







对知识蒸馏的方法提出了一个新的方向
采用多个不同的教师模型同时训练一个学生模型
一个很明显的好处 就是
多个教师model可以减少单个教师模型它的bias
但是当我们有多个老师的时候,
学生模型是否能够根据自己的能力选择和结合教师模型的特点
来选择性的向老师学习(根据老师的特点来主动学习)
这样的一个想法来自一个观察
一个厉害的老师不一定教出最优秀的学生

从这张图表当中我们可以看出这个假设
很显然 加了这个Ro 的 老师模型精度就是牛一点
学生模型选用了三层transformer
可以看出的是 原始的Bert 模型教的会更好
这个也有了解释
: 因为往往复杂的模型
这种大的模型可以捕捉到数据分布当中比较细微的模式记在自己的参数里面
但是对于小模型来说 三层的transformer 的学习能力并没有那么强
模型参数没有那么多
所以未必能学会很多的局部数据分布的特点
一点启发 根据学生的特点去 选择老师
以前几乎所有的 运用多个教师模型的知识蒸馏方法中都采用了固定的权重
所有的老师都采用相同的 固定的权重
根据学生的状态动态的调整不同教师模型的权重
对于不同的样本以及在训练的不同阶段 给不同教师模型分配的权重是不一样的
解决方案的关键是什么
怎么从多个老师中间得到最优
采用了一个强化学习的框架 是一个必然的选择
目的: 在训练的过程当中选择最合适的老师 策略问题
选择的依据 是学生遇到问题给出的反馈
我们想优化这个策略 又要根据学生的反馈机制 ------->强化学习
1.给定样本的时候 抽取一些特征 (比如1.样本的语义特征
包括2.教师模型的输出 logits
3.根据GT的算出的教师模型的loss)
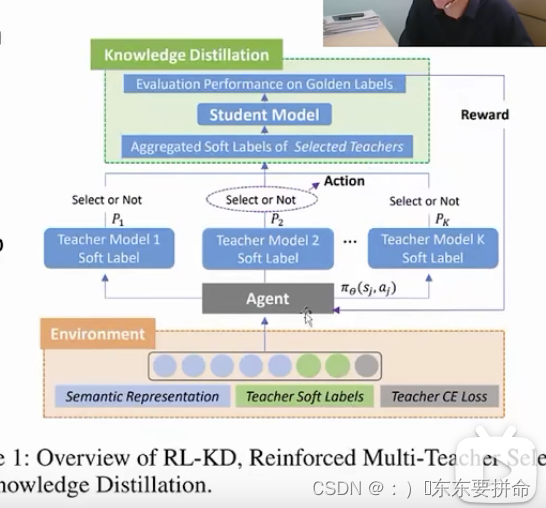
sj就是抽取特征的一个特征向量
aj 代表的是Action也就是Agent能采取的动作
对于每个老师来说呢 都有两个 action 当 action为1 的时候表示我们采纳这个教师的模型输出进入到知识蒸馏里面去(这力激发了我的一个ideal:在这里保存一下,action)(你们要是缺点子自取 我现在速度没有那么快,而且肯定可行)他这个太绝对了,怎么教的好 就学,教的不好就不学喽挺任性啊,其实每个老师都有自己的闪光点的,所以这里可是靠讲故事 再来一个hyper parameter)
当积累到一个batch 以后 我们用这个batch来训练学生模型它的学习情况
当答对的题目越高,这个Reward 就越高
然后就把这个reward作为一个反馈来训练我们的Agent
、换句话说 就是采用梯度的方法 来逐渐优化我们这样一个策略函数
最关键的部分就是策略函数的学习
学习好我们这个策略函数有几个关键点
1.我们应该抽取什么样的特征
2.如何来设定学生的Reward
3.策略函数的定义形式

选了七个公开数据集 以及不同的三个任务
情感分类 paraphrase相似度匹配 自然语言推理
设置了六个基线的方法

今晚就先到这吧 我要开始写paper了
















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











