










哈喽,大家好,我不是小upper。
咱们今天聊聊,解码器的掩码注意力机制。
为了帮助大家更好地理解,我们来想象这样一个场景:你正在写一篇文章,写作时你只能回顾自己已经写好的内容,无法预知后面还未动笔的部分。这就意味着,你在构思下一个字或者词的时候,依据的仅仅是已经写下的文字信息,而不会受到尚未出现内容的干扰。
在 Transformer 解码器中,有一种机制叫 “掩码注意力”,也被称作 “因果注意力” ,它发挥的作用和上述场景很相似。当模型在生成第 i 步的内容时,它只能关注前面 1 到 i 这些已经生成的位置信息,而后面 i + 1 及更靠后的 “未来” 位置信息,都会被它 “屏蔽” 掉。
这种机制保证了模型生成过程具备自回归的特性,也就是像我们正常写作一样,按照先后顺序,一步一步地进行内容生成。
原理框架
Self-Attention 机制
在 Self-Attention 中,输入序列首先会通过特定的线性变换,分别映射成查询(Query)、键(Key)、值(Value)这三组向量。这就像是给输入序列的每个元素都配备了三把不同的 “钥匙”,用于后续不同的操作。
之后,每个位置的 Query 向量会和所有位置的 Key 向量进行点积运算。这种点积运算的结果,表示的是当前位置对其他各个位置内容的 “关注程度”,也就是 “我想看那个位置内容” 的 “意愿程度”。比如,在一个句子中,某个单词位置的 Query 向量和其他单词位置的 Key 向量点积后,得到的分数越高,就说明该单词对其他单词的关注程度越高。
因果掩码(Causal Mask)
为了实现自回归的生成过程,需要引入因果掩码机制。因果掩码是构造一个特定的矩阵,这个矩阵会将未来位置的分数进行特殊处理。具体来说,会把矩阵中对应 “未来” 位置(即当前位置之后的位置)的元素设为一个极小的值(通常是负无穷)。然后,将这个掩码矩阵加到前面计算得到的点积评分上,这样一来,“未来” 位置的分数经过这种处理后,再经过 Softmax 函数计算,其权重就会变为 0。这就好比给模型戴上了一副 “眼罩”,让它在生成当前位置的内容时,看不到未来的信息,只能关注已经生成的部分。
加权求和
完成上述操作后,模型会用经过掩码处理后的注意力权重去对 Value 向量进行加权求和。简单来说,就是根据每个位置的 “关注程度”,对相应位置的 Value 向量进行加权,从而得到每个位置最终的输出表示。这个输出表示综合了当前位置对其他各个位置的关注信息,能够更全面地反映输入序列的特征。
多头 & 层叠
为了进一步提升模型的能力,会采用多头注意力机制。多头注意力会并行执行多组 Q/K/V 计算,每组计算都独立进行且自行带上因果掩码,然后再将这些结果拼接起来。这样可以让模型从不同的角度去学习输入序列的特征,增强模型的表达能力。
在实际应用中,还会将多个这样的解码器层进行堆叠。每一层都由多头注意力机制、前馈网络(Feed-Forward)和 LayerNorm(一种归一化操作)组成。前馈网络用于对注意力机制的输出进行进一步的特征变换,而 LayerNorm 则有助于稳定模型的训练过程,使模型更加容易收敛。通过这种多层堆叠的方式,模型能够不断地对输入序列进行更深入的特征提取和处理,从而提高模型的性能。
关键公式
假设输入序列长度为L,向量维度为d。在第l层,第h个头(head)中:
- 线性变换
其中,,
,
。这里的
表示上一层的输出,通过这些权重矩阵的线性变换,得到当前层第h个头的 Query、Key 和 Value 向量。
- 点积打分 + 掩码
这里的M就是因果掩码矩阵,通过将其加到点积评分上,实现对未来位置的掩码操作。
- Softmax 得到注意力权重 由于在因果掩码的作用下,当
时,未来位置的分数经过 Softmax 后权重即为 0。这确保了模型在生成过程中只能关注过去的信息,符合自回归的要求。
- 加权求和输出
通过将注意力权重与 Value 向量相乘并求和,得到当前层第h个头的输出。
- 多头 & 拼接
其中H是头的数量,
。通过将多个头的输出拼接起来,并经过一个权重矩阵的变换,得到当前层的最终输出。这样,多头注意力机制能够充分利用不同头学习到的多样化特征,提升模型的整体性能。
完整案例
在序列生成任务里,解码器(Decoder)在预测下一个 token 时,必须避免看到未来的信息,这就需要引入 “因果注意力”(Causal Attention),也叫 “掩码注意力”(Masked Attention)机制。它的作用至关重要,就像是给解码器戴上了 “时间限制器”,让它只能依据已经出现的信息进行预测。
下面,我们通过一个简单的序列预测任务来深入理解这一机制:给定长度为 seq_len 的随机整数序列,预测下一个值。
首先,我们要准备数据。这里使用 PyTorch 框架,通过继承Dataset类来创建数据集。代码如下:
import torch
from torch.utils.data import Dataset, DataLoader
class SeqDataset(Dataset):
def __init__(self, seq_len, size):
# seq_len: 输入序列长度,size: 样本数量
self.data = torch.randint(0, 10, (size, seq_len + 1))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
seq = self.data[idx, : -1]
target = self.data[idx, 1:]
return seq, target
# 创建数据集和DataLoader
train_dataset = SeqDataset(seq_len=10, size=1000)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)在这段代码中,SeqDataset类的__init__方法使用torch.randint生成随机整数序列,每个序列长度为seq_len + 1。__getitem__方法负责从数据集中获取样本,将序列的前seq_len个元素作为输入seq,从第二个元素到最后一个元素作为目标target。最后,使用DataLoader对数据集进行封装,设置batch_size为 32,并打乱数据顺序。
接下来,定义模型。我们先自定义一个因果多头注意力模块,代码如下:
import torch.nn as nn
import torch.nn.functional as F
def causal_mask(seq_len):
# 返回一个 [seq_len, seq_len] 的上三角掩码,未来位置为 -inf
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask
class MaskedMultiHeadAttention(nn.Module):
def __init__(self, emb_size, num_heads):
super().__init__()
assert emb_size % num_heads == 0
self.num_heads = num_heads
self.head_dim = emb_size // num_heads
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.fc_out = nn.Linear(emb_size, emb_size)
def forward(self, x): # x: [B, T, emb]
B, T, E = x.shape
qkv = self.qkv(x) # [B, T, 3*E]
q, k, v = qkv.chunk(3, dim=-1)
# 分头
q = q.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力得分
scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5)
# 添加掩码
mask = causal_mask(T).to(scores.device)
scores = scores.masked_fill(mask.unsqueeze(0).unsqueeze(0), float('-inf'))
attn = torch.softmax(scores, dim=-1)
out = attn @ v # [B, heads, T, head_dim]
out = out.transpose(1, 2).contiguous().view(B, T, E)
return self.fc_out(out), attn在这个模块中,causal_mask函数用于生成因果掩码。它通过torch.triu生成一个上三角矩阵,将其对角线及以上的元素(代表未来位置)设置为True,再转换为布尔类型。MaskedMultiHeadAttention类继承自nn.Module,在其forward方法中,首先对输入x进行线性变换得到q、k、v向量,然后将其按头数进行拆分。计算注意力得分时,先进行点积运算并缩放,再加上因果掩码,最后通过softmax得到注意力权重。将注意力权重与v向量相乘并调整维度后,经过全连接层fc_out得到输出。
然后,定义解码器模型:
class SimpleDecoder(nn.Module):
def __init__(self, vocab_size, emb_size=64, num_heads=8):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.attn = MaskedMultiHeadAttention(emb_size, num_heads)
self.fc = nn.Linear(emb_size, vocab_size)
def forward(self, x):
x = self.embedding(x) # [B, T, emb]
attn_out, attn_weights = self.attn(x)
logits = self.fc(attn_out)
return logits, attn_weightsSimpleDecoder类同样继承自nn.Module,在__init__方法中定义了嵌入层embedding、因果多头注意力模块attn和全连接层fc。forward方法先对输入进行嵌入操作,再通过因果多头注意力模块得到输出,最后经过全连接层得到预测的 logits。
接下来是训练流程:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleDecoder(vocab_size=10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
epochs = 20
loss_list = []
for epoch in range(1, epochs + 1):
epoch_loss = 0
for seq, target in train_loader:
seq, target = seq.to(device), target.to(device)
optimizer.zero_grad()
logits, _ = model(seq)
loss = criterion(logits.view(-1, 10), target.view(-1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_loader)
loss_list.append(avg_loss)
print(f"Epoch {epoch}, Loss: {avg_loss:.4f}")这段代码首先确定使用的设备(优先使用 GPU),然后初始化模型、优化器和损失函数。在训练循环中,每次迭代时将数据移动到指定设备上,清空梯度,进行前向传播计算损失,反向传播更新参数,并记录每个 epoch 的平均损失。
最后,进行可视化结果与分析。这里通过绘制损失曲线来观察模型的训练情况:
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
plt.plot(loss_list, marker='o')
plt.title("Training Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.show()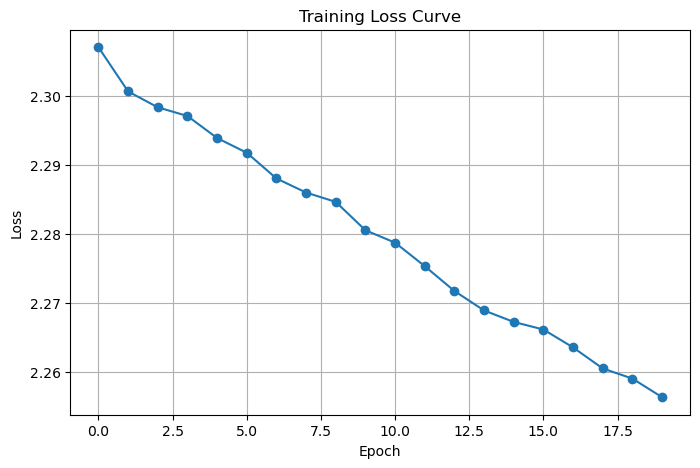
从图表中可以直观地看到随着训练轮数(Epoch)的增加,损失值的变化趋势。如果损失值逐渐下降,说明模型在不断学习和优化;若损失值出现波动或上升,则可能需要调整模型参数或训练策略。
注意力权重热图(Attention Weights Heatmap)
# 获取一个 batch 的注意力权重,然后绘制 Head 0 的热力图
model.eval()
with torch.no_grad():
seq_batch, _ = next(iter(train_loader))
seq_batch = seq_batch.to(device)
_, attn_weights_batch = model(seq_batch) # attn_weights_batch: [B, heads, T, T]
# 取第一个样本,头 0 的注意力权重
attn_weights = attn_weights_batch.detach().cpu()[0] # [heads, T, T]
head0 = attn_weights[0]
plt.figure(figsize=(6, 6))
plt.imshow(head0, cmap='rainbow', interpolation='nearest')
plt.title("Attention Weights Heatmap")
plt.xlabel("Key Position")
plt.ylabel("Query Position")
plt.colorbar()
plt.show()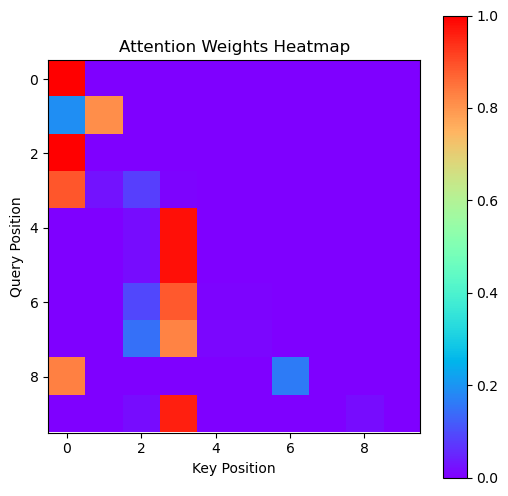
上图为Attention Weights Heatmap (Head 0),横坐标是 “键” 的位置(Key Position ) ,纵坐标是 “查询” 的位置(Query Position )。颜色越接近红色,代表注意力权重越高,也就是对应位置之间关联程度越强;颜色越接近紫色,代表注意力权重越低,关联程度越弱。比如在第 0 行第 0 列、第 4 行第 4 列等位置颜色红,说明这些对应位置的关联紧密,而大片偏紫色区域表示对应位置间关联较弱。
生成PK真实(Generated vs Ground Truth)
# 用模型生成序列并与真实 target 对比
model.eval()
with torch.no_grad():
seq, target = next(iter(train_loader))
seq = seq.to(device)
logits, _ = model(seq)
pred = logits.argmax(dim=-1).cpu()
# 可视化第一个样本
plt.figure(figsize=(10, 4))
plt.plot(target[0].numpy(), marker='o', label='Ground Truth')
plt.plot(pred[0].numpy(), marker='x', label='Predicted')
plt.title("Generated Sequence vs Ground Truth")
plt.xlabel("Time Step")
plt.ylabel("Token ID")
plt.legend()
plt.show()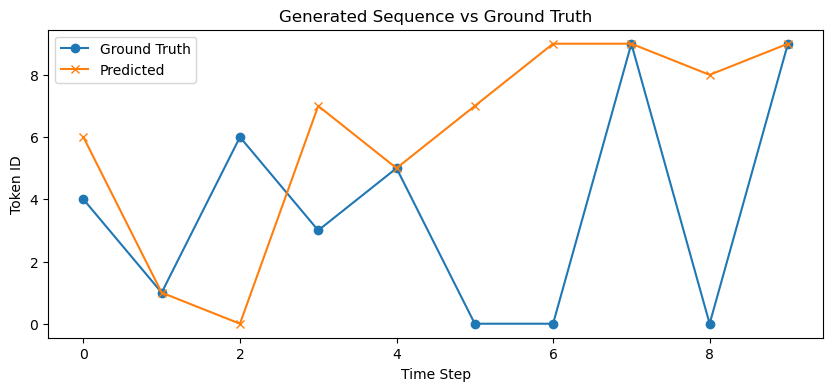
这张图展示了生成序列和真实序列的对比。横坐标是时间步(Time Step ),纵坐标是 Token ID 。蓝色圆点连线代表真实序列(Ground Truth ),橙色叉号连线代表预测序列(Predicted ) 。可以看到,在有些时间步上两者重合,说明预测准确;有些时间步上两者差异较大,说明预测存在偏差。
随时间变化的注意力(Attention over Time)
# 可视化 query 在不同时间步对过去位置的注意力分布
plt.figure(figsize=(8, 5))
for t in range(0, head0.size(0), 2): # 每隔 2 个时间步画一次
plt.plot(head0[t].numpy(), label=f"Query t={t}")
plt.title("Attention Pattern Over Time")
plt.xlabel("Key Position")
plt.ylabel("Attention Weight")
plt.legend()
plt.show()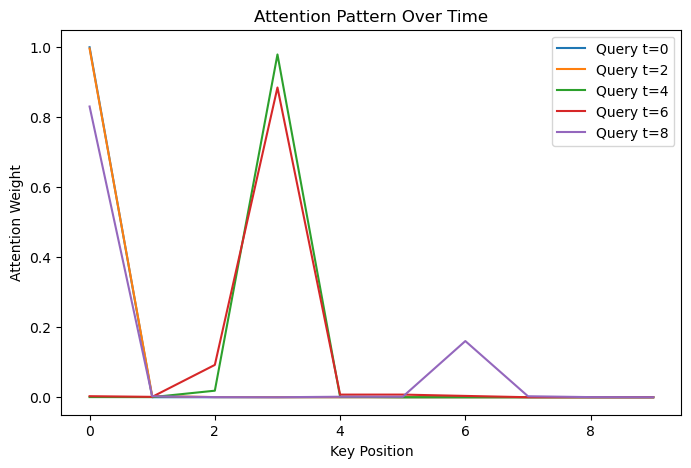 上图横坐标是 “键” 的位置(Key Position ),纵坐标是注意力权重(Attention Weight ) 。不同颜色的线代表不同时间步的 “查询” ,像蓝色是 Query t=0 ,橙色是 Query t=2 等。可以看到,不同时间步的 “查询” 对 “键” 位置的注意力权重不一样,比如 Query t=2 在 “键” 位置 0 处权重高,说明这个时间步的 “查询” 更关注 “键” 位置 0 ,能看出模型注意力的变化情况。
上图横坐标是 “键” 的位置(Key Position ),纵坐标是注意力权重(Attention Weight ) 。不同颜色的线代表不同时间步的 “查询” ,像蓝色是 Query t=0 ,橙色是 Query t=2 等。可以看到,不同时间步的 “查询” 对 “键” 位置的注意力权重不一样,比如 Query t=2 在 “键” 位置 0 处权重高,说明这个时间步的 “查询” 更关注 “键” 位置 0 ,能看出模型注意力的变化情况。
算法优化与调参流程
优化点
- 多层堆叠:在解码器中,通过将多层 MaskedMultiHeadAttention 与前馈层进行堆叠,大幅提升模型的容量。就好比给模型增加了更多的 “思考单元”,使其能够处理更复杂的任务,挖掘到更深入的特征。
- 位置编码:引入绝对或相对位置编码方式,为模型补充了对序列位置信息的感知能力。这能让模型清楚序列中元素的先后顺序,理解 “先来后到” 的关系,进而更好地处理序列数据。
- 正则化:在注意力权重计算过程或者前馈网络中加入 dropout 机制。它像是一个 “随机过滤器”,在训练时随机让部分神经元不工作,避免模型过度依赖某些特征,有效防止过拟合,增强模型的泛化能力。
- 学习率调度:采用诸如 CosineAnnealingLR(余弦退火学习率调整策略 )或者 Warmup(预热策略 )等方法。这些策略能够合理地调整学习率,让模型在训练过程中更高效地收敛,就像给模型找到了一条更顺畅的 “学习路径”。
调参流程建议
- 基线验证:首先在小规模数据集上进行训练,这一步是为了验证模型能否正常收敛。就像盖房子前先打个地基,确认基础是否稳固,只有模型能正常收敛,后续的调参才有意义。
- 批量大小:尝试使用 [16, 32, 64] 这些不同的批量大小,观察其对训练稳定性的影响。批量大小会影响模型训练时梯度的计算和更新,合适的批量大小能让训练过程更稳定、高效。
- 学习率:通过网格搜索的方式,在 [1e-4, 5e-4, 1e-3] 这个范围内寻找合适的学习率,同时测试线性 warmup 策略。学习率决定了模型参数更新的步长,合适的学习率能让模型更快、更准确地找到最优解。
- 头数与维度:在满足 emb_size % num_heads == 0 的前提下,尝试不同的组合。不同的头数和维度设置会影响模型对特征的提取和处理能力,找到合适的组合能提升模型性能。
- 正则化系数:对 dropout 比例在 [0.1, 0.2, 0.3] 范围内进行调整。调整 dropout 比例可以控制模型的正则化强度,防止模型过拟合,使模型在不同数据集上都能有较好的表现。
- 训练轮数:运用 early stopping(早停法 )策略,当模型在验证集上的性能不再提升时,及时停止训练,避免过度训练导致过拟合。
通过上述内容,我们全面展示了解码器因果注意力的原理、具体实现方式、训练过程以及相关分析,同时也介绍了常见的优化手段与调参流程。


















 6783
6783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









