






UCB算法
与前面相比,只是改变选择动作:
A
t
=
a
r
g
m
a
x
a
[
Q
t
(
a
)
+
c
l
n
t
N
t
(
a
)
]
A_t=argmax_{a}[Q_t(a)+c\sqrt{\frac{lnt}{N_t(a)}}]
At=argmaxa[Qt(a)+cNt(a)lnt]
这种 上限置信区间 (UCB)行动选择的想法是,平方根项是对一个值估计的不确定性或方差的度量。 因此,最大化的数量是动作a的可能真实值的一种上限,其中c确定置信水平。 每次选择a时,不确定性可能会降低:
N
t
(
a
)
Nt(a)
Nt(a)递增,并且,正如它在分母中出现的那样,不确定性项减少。 另一方面,每次选择除a之外的动作时,t增加但
N
t
(
a
)
Nt(a)
Nt(a)
不增加;因为t出现在分子中,不确定性估计值会增加。 使用自然对数意味着随着时间的推移,增加量会变小,但是是无限制; 最终将选择所有操作,但是将随着时间的推移,具有较低值估计值或已经频繁选择的操作的选择频率会降低.
代码如下:
'''an algorithmn about n-armed bandit
Using formula
Q_K_1=Q_k+step(R_k-Q_k)
'''
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n = 10
T = 100000
tspan = np.arange(T)
eps = 0
q = np.random.normal(0,1,n)
class ArmedBandit:
def __init__(self, n, q) -> None:
self.n = n
self.q = q
self.Actions = np.arange(n)
def Action(self, t, eps):
exploration_flag = True if np.random.uniform() <= eps else False
noise = np.random.normal(0,1,self.n)
repay = q + noise
if exploration_flag:
a = np.random.randint(self.n)
self.Q_list[a] = self.Q_list[a] + (repay[a] - self.Q_list[a]) / (self.Nt[a]+1)
self.Nt[a] += 1
else:
Q = self.Q_list + (repay - self.Q_list) / (self.Nt+1)
a = np.argmax(np.array(Q))
self.Q_list[a] = Q[a]
self.Nt[a] += 1
avg = (q[a] + self.Reward_avg[-1] * t) / (t + 1)
self.Reward_avg.append(avg)
return a
def UCBAction(self, t, c):
'''
Input: t
'''
noise = np.random.normal(0,1,self.n)
repay = q + noise
# Q = self.Q_list + (repay - self.Q_list) / (self.Nt+1)
zero_indices = np.where(self.Nt == 0)[0]
if len(zero_indices) > 0:
a = np.random.choice(zero_indices)
self.Q_list[a] = self.Q_list[a] + (repay[a] - self.Q_list[a]) / (self.Nt[a]+1)
self.Nt[a] += 1
else:
if np.random.uniform() < 0.1:
a = np.random.randint(self.n)
self.Q_list[a] = self.Q_list[a] + (repay[a] - self.Q_list[a]) / self.Nt[a]
self.Nt[a] += 1
else:
Q = self.Q_list + (repay - self.Q_list) / self.Nt
UCB = c * np.sqrt(np.log(t) / self.Nt)
a = np.argmax(Q + UCB)
self.Q_list[a] = Q[a]
self.Nt[a] += 1
avg = (q[a] + self.Reward_avg[-1] * t) / (t + 1)
self.Reward_avg.append(avg)
return a
def play(self, T, eps=0, c=0):
self.ActionRecord = []
self.Q_list = np.zeros(n)
self.Reward_avg = [0]
self.Nt = np.zeros((n,))
for t in range(T):
if eps:
a = self.Action(t, eps)
elif c:
a = self.UCBAction(t,c)
else:
a = self.Action(t, eps)
self.ActionRecord.append(a)
return self.ActionRecord, self.Reward_avg[:-1]
if __name__ == "__main__":
slot_machine = ArmedBandit(n, q)
actions, reward_avg= slot_machine.play(T, eps=0)
c = 2
actions1, reward_avg1 = slot_machine.play(T, c=c)
actions2, reward_avg2 = slot_machine.play(T, eps=0.1)
plt.figure()
plt.plot(tspan, reward_avg, label='eps=0')
plt.plot(tspan, reward_avg1, label=f'c={c}')
plt.plot(tspan, reward_avg2, label='eps=0.1')
plt.xlabel('Steps')
plt.ylabel("Average reward")
plt.title("n Armed Bandit")
plt.legend()
print(q)
print(slot_machine.Nt)
plt.show()
结果如下:
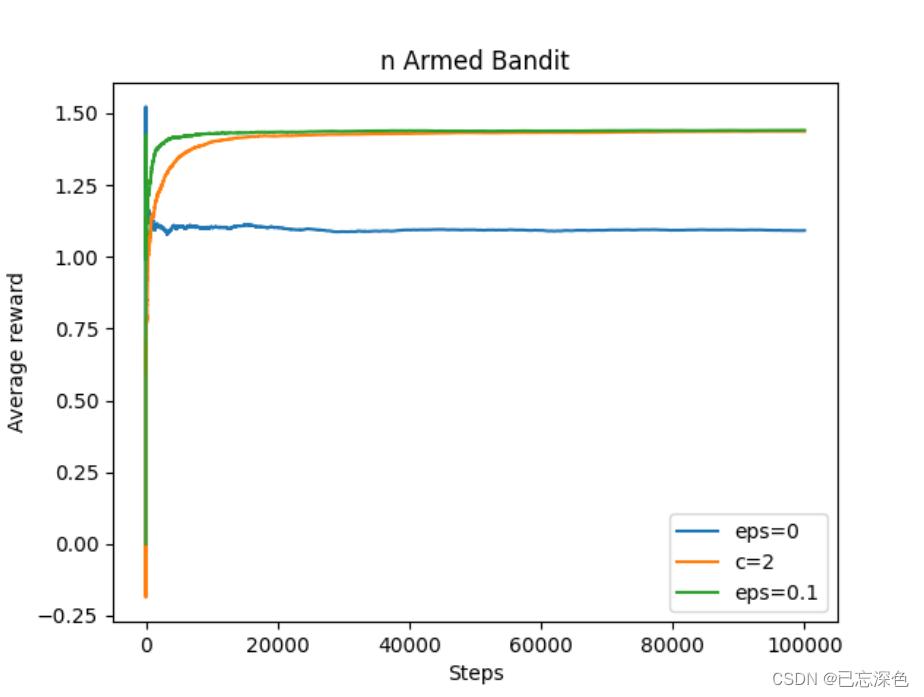
平常算法,如greedy或
ϵ
\epsilon
ϵ-greedy算法,在其上加个UCB操作可增加所有物品曝光率(即使它可能不是那么好),更加稳定.
多臂老虎机之UCB
RL
多臂老虎机UCB算法介绍















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











