






Animation Blending 动画调合
与上节课不同的是,插值是在不同动画下各去一帧进行插值。
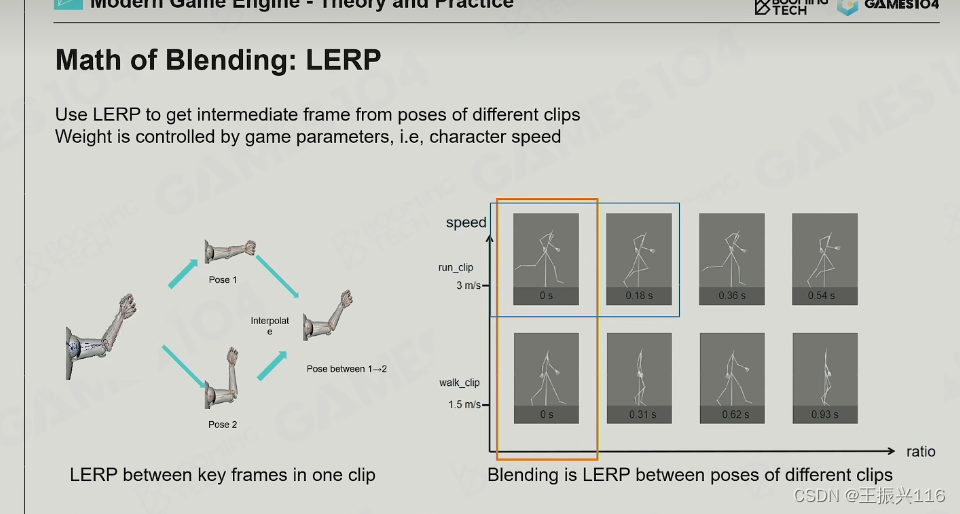
算法与上节课的一样重点是权重的计算,如图 :权重是当前速度与前一帧与后一帧有关。
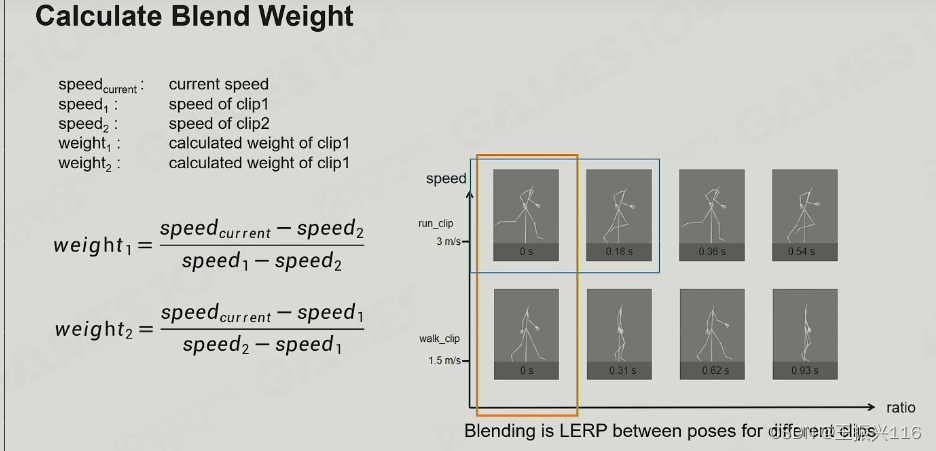
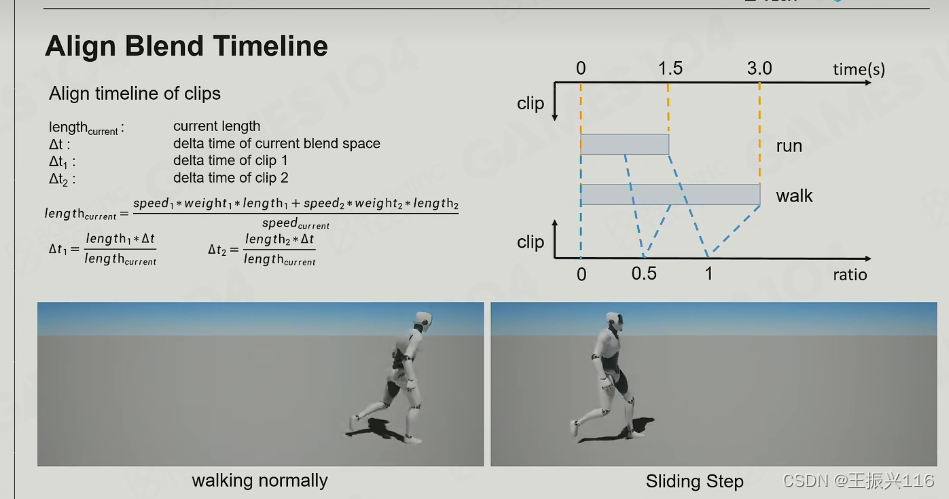
难点是不同动画的某些相同动作的频率是不一样的,这时候就需要归一化了。这是不同动画可以blend一起的原因。虽然线性插值本身简单,但其实现的一个重要前提是能够找到两个clip中匹配的对应pose(帧)去做插值,因而我们需要艺术家在做DCC(Digital Content Creator)时确保两个clip的节奏相同,这样可以在归一化后保证每一帧都对应一样的动作(比如取时间t时走的pose是踏在地上,跑也是一样,只是动作有所不同)。从而方便后续插值,这也是因为动画是不断循环所致,不然这帧吻合,下一帧因为两个clip节奏不同就不行了。
如下图就是跑是走的速度的两倍时如何根据当前速度进行插值时时间线上的变化(其中length是指时间长短),delta time是指要去对应clip1和clip2的哪一个时间帧去取对应的pose。
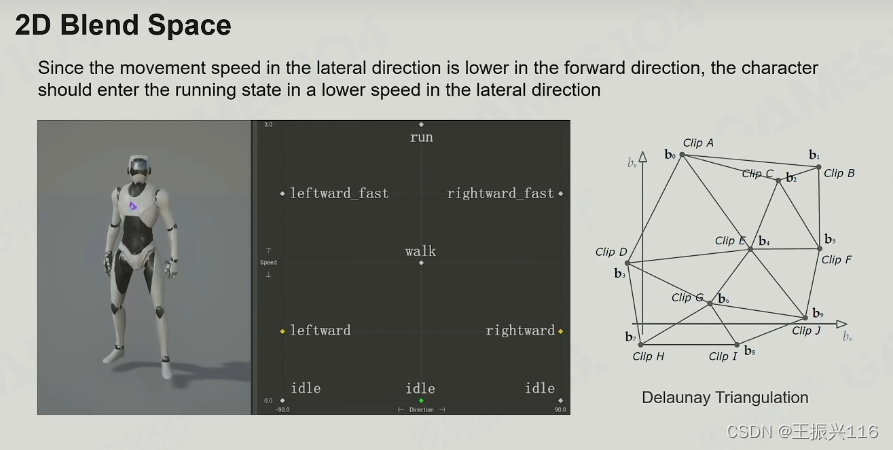
2D Blend Space 二维混合空间
2维的采样空间,与一维的类似。
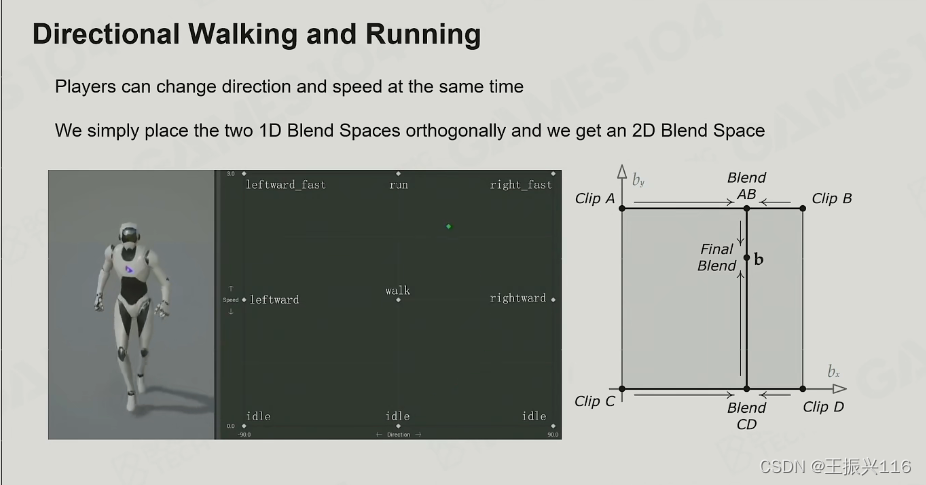
此时如果对每一帧插值都要对所有clip去插值,则cost太高了,所以实际处理中会利用德劳内三角化将这些clip化成不同三角形,然后根据当前的速度和方位确定当前的点在哪里,哪个三角形内。最后用重心插值对三角形的三个点(三个clip)进行插值。
Skeleton Masked Blending
当我们想融合某个动画且这个动画只对角色的局部起到影响时,就可以使用一个blend mask去遮住无关的部分,只对需要的部分进行blend。比如角色的鼓掌动画只对上半身产生影响,所以我们可以在blend mask中将下半身的骨骼设为0(遮住),从而实现在各种状态下(站立、蹲下、做下、行走等)的鼓掌动作。
Addictive Blending
这个方法只存放这个动画的变化量而不存储绝对量。
当我们在以上基础上想再加一个点头的动画,那么可以使用addictive blending。这个技术提出一个概念:difference clip。不同于常规的完整的一个动画clip,它是作为差值存在,即加在其他clip上从而产生进一步效果的一种clip。具体可能表现为一个旋转或一个scale变化等。addictive blending一般使用和制作的比较谨慎,因为容易带来问题,比如本身转头这个addictive blending没什么问题,但是如果肩膀已经转的基础上头仍可以转原来的极限角度,则会导致超过头实际能扭的角度,从而看起来很不自然
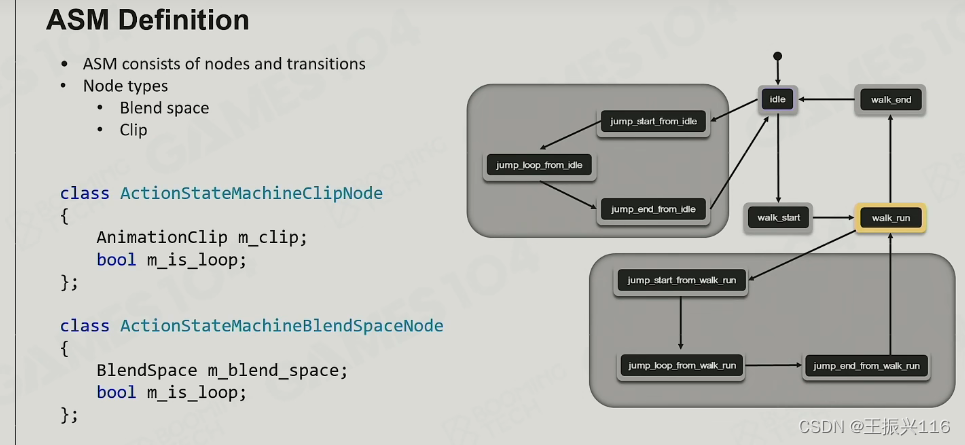
Animation/Action State Machine(ASM)状态机
状态机的2元素:节点和转换。
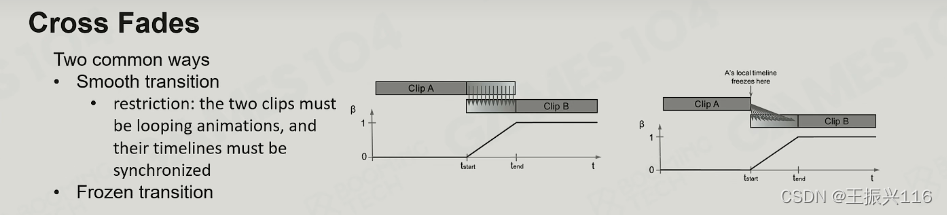
Cross Fades
当进行transition的时候如果要进行插值,会有两种常见的方式:
常规的smooth transition。即像上述所讲的一样在符合可以同步前提下进行两个动画clip下的blending。
Frozen transition。在上一个动作完成过程中将一个动作blending进来,表现为上一个动作做到一半(即做到第二个动作即将进来的瞬间状态)时加入第二个动作。
在从“跑步”到“起跳”为例的transition中,前者会产生跳起来后仍有部分跑步的样子(形式原地跳但同时在跨步),而后者则会产生从跑着停滞下来跳起来的感觉。
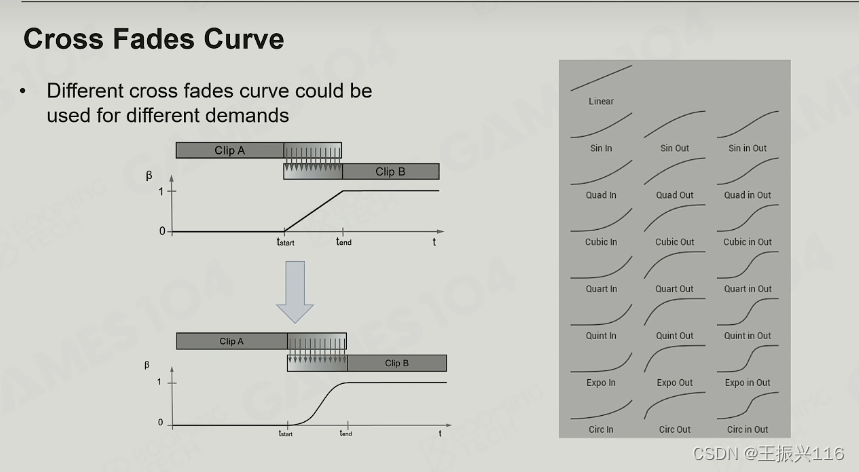
但一般来说实践中基本上只用到左边所述的两种:线性和“easy in easy out”。后者一般是用cubic-bazier曲线来表示,来实现一种“平滑-陡峭-平滑”的融合过程(感觉就是让融合发生的核心部分在很短时间内完成)
另外,像上面提到的,ASM的节点可以远不止一个动画,而transition的具体设置也可以自定义。
Animation Blend Tree 动画混合树
在了解ASM之后,经典的一种处理是layered ASM,它是把角色的不同部位分成不同的状态机去使用,利用不同的状态机去管理身体的不同部分,从而让整个动画看起来更流畅和灵活。
而随着技术的发展,现在普遍使用的是动画混合树。
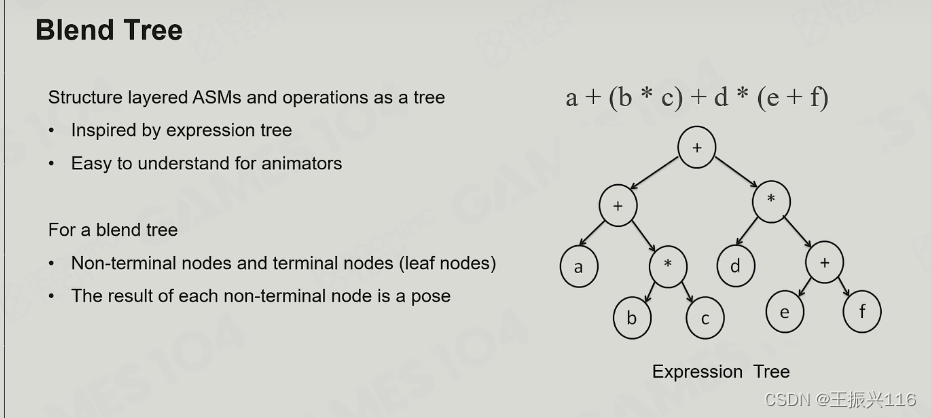
动画树的一个特点是递归:
因为动画树中叶节点可以是单个动画clip、blend space以及ASM三种内容,所以导致其叶节点本身也可以是一个内含很多node的小动画树。
另外,动画树的核心作用是控制变量,动画树会定义大量变量暴露给外面的game play系统来进行控制,而这些变量的值决定了动画的混合行为。
通过这个设计,我们只需设置这些变量的值就可以决定动画实现。
变量有两种,一种是环境变量,比如有一个变量是角色当前血量,如果设定到了50%以下就切换成虚弱的动画。
还有一类变量类似于类的private data,通过event触发去进行调整。event概念引用于UE,即事件。当某件事发生的时候,会改变动画树中的某些变量,从而影响动画混合效果。

IK技术 Inverse Kinematics
简单来说,根据动画移动到某个位置属于FK,要根据要到的位置设计动画属于IK。而end-effector就是一个让角色移动到某个位置的效果器。
IK问题的经典例子是在不平的路上走路,或者用手抓某个物体等。
Two Bones IK
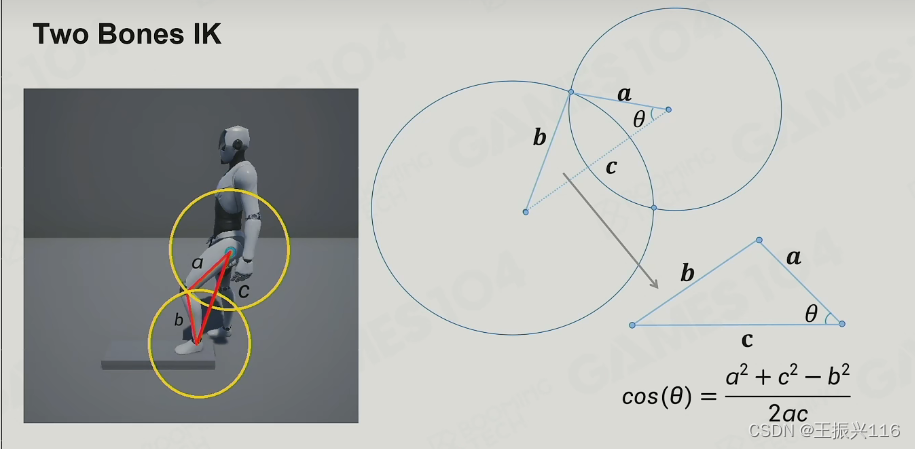
两根骨骼(大腿小腿)形成了一个三角形,如果确定了最后要踩在哪个位置,则可以算出c的大小,从而利用余弦公式算出大腿需要抬起来的角度θ。
这样做会存在一个问题,就是不确定这个三角形会在哪个平面(膝盖可能内翻也可能外翻),这是因为大腿和小腿本身的旋转就不只是局限于前后平面。
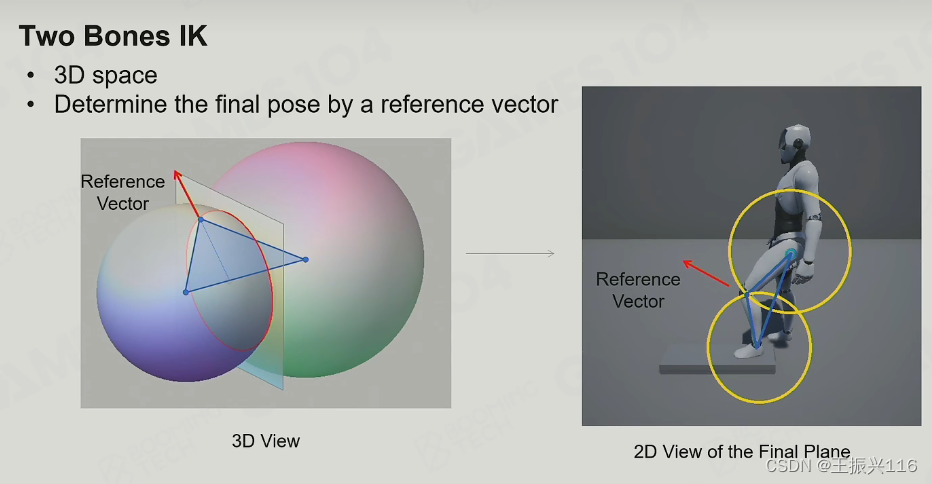
解决方案是让艺术家提供一个reference vector,再加上大腿根到脚的连线,从而可以确定一个平面,而这个平面和大腿旋转的球以及小腿旋转的球结合起来可以把膝盖的位置缩小到两个点,再利用向量点积的正负结果判断膝盖应该是弯向前而不是逆向的。
(另一种或许更容易理解的解释和是:本身大小腿的两个球形空间相交与一个圆,而reference vector和大腿根到脚连线形成的平面与这个圆又相交,从而形成两个点)。

Multi-Joint IK
事实上,大部分IK问题都没有Two Bones IK那么简单。当涉及到多个Joint的时候,IK问题存在两个难点:
多维的非线性的问题很难在实时中计算
很多情况下会存在非唯一解
此时首先要做的第一步是判断可达性,即先判断角色能不能到达目标位置。而不能达到分两种情况:
全身所有骨骼加起来都没法碰到目标位置
全身所有其他骨骼加起来的总和与最长的骨骼比起来的差大于目标位置的位置。
具体如下图:
除了可达性判断外,另外很重要的一点是骨骼的旋转是受限的,尤其是人体,不同骨骼的旋转模式不一样。错误的处理会导致很离谱的扭曲。
那么具体怎么处理呢?
由于直接针对高维算式去解存在成本高以及不一定完全正确的问题,所以在工程中开发出了一些实际好用的方法如
CCD

其具体逻辑如principle所述。
针对CCD,后续又提出了一些优化,比如:
限制每次旋转的角度( tolerance regions),从而让整个旋转尽量均摊到每个joint上。
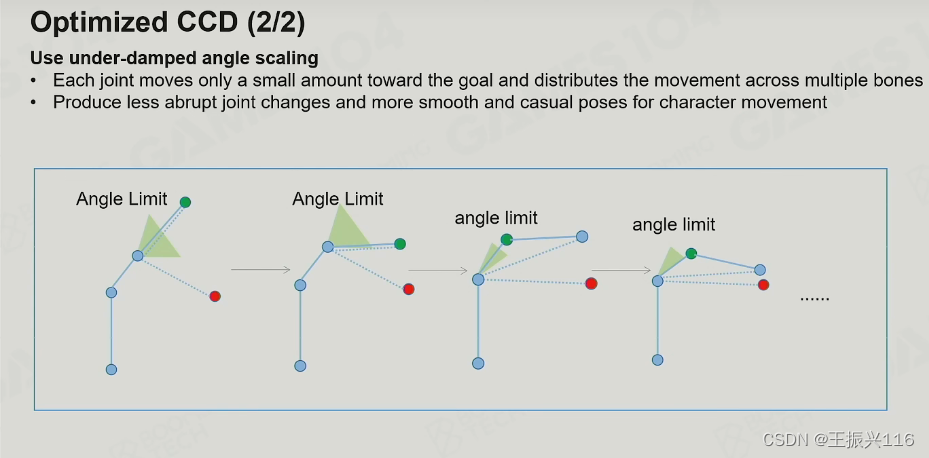
让越靠近根节点的joint旋转角度越小等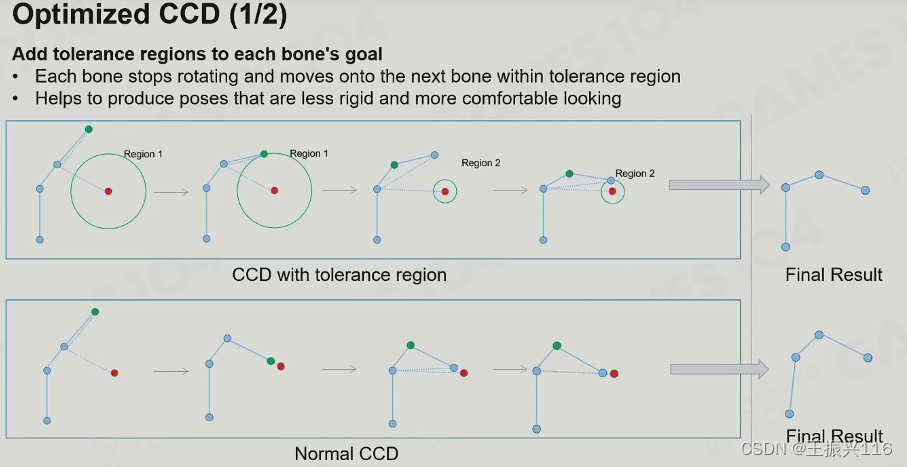
越靠近根节点的运动幅度越小,反之越大。这样符合人体工程学。
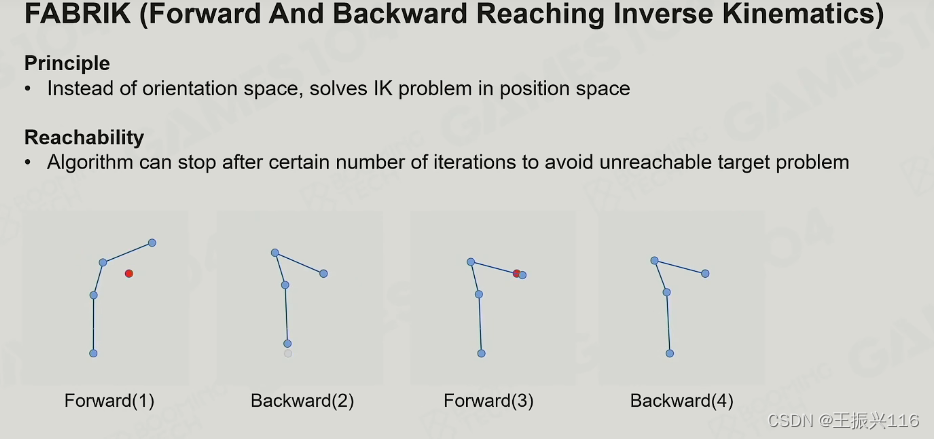
FABRIK
FARBRIK(Forward And Backward Reaching Inverse Kinematics),其原理如下:
首先,forward:从最后一个joint开始,把它强行拉到目标位置,然后因此会导致它的骨骼移动,与上一个joint的连接出现偏差,于是就更新目标节点为它移动后的骨骼末尾,并拉动上一个joint到目标节点,不断迭代直至移动了根节点;
其次,backword:反向进行forward的步骤,先拉根节点,最后拉末尾节点
多次来回forward和backward之后,末尾节点就会很接近目标位置了。
https://blog.csdn.net/zhaishengfu/article/details/88195246
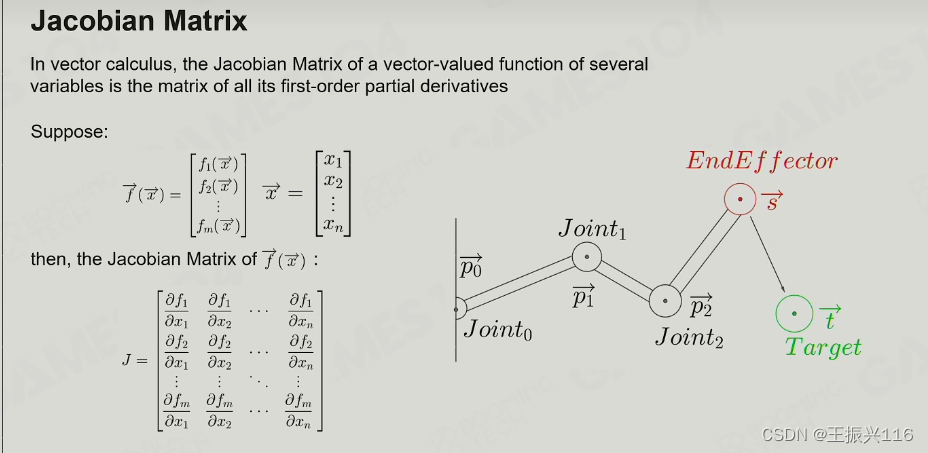
IK with Multiple End-Effectors
当控制点有很多时又会遇到不同问题(比如攀岩,同时需要设定的目标点不止一个)
因为当试图把一个点移到它的目标点时可能会让其他已经到位的节点又偏移开。
解决方法是:Jacobian Matrix(优化问题)

面部动画
一种面部表情称为一个action unit。一般归结人类表情有28种。
当我们进行表情融合的时候会有一个常见的问题,
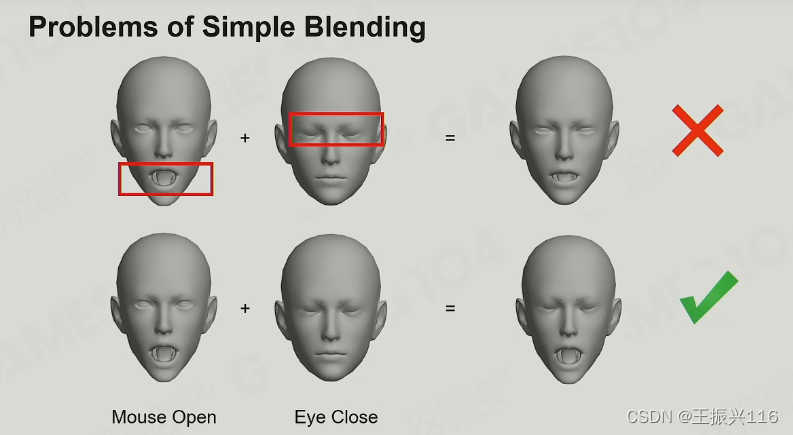
所以不同于其他动画blending,一般业内使用Morph Target Animation。简单讲就是blending总是以additive的形式去融合,比如直接在眼睛的位置上加上闭着的眼睛,而不会将睁着的眼睛和闭着的去做插值。
MF的问题是存储量大,并且随着表面细节增多计算量也会变很大
针对二维动画,UV Texture Facial Animation也经常使用,它是将不同的纹理贴图来代表不同的表情
另外,Muscle Model Animation也在发展中(主要在影视行业),它是直接基于物理去驱动面部的43块肌肉来实现各种表情。
动画重定向 Animation Retargeting
核心意思是将采集到的一套动画能够应用到不同角色上。
以将一个瘦小角色的动画应用到一个高胖驼背的角色上为例:
1、基本操作是将他们的骨骼一一对应,无视具体长短等强行对应
2、在发生旋转时转动的相对角度不变,即目标角色的旋转是在目标角色本身的姿态基础上进行的,而非在世界坐标系下达成和原角色一样的角度。位移和放缩也同理。
3、在发生平移时,除了一一对应外,还需要根据骨骼长度适当调整平移范围,发生放缩时也是根据长度调整。具体来说,我们以角色腰线高度为准,将角色的高低进行适当调整,并且一般位移的速度也会根据腰线高度适当放缩。
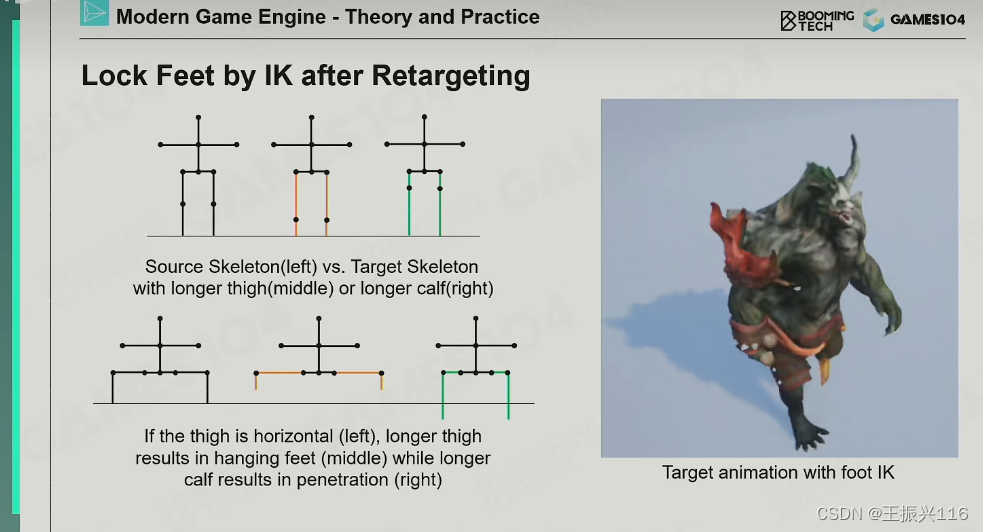
这种时候需要IK去解决
另外,上述所有都是基于大家骨骼架构整体相同的前提,但实际游戏中经常会有不同的,这时候怎么处理呢?
解决办法如下(来自NVIDIA)
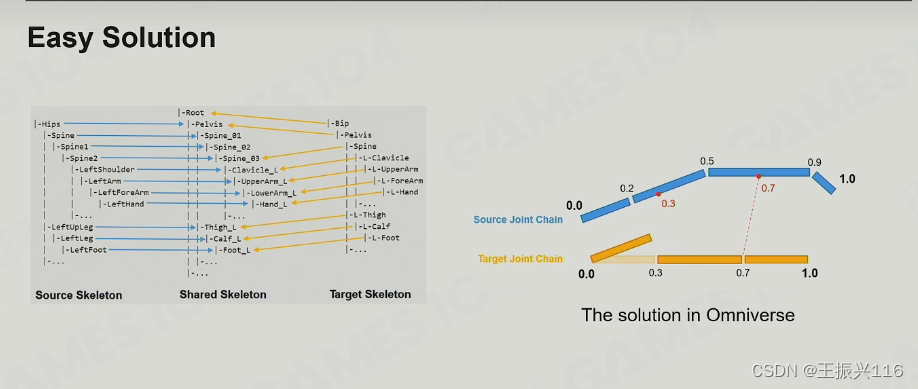
其实就是找到对应的两组骨骼,它们之间的骨骼数可能不同(如上图source是四块,target是三块),然后把之间的骨骼都归一化。针对target骨骼,去找每个骨骼对应source的位置,并适当调整(这里还是可以看一波网课)。
挑战:自网格渗透,自我接触的约束(如:鼓掌时的手),目标角色的平衡。另外,表情领域的MF也面临动画重定向问题,具体做法有如利用拉普拉斯算子解决artifacts等。
总结
控制动画配音系统是根据游戏情节动画角色的关键。
逆运动学帮助人物动画适应环境约束
面部表情可以用FACS中的动作单位编码
变形目标动画在人脸动画中得到了很好的应用。
延迟可以帮助重用角色之间的骨骼动画和面部动画。


















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









