






文章目录
DBSCAN聚类算法
基本思想
-
看看维基百科的解释

-
DBSCAN的核心就是簇的扩张,先确定一个没有访问过的点,如果该点满足条件(设置的eps内有足够的阈值)那就标记为核心点,然后在该点创建一个新的簇,将该点领域里面的点也归类到这个簇里面,然后对里面的点也标记为核心点进行延伸,在这些点的领域内的点也放到这个簇里面,然后一直扩展直到那个点不满足于条件(设置的eps内没有足够的阈值),这就是访问完毕了。
基本概念
-
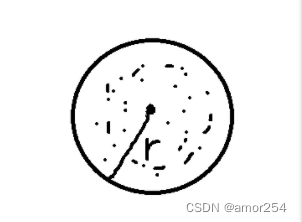
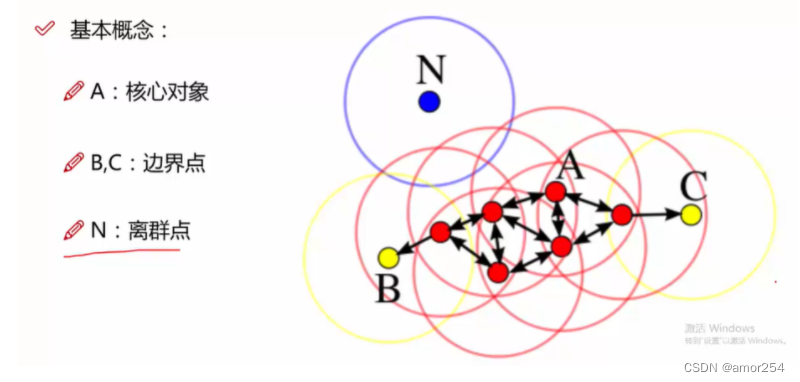
核心对象: 若某个点的密度达到算法设定的阈值(人为设置的)则其为核心点(即r领域内点的数量不小于minpts) (minpts就是自己设置的阈值 r就是这个点的领域范围)
-
∈-领域的距离阈值:设定的半径r
-
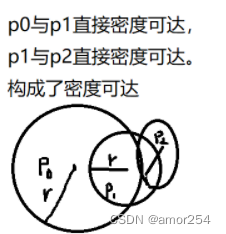
直接密度可达:若某点p在点q的r领域内,且q是核心电脑则p-q直接密度可达
-
密度可达:若有一个点的序列q0,q1,…qk,对任意qi-qi-1是直接密度可达的,则称从q0到qk密度可达,这实际上是直接密度可达的“传播”
-
密度相连:若从某核心点p出发,点q点k都是密度可达的,则称点q和点k是密度相连。
-
边界点;属于某一个类的非核心点,不能发展下线了
-
噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达(所有簇都不可以圈住的点)
工作流程

参数选择
-
半径

-
MinPts

DBSCAN的优劣势
- 优势
- 不需要指定簇的个数
- 可以发现任意形状的簇
- 擅长找到离群点
- 两个参数就够了
- 劣势
- 高纬数据有些困难(可以做降维)
- 参数难以选择(参数对结果的影响非常大)
- Sklearn中效率很慢(数据消减策略)
- 机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
- sklearn的特点
- 简单高效的数据挖掘和数据分析工具
- 让每个人都能够在复杂环境中重复使用
- 建立Numpy,Scipy,MatPlotLib之上
代码分析
Matplotlib Pyplot
-
Pyplot是Matplotlib的子库,提供了和matlab类似的绘图API
-
Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。
-
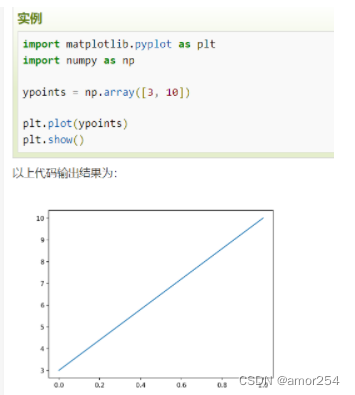
# 画单条线 plot([x], y, [fmt], *, data=None, **kwargs) # 画多条线 plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs) -
**x, y:**点或线的节点,x 为 x 轴数据,y 为 y 轴数据,数据可以列表或数组。
-
**fmt:**可选,定义基本格式(如颜色、标记和线条样式)。
-
****kwargs:**可选,用在二维平面图上,设置指定属性,如标签,线的宽度等。

- 如果我们不指定 x 轴上的点,则 x 会根据 y 的值来设置为 0, 1, 2, 3…N-1。
-
import matplotlib.pyplot as plt import numpy as np # xpoints=np.array([0,6,6,0]) # ypoints=np.array([0,100,0,0]) # print(xpoints,ypoints) # plt.plot(xpoints,ypoints,'bo')#蓝色实心绘制 # plt.show() #plot函数是绘制二维图形的最基本函数 #绘制正弦与余弦图 #两者的区别仅仅是arange返回的是一个数据,而range返回的是list 。 x=np.arange(0,4*np.pi,0.1)#start0 stop 4pi step 0.1 y=np.sin(x) z=np.cos(x) plt.plot(x,y,x,z) plt.show()
make_blobs
- make_blobs函数是为聚类产生数据集,产生一个数据集和相应的标签
StandardScaler
- 作用
- 去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本
- 对特征数据进行归一化
- np.mean求均值,np.std求标准差
- 标准差标准化
-
- 归一化后加快了梯度下降求最优解的速度;
- 归一化有可能提高精度;
- fit_transform()
- 功能
- 计算均值和标准差,用于以后的缩放
- 缩放
- X:二维数组
- 功能
axes类使用
- axes类(轴域类),该类对象被称为axes对象(即轴域对象),它指定了一个有数值范围限制的绘图区域。在一个给定的画布(figure)中可以包含多个axes对象,但是同一个axes对象只能在一个画布中使用
plt.cm.Spectral颜色分配

python numpy 中linspace函数
- 与Numpy arange函数类似,生成结构与Numpy 数组类似的均匀分布的数值序列。
- 通过定义均匀间隔来创建数值序列,其次需要指定间隔起始点,终止端,以及指定分隔值总数(包括起始点和终止点),最终函数返回间隔类均匀分布的数值序列
enumerate()函数
-
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
-
语法
-
enumerate(sequence, [start=0]) -
sequence – 一个序列、迭代器或其他支持迭代对象。start – 下标起始位置的值。
-
返回enumerate(枚举) 对象。
-
plt.scatter()绘制散点图
-
作用:用于散点图的绘制
-
基本参数

整体代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
UNCLASSIFIED=0
NOISE=-1
#计算每一个数据点与其他每个点之前的距离
def getdatadisstance(datas):
line,column=np.shape(datas)#返回datas里面列,行的数目
dists=np.zeros([line,line])#创建一个初始值为0 column*column的矩阵
for i in range(0,line):
for j in range(0, line):
vi=datas[i,:]
vj=datas[j,:]
#通过把第每一行的数据与其他行的数据进行矩阵乘法开根号得到两点之间的距离
dists[i,j]=np.sqrt(np.dot((vi-vj),(vi-vj)))
return dists#返回一个矩阵
def find_near_pionts(point_id,eps,dists):
#得到point_id周围的点和它的距离 如果周围的点距离小于该点围起来的eps 那么返回true说明是该点的临近点
index=(dists[point_id]<=eps)
return np.where(True==index)[0].tolist()#tolist()是将矩阵转换成列表
def expand_cluster(dists,labs,cluster_id,seeds,eps,min_points):
#获取一个临近点 对该点进行处理
i=0
#遍历到该点大于seeds的点数为止 这样就可以保证每个点都被归类到
while i<len(seeds):
Pn=seeds[i]
if labs[Pn]==NOISE:
labs[Pn]=cluster_id
elif labs[Pn]==UNCLASSIFIED:
#把该点归类为当前簇
labs[Pn]=cluster_id
#计算该点的临近点 创建一个新的临近点
new_seeds=find_near_pionts(Pn,eps,dists)
#让该临近点归类为原来的点
if len(new_seeds)>=min_points:
seeds=seeds+new_seeds
else:
continue
#自加 开始下一次循环
i=i+1
def DBSCAN(datas,eps,min_points):
#得到每两点之间距离
dists=getdatadisstance(datas)
n_points=datas.shape[0]#shape返回第一维度的参数,得到行的数目
labs=[UNCLASSIFIED]*n_points
#将全部点设为没有被标记的点(0)
cluster_id=0#其实簇id为0
#遍历所有点
for point_id in range(0,n_points):
#如果当前点已经被标记 那么跳过这个点 进行下一个点的遍历
if not(labs[point_id]==UNCLASSIFIED):
continue
seeds = find_near_pionts(point_id, eps, dists) # 得到该点的临近点,用这些点来进行扩展
#如果临近点周围的点数小于设置的阈值 那么标记其为噪声点
if len(seeds)<min_points:
labs[point_id]=NOISE
else:
#如果该点没有被标记 簇加1 然后进行扩张
cluster_id=cluster_id+1
#标记该点的当前簇值
labs[point_id]=cluster_id
expand_cluster(dists,labs,cluster_id,seeds,eps,min_points)
return labs,cluster_id
#进行该簇的扩张(聚类扩展)
def draw_cluster(datas,labs,n_cluster):
plt.cla()#清楚axes 清除指定范围的绘图区域
#用推导式 为聚类点分配颜色
colors=[plt.cm.Spectral(each) for each in np.linspace(0,1,n_cluster)]
for i,lab in enumerate(labs):#i为返回下标的值 lab为labs里面的标记值
if lab==NOISE:
plt.scatter(datas[i,0],datas[i,1],s=16,color=(0,0,0))
else:
plt.scatter(datas[i,0],datas[i,1],s=16,color=colors[lab-1])
plt.show()
if __name__=="__main__":
#打开文件 导入数据
file_name="jain"
#以只读方式打开文件 这是默认的方式 编码格式为 utf-8
with open(file_name+'.txt','r',encoding='utf-8') as f:
lines=f.read().splitlines()#读取数据 并且存储在一个列表里面
lines=[line.split("\t")[:2] for line in lines]
#split通过一个tab(\t)距离的指令来分隔开字符串并且取前两个数据做为一个列表元素
datas=np.array(lines).astype(np.float32)
#将列表转换为矩阵数组矩阵 astype可以将数组里面的数转换成浮点数
#数据正则化
datas=StandardScaler().fit_transform(datas)
#StandardScaler函数用来对数据的归一化处理 fit_transform对数组标准差的标准化
eps=0.2#设置的种子点的搜索半径
min_points=5#设置的阈值 大于此阈值既可以标记为一个种子点
labs,cluster_id=DBSCAN(datas,eps=eps,min_points=min_points)
draw_cluster(datas,labs,cluster_id)
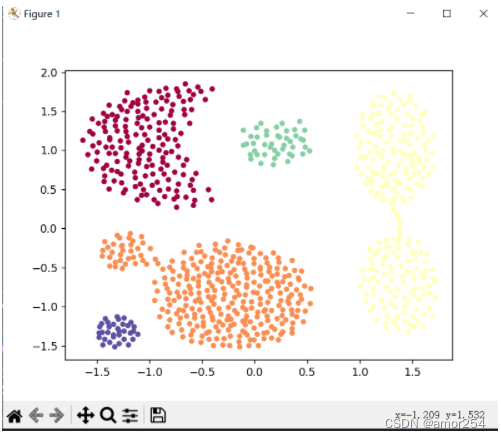
- 可视化效果
参考文章
https://blog.csdn.net/Joyce_Ff/article/details/91955640
参考视频
https://www.bilibili.com/video/BV17Y4y1v7XH/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1vL41147Ah/?spm_id_from=333.337.search-card.all.click&vd_source=1e0628d472510a4049e6a6e9a12fb1da
数据集链接:https://pan.baidu.com/s/1FeckeC2er84CpMzb55TdDA
提取码:2580















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









