






游戏世界的组成
动态物体,静态物体,环境,其他物体(例如空气墙)。
游戏物体的构建
基本上游戏物体是由属性和行为这2个类来构成的。基本思想就是面向对象语言的思想。但是如果一个一个类的构成就会造成“水陆2用的东西是船还是车”的问题,这时候就用到了组件封装的思想。按照需求来选择各种组件来组合成自己需要的东西。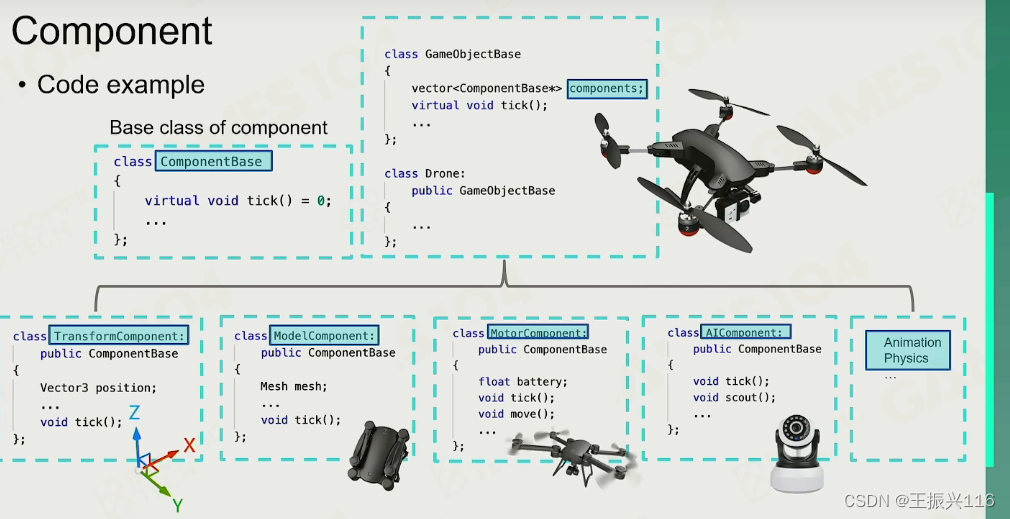
现在的游戏引擎大部分用的就是组件的思想。
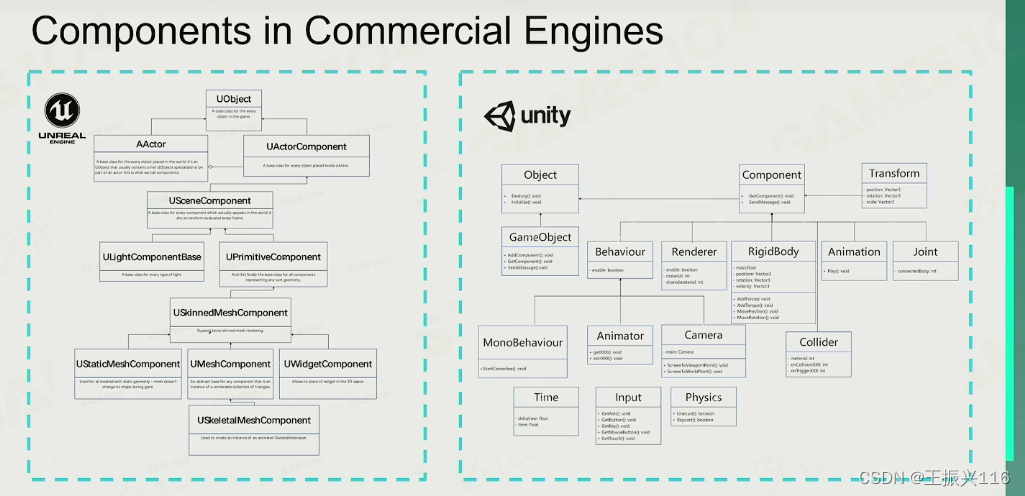
怎样使世界动起来
使用tick,每隔一段时间,使静止的世界向前动。
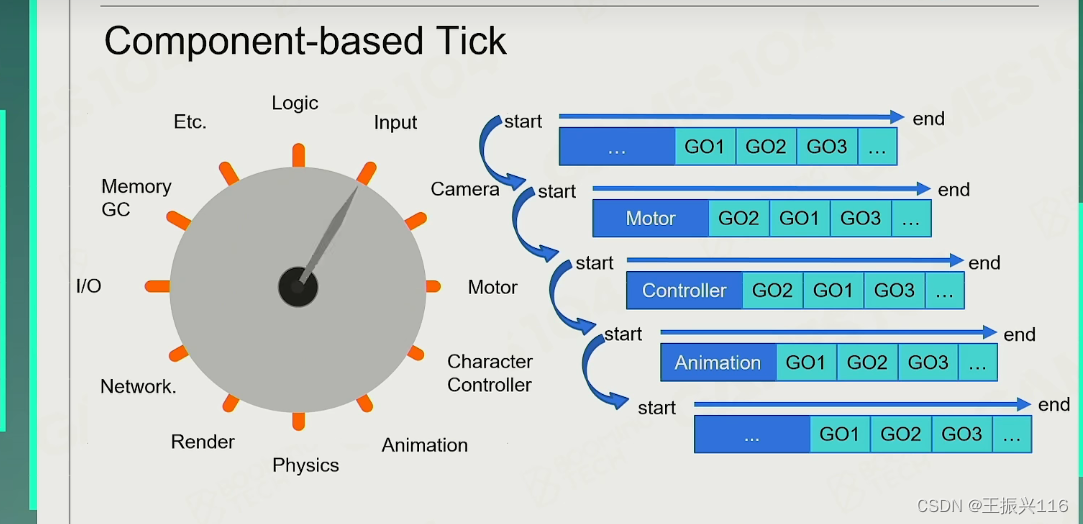
这种tick就是类似于流水线的工程,相同部分一起进行。传统每个对象的tick效率太低。
交互
hardcore,类似于表格一样的,发生事件时,一个一个查询各个物体的状态。
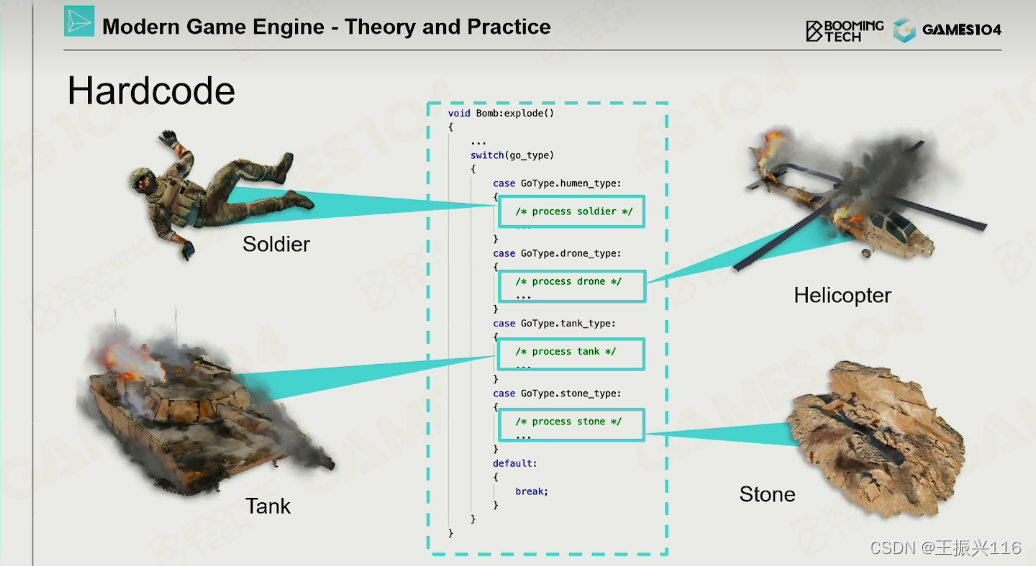
开始的是通过Hardcore来进行交互,
现在都是events,事件系统-观察者模式。(unity中的sendMessage函数就是此机制,在该函数调用的时候,会向上层发送消息,来调用上层的函数)
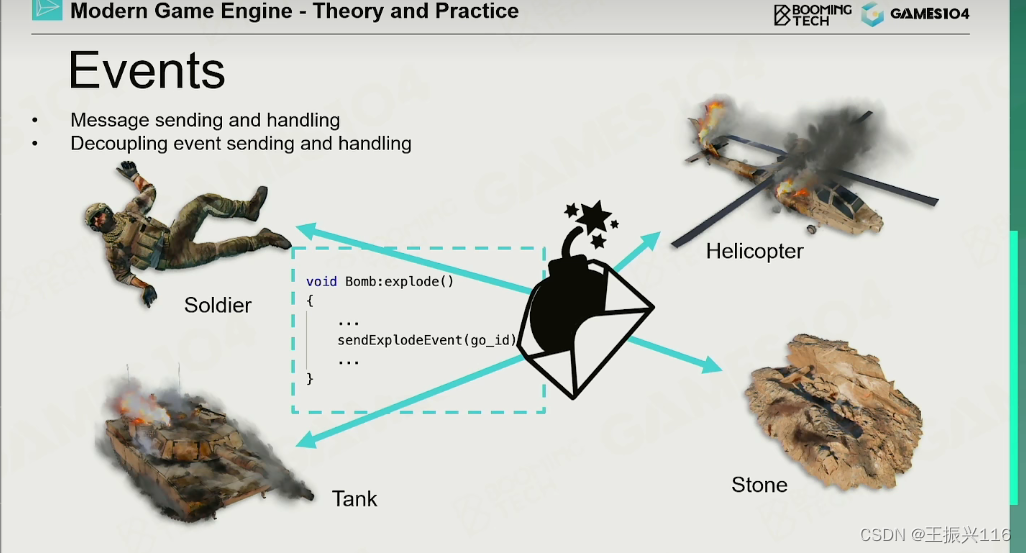
可扩展的消息系统是游戏引擎的重要原则之一。
但是tick可能会出现时序问题(类似于2个人同时说分手,那么谁甩了谁的问题),在多线程执行的时候往往会产生这个问题,所以会应用“邮局”的机制。不会直接把消息发送给物体,而是通过邮局来进行时序性的信息发送。
如何管理游戏对象
通过唯一的标识号,位置。
比较实用的场景管理方法是类似于国家,省,城市的划分方法。可以大幅度减少资源的调用,提高效率。

总结
一切都是一个物体
游戏对象可以用基于组件的方式描述。
游戏对象的状态在tick循环中被更新。
游戏对象通过事件机制相互作用。
游戏对象在场景中被管理,具有有效的策略















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









