






目录
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理(计即数据清洗)
清洗数据中的空值
使用isnull()判断数据中的值是否为空值
import pandas as pd
missing_values = ["n/a", "na", "--","-"] #将"n/a", "na", "--","-"定义为空值
df = pd.read_ecxel('被读取的数据.xlsx',na_values = missing_values) #在读取文件时将自己定义的空值传进来,不传则只有默认的空值
df_new = df['某一列数据的列名'].isnull() #判断某一列中是否有空值使用dropna()方法删除数据中包含空字段的行
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
移除指定的某列中字段为空的行
import pandas as pd
df = pd.read_ecxel('被读取的数据.xlsx')
df.dropna(subset=['某一列的列名'], inplace = True) #参数 inplace = True 表示修改DataFrame的源数据使用fillna()方法替换缺失值
df.fillna(123, inplace = True) #用123替换数据中为空的值
#参数 inplace = True 表示修改DataFrame的源数据
df['列名'].fillna(123, inplace = True) #用123替换某一列中数据为空的值使用replace()方法将指定值替换为新值
df.replace(old_value, new_value)
df['列名'].replace(old_value, new_value)计算均值、中位数值、众数
均值:所有值加起来的平均值df.mean()
x = df["列名"].mean() # 计算某一列的均值
df["列名"].fillna(x, inplace = True) # 将计算的均值x替换掉df数据中某列的空值,True代表修改源数据中位数值(排序后排在中间的数)
x = df["列名"].median() # 计算某一列的中位数值
df["列名"].fillna(x, inplace = True) # 将计算的中位数值x替换掉df数据中某列的空值,True代表修改源数据众数(出现频率最高的数)
x = df["列名"].mode() # 计算某一列的众数
df["列名"].fillna(x, inplace = True) # 将计算的众数x替换掉df数据中某列的空值,True代表修改源数据计算行的均值、最大值、最小值、70%中位数:
# 计算行的均值、最大值、最小值、70%中位数
features_mean = features.mean(axis=1)
features_max = features.max(axis=1)
features_min = features.min(axis=1)
features_median = features.quantile(0.7,axis=1)
# 将计算的各列合并为一个表格,并为各列加上索引
result2 = pd.DataFrame({'电压均值':features2_mean,'电压最大值':features2_max,'电压最小值':features2_min,'70%中位数':features2_median})
清洗错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 403, 125] # 403,125 年龄数据是错误的
}
df = pd.DataFrame(person)
print(df)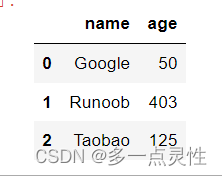
将 age 大于 120 的设置为 120:
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string) #显示全部数据,不省略显示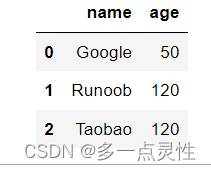
将 age 大于 125 的删除:
for x in df.index:
if df.loc[x, "age"] > 125:
df.drop(x, inplace = True)
print(df.to_string())















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









