







目录
1.新的架构以及架构特点:
1.GoogleNet提出了一个个高效的计算机视觉深度神经网络架构,代号Inception,这是一种新层次的组织方式,在更直接的意义上增加了网络的深度。
2.这个架构的主要特点是提高了网络内部 计算资源的利用率。
2.性能问题讨论
提高深度神经网络性能最直接的方式是增加它们的尺寸。
包括:
1)增加深度
2)网络层次的数目
3)它的宽度:每一层的单元数目
这种方法的缺点:
1)更大的尺寸通常意味着更多的参数,这会使增大的网络更容易过拟合,尤其是在训练集的标注样本有限的情况下。
2)计算资源使用的显著增加,会浪费大 量的计算能力。
解决缺点的基本办法:
引入稀疏性并将全连接层替换为稀疏的全连接层,甚至是在卷积层内使用稀疏性。
稀疏的全连接层指的是:只对一个视觉区域内极小的一部分敏感,而对其他部分则可以视而不见的现象
这种解决办法产生的问题:
当碰到在非均匀的稀疏数据结构上进行数值计算时, 计算架构效率会非常低下。
非均匀的稀疏模型也要求更多的复杂工程和计算基础结构。
那么一个架构能否利用滤波器(filter)水平的稀疏性呢?
kernel内核的概念:
内核是一个2维矩阵,长 × 宽;通常用2D于卷积运算。
filter滤波器概念:
滤波器是一个三维的立方体,是用来提取图像的特定的特征单元,filter可以提取低维特征和高维特征。
两者关系:
kernel 是filter 的基本元素, 多个kernel 组成一个filter;
稀疏矩阵乘法的大量文献(例如[3])认为对于稀疏矩阵乘法,将稀疏矩阵聚类为相对密集的子矩阵会有更佳的性能。在不久的将来会利用类似的方法来进行非均匀深度学习架构的自动构建。
3.Inception架构的细节
两个想法:
1)考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。
Inception 模块:用不同的图像块采样方法训练
(a) Inception 模块
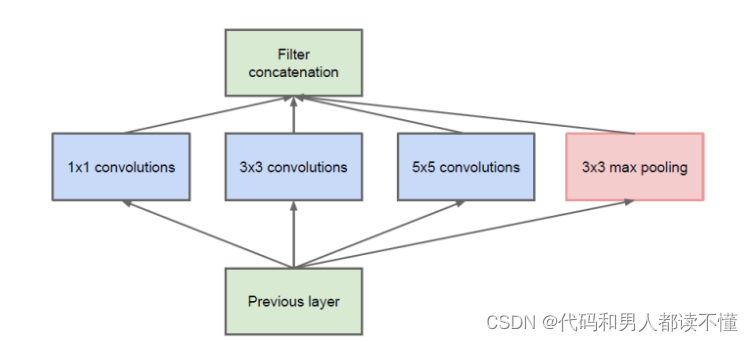
BUT:
即使只有部分5×5的卷积,随着池化单元添加到混合中,这个问题更加严重明显:
输出滤波器的数量等于前一阶段滤波器的数量。池化层输出和卷积层 输出的合并会导致这一阶段到下一阶段输出数量不可避免的增加。
最终导致在几个阶段内计算量爆炸。
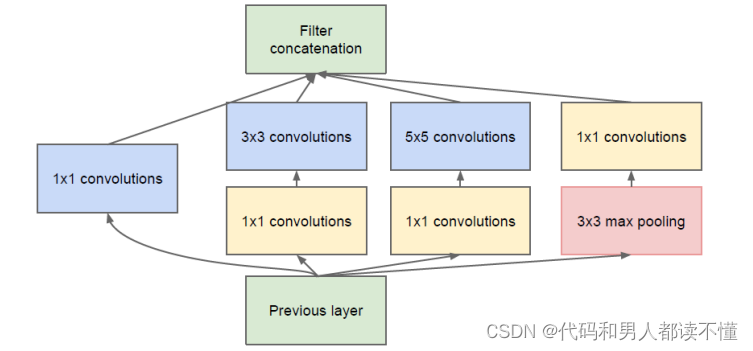
因此提出:
2)在计算要求会增加太多的地方,明智地减少维度。
例如如图所示:在3×3和 5×5 的卷积之前,用1×1 卷积来计算降维,除了用来降维之外,它们的第二个作用是使用线性修正单元。
(b) 降维的 Inception 模块
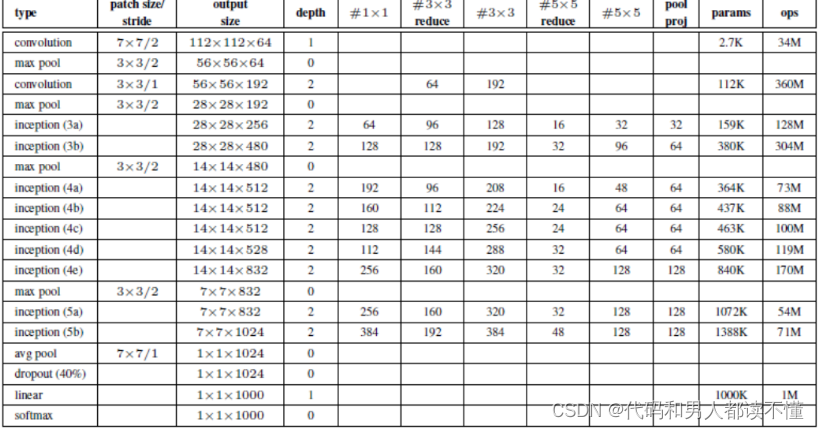
Inception 架构的 GoogLeNet
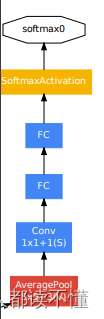
包括辅助分类器在内的附加网络的具体结构如下:
1)一个滤波器大小 5×5,步长为 3 的平均池化层,(4a)阶段结果输出为 4×4×512,(4d)阶段结果输出为 4×4×528。
2)具有 128 个滤波器的 1×1 卷积,用于降维和修正线性激活。
3)一个具有 1024 个单元和修正线性激活的全连接层。
4)丢弃率为 70%的 dropout 层。
5)使用带有 softmax 损失的线性层作为分类器(作为主分类器 预测同样的 1000 类,但在推断时移除)。
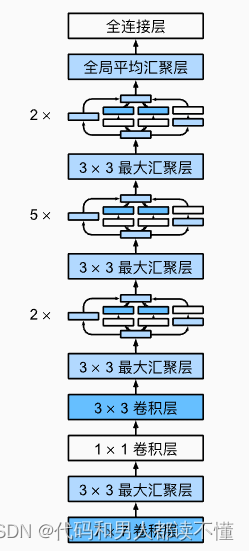
辅助分类器:
训练方法:
1)采用异步随机梯度下降,动量为 0.9,学习率每 8 个 epoch 下降 4%。
2)用 Polyak 平均来创建最后的模型。
3)图像采样的 patch 大小从图像的 8%到 100%, 选取的长宽比在 3/4 到 4/3 之间,光度扭曲也有利于减少过拟合,还使用随机插值方法结合其他超参数的改变来调整图像大小。
分类性能结果:
在测试时为了获得更高性能采用了一系列技巧,描述如下:
1)我们独立训练了 7 个版本的类似的 GoogLeNet 模型(包括一 个更广泛的版本),并用它们进行了整体预测。这些模型的训练具有相同的初始化(甚至具有相同的初始权重,由于监督)和学习率策略。 它们仅在采样方法和随机输入图像顺序方面不同。
2)将图像归一化为四个尺度
3)softmax 概率在多个裁剪图像上和所有单个分类器上进行平均, 然后获得最终预测。















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









