样本文章:
text = 'You say goodbye and I say hello.'因为是入门,那么我们使用由单个句子构成的文本作为语料库。本来文本(text)应该包含成千上万个(连续的)句子;那么第一步我们进行预处理----分词
text = text.lower()
text = text.replace('.', ' .')
print(text)
# 'you say goodbye and i say hello .'
words = text.split(" ")
print(words)
# ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']首先,使用lower()方法将所有字母转化为小写,这样可以将句子开头的单词也作为常规单词处理(不然You和you在计算机看来就是不同的意思),然后,将空格作为分隔符,通过split(' ')切 分句子。考虑到句子结尾处的句号(.),我们先在句号前插入一个空格(即通过replace函数用“ .”替换“.”),再进行分词。
现在,我们已经可以将原始文章作为单词列表使用了。虽然分词后文本更容易处理了,但是直接以文本的形式操作单词,总感觉有些不方便(你想,如果一旦文本多了,全都是英文单词,你自己都看麻了)。因此进一步给单词标上ID,以便使用单词ID列表。(其实就是后面的单词向量化)为此,使用 Python 的字典来创建单词ID和单词的对应表。(不会的后面站着去!)
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
print(word_to_id)
print(id_to_word)以上代码中,变量id_to_word 负责将单词ID转化为单词(键是单词ID,值是单词), word_to_id 负责将单词转化为单词ID。这里,从头开始逐一观察分词后 的words 的各个元素,如果单词不在word_to_id中,则分别向word_to_id和 id_to_word 添加新ID和单词。另外,我们将字典的长度设为新的单词ID, 单词ID按0,1,2,···逐渐增加。
使用这些词典,可以根据单词检索单词ID,或者反过来根据单词ID检 索单词。
最后,我们将单词列表转化为单词ID列表。这里,我们使用Python 的列表解析式将单词列表转化为单词ID列表,然后再将其转化为NumPy 数组。
import numpy as np
corpus = [word_to_id[w] for w in words]
corpus = np.array(corpus)
print(corpus)
# array([0, 1, 2, 3, 4, 1, 5, 6])至此,我们就完成了利用语料库的准备工作。现在,我们将上述一系列 处理实现为preprocess()函数.
import numpy as np
def preprocessing(text):
text = text.lower()
text = text.replace(".", " .")
words = text.split(" ")
word_to_id = {}
id_to_word = {}
for word in words:
if word not in words:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
# 实例化
text = "You say goodbye and I say hello"
corpus, word_to_id, id_to_word = preprocessing(text)
print(corpus, word_to_id, id_to_word)到这里,语料库的预处理就结束了。这里准备的corpus、word_to_id和 id_to_word 这 3 个变量名在本书接下来的很多地方都会用到。corpus是单词 ID 列表,word_to_id 是单词到单词ID的字典,id_to_word是单词ID到单词 的字典。 现在,我们已经做好了操作语料库的准备,接下来的目标就是使用语料 库提取单词含义。为此,本节我们将考察基于计数的方法。采用这种方法, 我们能够将单词表示为向量.下一节是单词的分布式表示,感谢你收看到这里,希望能帮助到你!

















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









