







一、算法描述
广度优先搜索使用了和深度优先搜索一种不同的方法来搜索图。广度优先搜索系统地在图中搜索顶点,在搜索离源点:的距离为k+1条边的顶点之前,所有的离源点s距离为k条边的顶点都已经被访问。广度优先搜索不会访问围中那些源点不可达的顶点。
广度优先搜索不会进行任何回湖,我们可以通过查看顶点的颜色来查看进度,就像深度优先搜索那样。事实上,在广度优先搜索中,我们使用同样的颜色和定义。为了和深度优先搜索进行直接对比,我们使用一个类似的计数器,用来记录顶点第一次访问和最后一次访问的时刻。在相同的时间(例如,当计数器达到18时),广度优先搜索能够前进到下图的状态,即顶点12被标记为灰色。注意深度优先搜索已经处理顶点(1,6,8),这些顶点都是离源点s一条边的距离,以及顶点(2,3),它们离源点;两条边的距离,还有顶点(7,14,5),它们在队列中等待被处理。有些顶点离源点s三条边
距离,例如(11,10,12,4),已经被访问过了,虽然广度优先搜索还没有处理这些顶点。注意队列中的所有顶点都被染成灰色,表示它们现在的状态。
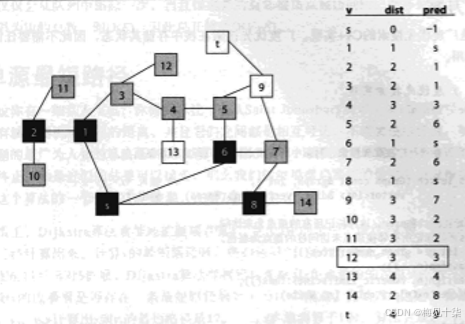
在初始化时,广度优先搜索会对所有顶点的信息进行更新,因此初始化的开销是O(V)。当一个顶点第一次被访问(染为灰色)时,将它放入队列,顶点不会重复添加。因为队列能够在常数时间添加或者删除元素,所以管理队列的开销是O(V)。最后,每一个顶点都仅仅会从队列中删除一次,当且仅当其所有邻接顶点被访问时。循环处理边的总次数上限为边的总数,即O(E)。因此总开销是O(V+E)。
广度优先搜索(BFS)的基本过程:
算法步骤:
-
初始化:
- 创建一个队列来存储待访问的节点。
- 创建一个布尔数组
visited,用于标记每个节点是否已访问。
-
遍历:
- 从起始节点开始,将其推入队列并标记为已访问。
- 当队列不为空时,执行以下操作:
- 从队列中弹出一个节点
u。 - 访问节点
u,进行必要的处理(如打印或存储)。 - 遍历
u的所有邻接节点v:- 如果节点
v未被访问,则将其推入队列并标记为已访问。
- 如果节点
- 从队列中弹出一个节点
二、复杂度分析
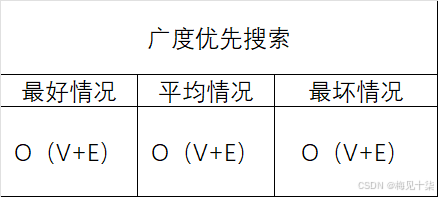
广度优先搜索(BFS)算法的时间复杂度主要取决于图的表示方法和图中顶点和边的数量。
假设:
- 图的顶点数为 (V)。
- 图的边数为 (E)。
1. 初始化部分:
在BFS算法中,首先会对所有顶点进行初始化:
dist.assign(n, numeric_limits<int>::max())初始化距离数组,时间复杂度为 (O(V))。pred.assign(n, -1)初始化前驱数组,时间复杂度为 (O(V))。- 颜色数组
color.assign(n, White)的初始化,时间复杂度也是 (O(V))。
因此,初始化部分的时间复杂度是 (O(V))。
2. 主循环部分:
BFS核心部分使用一个队列来进行层次遍历,在每次遍历时,它对每个顶点的所有邻接顶点进行检查。
对每个顶点 (u),将它的邻接顶点放入队列中的操作涉及两部分:
- 对于每个顶点,访问其所有的邻接边(从顶点 (u) 到顶点 (v))。
- 每条边最多被访问两次(一次是从起点顶点,另一次是从终点顶点),因为在无向图中边会双向检查。
在邻接表表示法下,遍历图中所有顶点和边的时间复杂度为: - 遍历每个顶点需要 (O(V))。
- 遍历每条边需要 (O(E)),因为每条边最多被访问两次(一次对于每个顶点)。
所以,主循环部分的时间复杂度是 (O(V + E))。
总时间复杂度:
BFS的时间复杂度综合来看是:
O(V + E)
结论:
- 顶点数 (V) 和 边数 (E) 是影响BFS时间复杂度的关键因素。
- 当图是稠密图时,边数 (E) 接近 (V^2)(即 (E = O(V^2)));当图是稀疏图时,边数 (E) 接近 (V)(即 (E = O(V)))。
三、适用情况
广度优先搜索(BFS)是一种经典的图遍历算法,具有广泛的应用。它在图论问题中尤其擅长处理最短路径、连通性等问题。以下是BFS算法的几种典型适用情况:
1. 无权图中的最短路径问题
BFS可以高效地解决无权图中的最短路径问题。在无权图中,从源点 (s) 到任意顶点的路径长度是通过边的数量来衡量的。BFS的层次遍历特性确保了,当一个顶点首次被访问时,访问路径一定是从源点到该顶点的最短路径。
应用场景:
- 地图上寻找两地之间的最少步数。
- 网络拓扑中寻找两节点之间的最小跳数。
- 棋盘游戏中,寻找从一状态到另一状态的最少移动次数。
2. 图的连通性问题
BFS可以用于检测图的连通性,例如:
- 判断一个无向图是否是连通图(从任意一个顶点可以到达所有其他顶点)。
- 寻找图的连通分量,即识别哪些顶点组成了相互连通的子图。
应用场景: - 在社交网络中寻找哪些人属于相同的社交圈。
- 判断计算机网络中的各个节点是否可以互相通信。
3. 拓扑层次遍历
BFS按层次(距离源点的层数)访问顶点,因此它特别适合用于场景中需要按层次或按步骤进行遍历的任务。通过BFS,可以按顺序处理图中不同层次的顶点。
应用场景:
- 寻找所有从源节点可到达的节点,并按到达的先后顺序列出(如项目管理中的任务调度)。
4. 双向BFS优化搜索
双向BFS是一种优化版本的BFS,它同时从源节点和目标节点分别向对方进行搜索。当两个搜索空间在中间相遇时,可以提前结束搜索,从而减少搜索空间,优化时间效率。
应用场景:
- 地图搜索中的路径寻找。
- 棋类游戏中的状态空间搜索优化。
5. 最小生成树的求解(无权图)
在无权图中,如果需要构建一棵最小生成树(MST),可以使用BFS。这特别适合于简单的树结构或分层拓扑结构的无权图。
应用场景:
- 网络中寻找覆盖所有节点的最少连接。
- 设计无向树形网络的最低成本连接方案。
6. 迷宫问题(网格图)
BFS可以用于解决迷宫求解问题,它可以高效地找到从起点到终点的最短路径,尤其适用于网格图或二维平面图。通过BFS遍历,可以从起点开始,逐步找到所有可行路径中的最短路径。
应用场景:
- 在一个二维网格中(如游戏地图、迷宫),找到从起点到终点的最短路径。
- 图像处理中的区域填充(如广泛应用的“种子填充算法”)。
7. 社交网络分析
BFS可以用于社交网络中进行层次分析。例如,从某个用户出发,找出距离该用户一度、两度甚至多度连接的所有用户(即朋友的朋友关系)。这种分析常用于推荐系统或病毒传播路径研究。
应用场景:
- 推荐系统中,基于朋友关系做社交推荐。
- 分析病毒或信息的传播路径。
8. 电路分析
在电路设计中,尤其是逻辑电路的模拟和验证,BFS可以用于分析电路网的连通性,计算信号传播的最短延迟路径等问题。
应用场景:
- 硬件电路中的信号传播时间计算。
- 电路网络中路径的连通性检查。
9. 棋类游戏AI
在一些棋类游戏(如国际象棋、跳棋等)的AI设计中,BFS可以用于对棋局状态空间的搜索,特别是当需要寻找某个状态是否能在有限步数内到达时。
应用场景:
- 跳棋游戏中找出最少步数到达目标位置的路径。
- 拼图类游戏的最优解路径寻找。
10. 网页抓取(爬虫)
在网络爬虫设计中,BFS可以用于按层次遍历网页链接。它确保了爬虫首先抓取与起始页面直接相连的页面,再逐步深入。
应用场景:
- 搜索引擎爬虫设计,广度优先抓取与某些网站相关的内容。
- 网站结构分析,寻找网站不同页面的层次结构。
总结:
BFS适用于处理图的遍历、连通性、最短路径以及层次结构分析等问题。特别是当图中的边没有权重,或所有边的权重相同时,BFS比其他算法(如深度优先搜索或Dijkstra算法)更加高效。
四、算法实现
以下为C++实现:
#include <iostream>
#include <vector>
#include <queue>
#include <limits>
using namespace std;
enum vertexColor { White, Gray, Black };
// Dummy Graph class definition for demonstration
class Graph {
public:
Graph(int n) : adjList(n) {}
void addEdge(int u, int v) {
adjList[u].push_back(make_pair(v, 1)); // Example with weight 1
adjList[v].push_back(make_pair(u, 1)); // Assuming undirected graph
}
int numVertices() const { return adjList.size(); }
typedef vector<pair<int, int>>::const_iterator Vertexlist;
Vertexlist begin(int u) const { return adjList[u].begin(); }
Vertexlist end(int u) const { return adjList[u].end(); }
private:
vector<vector<pair<int, int>>> adjList;
};
void bfs_search(Graph const& graph, int s, vector<int>& dist, vector<int>& pred) {
const int n = graph.numVertices();
pred.assign(n, -1);
dist.assign(n, numeric_limits<int>::max());
vector<vertexColor> color(n, White);
dist[s] = 0;
color[s] = Gray;
queue<int> q;
q.push(s);
while (!q.empty()) {
int u = q.front();
for (Graph::Vertexlist ci = graph.begin(u); ci != graph.end(u); ++ci) {
int v = ci->first;
if (color[v] == White) {
dist[v] = dist[u] + 1;
pred[v] = u;
color[v] = Gray;
q.push(v);
}
}
q.pop();
color[u] = Black;
}
}
int main() {
int vertices = 6;
Graph graph(vertices);
// Add edges to the graph
graph.addEdge(0, 1);
graph.addEdge(0, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 3);
graph.addEdge(3, 4);
graph.addEdge(4, 5);
vector<int> dist;
vector<int> pred;
int start_vertex = 0; // Starting BFS from vertex 0
bfs_search(graph, start_vertex, dist, pred);
// Output the distance and predecessor arrays
cout << "Vertex distances from vertex " << start_vertex << ":\n";
for (int i = 0; i < vertices; ++i) {
cout << "Vertex " << i << ": Distance = " << dist[i] << ", Predecessor = " << pred[i] << endl;
}
return 0;
}
五、算法优化
广度优先搜索(BFS)算法虽然简单且高效,但在处理大规模问题或复杂图结构时,仍有优化空间。常见的BFS优化方法包括改进空间复杂度、加速搜索过程等。以下是几种优化策略:
1. 双向广度优先搜索(Bidirectional BFS)
双向广度优先搜索是最经典的BFS优化之一。它同时从起点和目标点开始进行两端的BFS遍历,直到两端的搜索空间相交为止。由于每次遍历时的搜索空间减少了,从而显著减少了遍历的节点数,进而加速了搜索过程。
工作原理:
- 从起点进行一次BFS。
- 从目标点同时进行一次反向BFS。
- 当两者相遇时,停止搜索,路径的最短解即可通过相遇点获得。
时间复杂度:
在一个均匀的无向图中,普通BFS的时间复杂度是 (O(V + E)),而双向BFS的时间复杂度理论上可以减少到 (O(2 \times \sqrt{V + E})),因为每次搜索会遍历较小的搜索空间。
应用场景:
- 大规模地图中的路径搜索。
- 人际关系网络或社交网络中的最短路径查找。
2. 层次跳跃优化(Level-Synchronized BFS)
当在分布式系统中执行BFS时,可以使用“层次跳跃”的优化技术,即按层次来同步遍历的进度。这种方法能够在每一层完成后,快速跳转到下一层,避免重复无效的边遍历。
应用场景:
- 大规模分布式系统中的BFS,如大规模社交网络分析、搜索引擎的网页抓取等。
3. 邻接矩阵优化(Sparse Graph BFS)
当处理稀疏图时,传统的邻接矩阵表示会浪费大量空间。因此,在稀疏图中,可以通过使用邻接表替代邻接矩阵,减少存储空间的浪费。此外,邻接表使得遍历边时仅需访问实际存在的边,减少了不必要的时间开销。
优化效果:
- 降低了内存消耗。
- 在稀疏图中提高了访问边的效率,节省了时间。
4. 按块优化(Blocking BFS)
在BFS实现过程中,可以通过将图的节点和边划分为若干块,并在访问时尽量访问同一块内的节点,减少跨块访问带来的缓存失效问题。特别是在处理大型图时,这种块优化能够提高缓存命中率,显著提升性能。
应用场景:
- 大型图上的BFS处理,例如图数据库、社交网络分析。
5. 基于Heuristic的广度优先搜索(Heuristic-guided BFS)
在特定问题中,可以结合启发式算法来引导BFS的搜索方向。例如,在搜索迷宫或地图时,结合A*算法(BFS + 启发式估计函数),可以根据当前点到目标点的估计距离来优先搜索更有希望的路径,减少无效的遍历。
应用场景:
- 游戏AI中迷宫求解。
- 地图搜索问题中的路径优化。
6. 压缩状态空间
在状态空间非常大的问题中(如棋盘问题),存储所有状态可能需要非常大的空间。通过压缩状态表示或者只存储必要的状态,可以降低空间复杂度。常见的压缩技术包括:
- 位图(Bit Masking):用较少的位数来存储图中节点或状态信息,从而节省空间。
- 哈希表:将访问过的节点或状态用哈希表存储,以便快速判断节点是否被访问过。
应用场景:
- 棋盘类游戏(如八数码问题、跳棋问题)中的状态空间搜索。
7. 避免冗余状态检查
在某些应用中,特别是状态空间问题(如图像处理或棋类游戏),BFS可能会重复检查相同的状态。为了避免这种冗余,可以在BFS中引入额外的数据结构(如哈希集合或布尔数组)来记录已经访问过的状态,从而避免重复访问。
应用场景:
- 八数码问题、拼图问题等需要搜索大规模状态空间的场景。
8. 动态边权优化(Dynamic Edge Weight Optimization)
在某些图结构中,边可能有不同的权重。虽然标准BFS只能处理无权图,但在某些情况下,如果边的权重是可控或有限的,BFS可以结合边权处理。例如,将权重为1的边仍然视作普通边,但如果边权较大,可能需要调整队列中顶点的优先级。
应用场景:
- 动态网络流中的路径搜索。
- 具有边权限制的路径查找。
9. 并行化BFS
对于大规模图或高并发环境,可以将BFS并行化,从而提高遍历效率。具体策略包括:
- 多线程并行化:使用多线程并行遍历图的不同层次,每个线程负责遍历一部分节点。
- 分布式并行化:在分布式计算环境中,将图的不同部分分配给不同的计算节点并行执行BFS。
并行化优化时需要注意负载均衡和同步开销。
应用场景:
- 大规模图数据处理(如社交网络、互联网结构分析)。
- 并行计算环境中的图遍历。
10. 边的稀疏性优化
在处理稀疏图时,如果知道图的稀疏特性,可以针对稀疏边进行优化处理。例如,在图的存储上,使用稀疏矩阵或压缩的邻接表来减少不必要的内存开销。在遍历时,只遍历实际存在的边,避免检查不存在的边。
应用场景:
- 大型社交网络中的图遍历。
- 科学计算中的稀疏图分析。
总结:
BFS的优化策略主要针对空间复杂度和时间复杂度的改进。具体优化方法的选择取决于图的结构和问题的特性。对于大规模问题,双向BFS、启发式BFS、并行化BFS等方法是常见的选择;而在存储效率和搜索效率方面,压缩状态空间和稀疏图优化等方法能够有效降低复杂度。
六、引用及参考文献
1.《算法设计手册》



















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











