







目录
0 混淆矩阵
| 预测情况 | 真实情况 | |
| 1 | 0 | |
| 1 | TP | FP |
| 0 | FN | TN |
- P(Positive):代表1,表示
预测为正样本- N(Negative):代表0,表示
预测为负样本- T(True):代表
预测正确- F(False):代表
预测错误
1 基本指标
1.1 准确率(Accuracy)
Accuracy=(TP+TN)/(TP+TN+FP+FN)
1.2 精确率(Precision)
Precision=TP/(TP+FP)
1.3 召回率(Recall)
Recall=TP/(TP+FN)
例如医学诊断中,预测患病并且真的患病的病人占全部患病病人的比例。
2 F1值
recall和precision的调和平均数
1. recall的重要性是precision的β倍
2. F1是β=1时候的特殊情况
3. F1值越高越好。它表示模型在精确率和召回率之间取得了较好的平衡

3 G分数
G分数被定义为召回率和精确率的几何平均数
G分数越高越好。它表示模型在精确率和召回率之间取得了较好的平衡,适用于在处理正负样本不平衡时评估分类器性能。
4 ROC曲线和AUC值
| 预测情况 | 真实情况 | |
| 1 | 0 | |
| 1 | TP | FP |
| 0 | FN | TN |
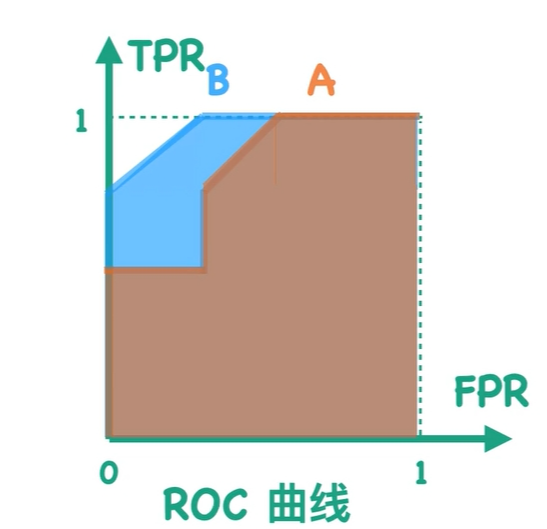
ROC曲线纵坐标为TPR,横坐标为FPR,在不断改变阈值时形成的曲线
1.TPR(召回率)
2. FPR(假阳性)
说明:
1)对于同一个测试集来说,P(真实为1)和N(真实为0)的值是不变的
2)TP为分对的情况,FP为本来应该为0的结果预测成了1,所以TRP越大并且FRP越小时,越好
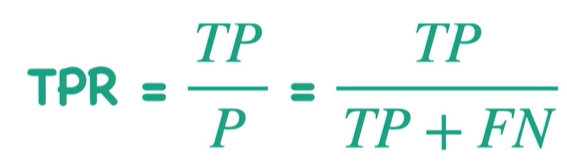
AUC:ROC曲线围成的面积(0-1之间)越大越好
AUC值越大,当前的分类算法越有可能正样本分值高于负样本分值,既分类效果更好
5 写在最后















 6654
6654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









