






NLP中的知识蒸馏
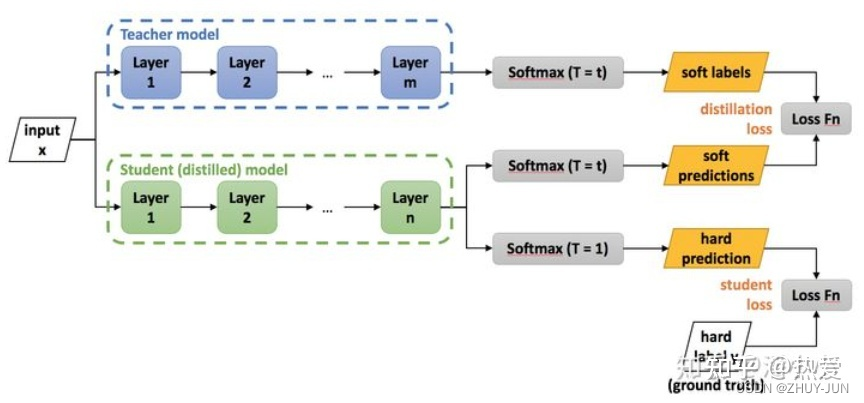
一、什么是知识蒸馏
知识蒸馏一个重要目的是让学生模型学习到老师模型的泛化能力,让轻量级的学生模型也可以具备重量级老师模型的几乎同样的能力。
一个很高效的蒸馏方法就是使用老师网络softmax层输出的类别概率来作为软标签,和学生网络的softmax输出做交叉熵。
传统训练方法是硬标签,正类是1,其他所有负类都是0。但知识蒸馏的训练过程过程是用老师模型的类别概率作为软标签。
二、为什么需要知识蒸馏
大模型虽然效果很好,但模型较重推理速度太慢无法瞒足工业要求,而小模型轻,推理速度快,但是直接使用数据训练效果较差,知识蒸馏就是想让小模型在拥有较快的推理速度下,也具备大模型的泛化能力。
三、知识蒸馏中的SoftMax
原始的softmax:
q i = e x p ( z i ) ∑ j e x p ( z j ) q_i = {\frac{exp(z_i)}{{\sum_{j}{exp(z_j)}}}} qi=∑jexp(zj)exp(zi)
上述有说到,知识蒸馏是student模型学习tearch模型的软标签,但是如果
- 教师模型softmax输出的软标签概率分布熵很小,就是负标签的概率值接近于0,学生模型负标签知识学习很弱,那么该值对损失函数的影响会很小。
- 如果两个logits差异较大,而使用softmax之后会导致两个输出的差异降低,从而减少了模型的知识,而使用softmax-T后,会更好的保留两者之间的差异。
所以对softmax加了温度:
q i = e x p ( z i / T ) ∑ j e x p ( z j / T ) q_i = {\frac{exp(z_i/T)}{{\sum_{j}{exp(z_j/T)}}}} qi=∑jexp(zj/T)exp(zi/T)
根据公式可以看出,让T越大时,softmax输出值越平滑,输出值得熵越大,会放大负标签携带的信息,模型会相对校对的关注负标签,能够充分的学习。 一般来讲T会大于1;
四、如何选择温度:
说白了温度的高低改变的是学生网络对负标签的关注程度
- 温度较低时,负类别携带的信息会被相对减少,对负类别的关注较少,负类别的概率越低,关注越少。
- 温度较高时,负类别的概率值会相对增大,负类别携带的信息会被相对地放大,学生网络会更多关注到负标签。
实际上,负类别中包含一定的信息,尤其是那些概率值较高的负类别。 但由于老师网络的负类别可能会有噪声,并且负类别的概率值越低,其信息就越不可靠。因此温度的选取比较看经验,本质上就是在下面两件事之中取舍
- 从负类别中获取信息 --> 温度要高一些
- 防止受负类别中噪声的影响 --> 温度要低一些
总的来说,温度的选择和学生网络的大小有关,学生网络参数量比较小的时候,相对比较低的温度就可以了,因为参数量小的模型不能捕获所有知识,所以可以适当忽略掉一些负标签的信息。
五、如何蒸馏、LOSS是什么样的
- 如何蒸馏:
第一步是训练老师网络;第二步是蒸馏老师网络的知识到学生网络。 - 损失函数:
高温蒸馏过程的目标函数由distill loss(对应软标签)和student loss(对应硬标签)加权得到。
L = α L s o f t + β L h a r d L = \alpha L_{soft} + \beta L_{hard} L=αLsoft+βLhard
distill loss(对应软标签) :
是老师模型softmax经过高温后输出的概率分布和学生网络在同等温度下的概率分布做交叉熵, 软标签 loss:
L s o f t = − ∑ j = 1 n p j T l o g ( q j T ) ,其中 p i T = e x p ( v i / T ) ∑ k = 1 n e x p ( v k / T ) , q i T = e x p ( v i / T ) ∑ k = 1 n e x p ( v k / T ) L_{soft} = -{\sum_{j=1}^n {p_j^T log(q_j^T)}},其中 p_i^T = {\frac{exp(v_i/T)}{{\sum_{k=1}^n exp(v_k/T)}}}, q_i^T = {\frac{exp(v_i/T)}{\sum_{k=1}^n {exp(v_k/T)}}} Lsoft=−j=1∑npjTlog(qjT),其中piT=∑k=1nexp(vk/T)exp(vi/T),qiT=∑k=1nexp(vk/T)exp(vi/T)
student loss(对应硬标签) :
是学生网络在温度为1下的概率分布和真实标签做交叉熵,硬标签 loss:
L h a r d = − ∑ j n c j 1 l o g ( q j 1 ) ,其中 q j 1 = e x p ( v j ) ∑ k n e x p ( v k ) L_{hard} = -{\sum_j^n {c_j^1 log(q_j^1)}}, 其中 q_j^1 = {\frac{exp(v_j)}{\sum_{k}^n {exp(v_k)}}} Lhard=−j∑ncj1log(qj1),其中qj1=∑knexp(vk)exp(vj)
六、项目开展和算法调优过程
损失函数的比较和选择
- 交叉熵损失(CrossEntropyLoss):基于softmax-T计算损失。其中softmax-T上述有过介绍,不在过多赘述。
- 均方差损失(MESLoss):基于logits直接计算。
在我的实验中,两者之间的训练结果并无太大差异,反而MSELoss计算方法获得的结果更优。 (其实是近MSELoss,但大多数实验者直接用MSELoss替代)基本类似。
使用MSELoss的另一个好处是,避免了超参数T的使用。 超参数T的使用还会影响soft-loss和hard-loss的比重,虽然理论上需要给soft-loss乘以 T 2 T^2 T2 ,让彼此的权重在同一个数量级上。
对于知识蒸馏建议使用MSELoss,而非使用原本的softmax-T-loss(Hinton,2014),能达到更好的效果,理论和实验都有证明。 - 项目中的具体做法:
- 这里我使用了一种soft-label的方法。是将teacher模型的logits表示经过softmax后,与one-hot表征的实际label进行相加, 注意这里引入相加的权重alpha,实验做好的值为0.5,alpha越大越依赖教师模型的logits。然后得到一个新的label表示。如teacher-logit-softmax = [0.2,0.7,0.1],实际标签one-hot = [0,1,0],alpha = 0.5,那么最后的label = [0.1,0.85,0.05],然后用这个label和student计算获得的logits进行MSELoss计算,求导。这种方法获得的结果和直接用MSELoss计算后,然后使用alpha权重相加结果类似,但好处是少了一次MSELoss的计算过程,在训练时,训练速度更快。
Teacher模型
因为是中文NLP任务,对于teacher模型选择的标准是,尽量好,尽量优秀,甚至可以使用集成学习的方法获得最优结果。
项目中使用了中文的Roberta-base模型作为teacher模型(已经对下游NER实体进行了Finetune,精度F1 = 94.67%),具体参数:Epoch=3,max_sequence_length = 256,batch_size = 32,model_size = 42.2M。
Student模型
前后使用多种Student模型,选取的条件是速度满足当前模型预测的速度要求,(不做蒸馏前,纯训练)精度越高越好。
将BERT模型蒸馏至TextCNN 和BiLSTM等小模型上,精度下降3%,速度提升400倍。注意文章使用了word2vec词向量,并非完全从头训练,具体细节可看论文和代码。
蒸馏学习的Student模型分别使用了ALBert-Base,ALBert-Tiny和ELECTRA-Small这三种模型,模型使用的alpha = 0.5,使用的是MSELoss的方法,具体结果:
| Model | Base-f1 | Distill-f1 | M-Size | I-Time |
|---|---|---|---|---|
| Roberta-Base | 0.94675 | — | 412M | 95.35s |
| AlBert-base | 0.810 | 0.909 | 42.2M | 27.3 |
| ALBert-Tiny | 0.612 | 0.824 | 16.3M | 9.3s |
| ELECTRA-small | 0.9124 | 0.9267 | 49.4M | 24.8s |
蒸馏中的数据增强
使用训练好的teacher模型对数据打标,形成伪标签,再训练student模型,即使部分case teacher没有标对,也没有很大的关系,目的就是让student更像teacher,本来badcase就很小,对训练影响度有限,但是伪标签数据不易过度,以免真正影响效果。
Batch-size和max-sequence-length的使用:
- 训练数据的平均长度=37 chars,一般使用2倍平均长度即可获取较好结果,这里使用的是128长度,能够涵盖大部分训练数据而不会导致数据流失。
- 对于标签不均衡的训练数据来说,扩大batch-size能比较好的覆盖更全的label,让模型能尽快找到更合适的训练方向。
多步蒸馏到超小模型
如上述实验中的奖RoBerta-Base模型内容蒸馏到ALBert-Tiny,模型的size差异大约在30倍,如果直接蒸馏,效果会不好。精度大约只能达到82.4%。这里可以借鉴miniLM(Ref-9)的一种操作Trick,间接蒸馏。具体做法是先将大模型(如:RoBerta-Base,94.7%)里的知识蒸馏到一个中(过渡)模型(如:ELECTRA-base,92.1%),然后再用中模型作为teacher,将知识蒸馏到真正的小模型(如此处的ALBert-Tiny),模型精度最终可以达到88.3%,精度大约有6个点的提升。
七、知识蒸馏需要注意的点
-
温度T,高温T。通常模型训练的时候使用高温T,而在模型测试和预测阶段的时候,是不使用teacher模型的,仅使用student模型进行测试和预测,也就是T在预测阶段不使用。
-
MSELoss计算L-soft。不使用上述复杂的L-soft,而使用简单的均方差损失函数——MSELoss。
-
Hard-Loss加入模型。即便使用了Soflt-Loss,还是需要引入Hard-Loss以及超参数 目的是teacher模型也可能存在无法完全学对的可能,所以在数据质量有保证的情况下,引入学生模型的hard-loss能更好的学会teacher无法学会的知识。实际使用过程中也发现,引入hard-loss很有效果。
-
使用更多损失函数。,Hinton的蒸馏学习使用的是Cross-Entorpy作为损失函数,其实损失函数不止于交叉熵损失函数,包括MSELoss,NLLLoss,HingeLoss等。实验中,我使用了MSELoss和CELoss做比较,发现二者对于Student模型的效果类似,所以对于不同下游任务,可以使用更贴合的Loss函数,不必局限于CELoss。但是对于蒸馏学习的理解一定要到位,才能更合理的利用Loss。
-
集成学习加入到蒸馏学习中。通常我们不会仅仅使用一个老师,而是使用多个teacher,然后将多个teacher的知识权重相加引入到student模型中。这是将集成学习和蒸馏学习相融合,能让学生学到更多信息,但是也同时增加了模型训练的难度(增多了超参数的数量以及集成学习方法的比较),对于初学者不建议使用。
八、知识蒸馏的几个思考
student loss的必要性
因为老师网络也有一定的错误率,使用ground truth可以有效降低错误被传播给学生网络的可能。
举例,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
为什么student loss(硬标签)所占比重比较小的时候,能产生最好的结果
这是一个经验的结论。一个可能的原因是,由于soft target产生的gradient与hard target产生的gradient之间有与 T 相关的比值。
在同时使用soft target和hard target的时候,需要在soft target之前乘上
T
2
T^2
T2 这个系数,这样才能保证soft target和hard target贡献的梯度量基本一致。
能不能直接match logits(不经过softmax)
直接match logits指的是,直接使用softmax层的输入logits(而不是输出)作为soft targets,需要最小化的目标函数是Net-T和Net-S的logits之间的平方差。直接上结论: 直接match logits的做法是 T→∞ 的情况下的特殊情形。














 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









