







通过本篇我们将学习第一个机器学习模型——线性回归模型,可以大致了解到监督学习的整个过程是什么样的,也是应用非常广的一种模型。
引入
本篇引用沿用监督学习(Supervised Learning)中的例子——房屋价格,即探究房屋面积和房屋价格之间的关系。
x轴为房屋面积大小,y轴为价格,红色×是已知的房屋价格。
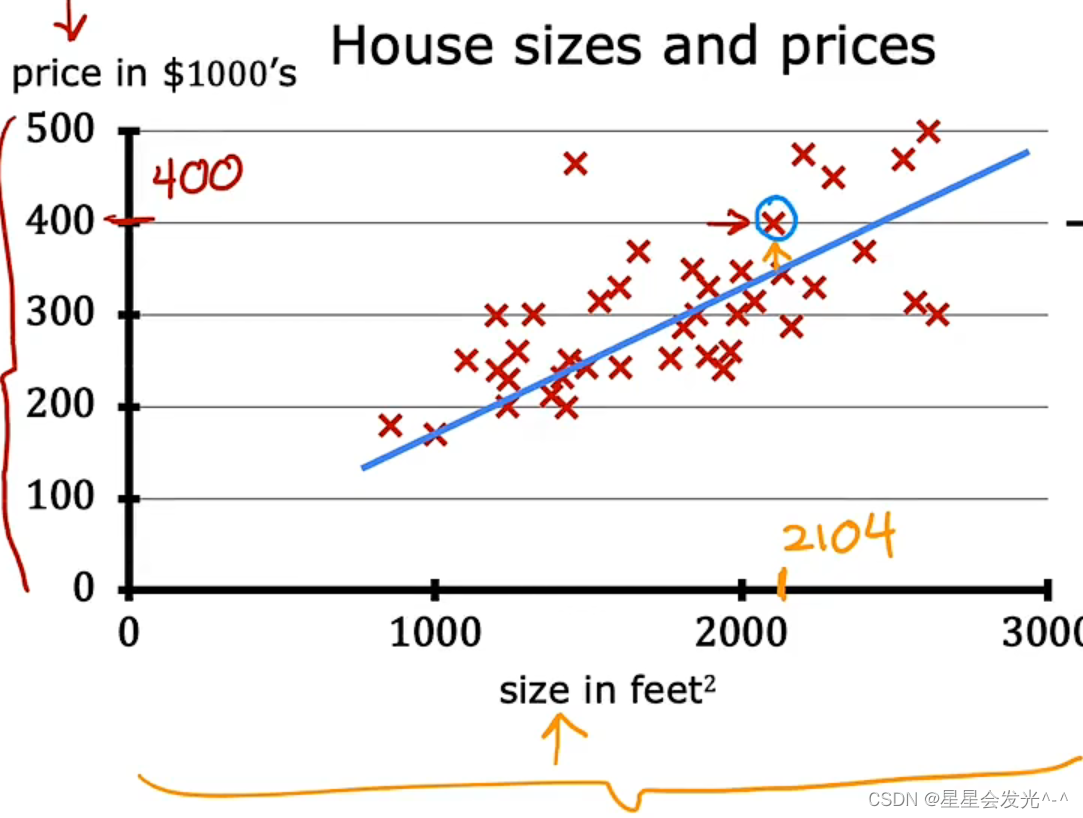
 如果现在有一个人想知道他的房子值多少钱,那么这些数据就可以在一定程度上帮助我们预估价格。要预估价格的第一步就是测量房屋面积,假设测得房屋面积为1250,那么我们就可以建立一个线性(linear)的来自该数据集的回归(Regression)模型,这个模型会将数据拟合成一条直线,直线如下图所示,得到了拟合后的直线,我们就可以找出x=1250时,y对应的值,所以我们预估的房价是在220k左右。
如果现在有一个人想知道他的房子值多少钱,那么这些数据就可以在一定程度上帮助我们预估价格。要预估价格的第一步就是测量房屋面积,假设测得房屋面积为1250,那么我们就可以建立一个线性(linear)的来自该数据集的回归(Regression)模型,这个模型会将数据拟合成一条直线,直线如下图所示,得到了拟合后的直线,我们就可以找出x=1250时,y对应的值,所以我们预估的房价是在220k左右。
这是一个很典型的监督学习(Supervised Learning)的例子,我们再简单回顾一下监督学习是什么:监督学习就是我们会给出一些输入x(面积)和对应的正确的输出y(价格),学习算法分析给出的x和y之间的关系,之后我们再给出一个输入x时,学习算法就可以预测出一个合理且比较准确的y值,至于什么是回归这些具体细节还请去看监督学习(Supervised Learning)这一篇哦~
这种线性回归模型是一种特殊的类型的监督学习模型,它被称为回归(Regression)模型是因为它的输出时预测的数字(无限多可能的结果)。除了回归模型,分类模型(Classification Model)也是一种常见的监督学习,分类模型预测的是类别(少数可能的输出),这个在监督学习那一张也有细讲。
常用符号表示
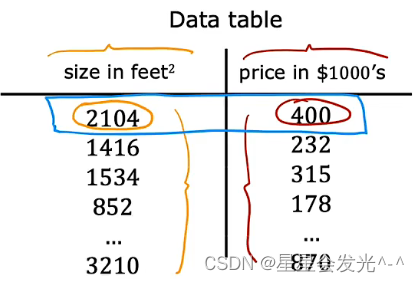
除了这种图呢,还有另一种表示方式,我们也可以用一个表来表示,下面这张表中第一列黄色对应的是图的x轴,第二列红色对应的是图的y轴,表中每一行数据对应了图上的一个点,比如(2104,400)这对数据代表的点就是表中用蓝色圈起来的点,这是很好理解的。
接下来我们要引入在机器学习中常见的一些符号,也是以后谈论机器学习概念的术语。
上面我们刚谈到的这张表中的数据集被我们用来训练模型,我们将它训练集(training set),
我们在一开始并不知道面积为1250的房子应该多少钱,所以要先用训练集(training set)来训练模型,训练之后的模型就可以用来预测房价了。在机器学习中,表示输入的标准符号是小写的,
上面房屋的例子中,x是 ,它常被叫做输入变量(input variable),也被叫做特征
(feature),或者输入特征(input feature),y是,他常被叫做输出变量(output variable)或者目标变量(target variable)。
上面给出的表格有47行,每行代表一个不同的训练样本,我们常用小写m来表示训练样本总数,所以对于这个例子来说m=47,为了更方便地表示单个训练示例,我们使用(x,y)来表示单个训练样本,比如说第一个训练样本就是(2104,400),那么有这么多训练样本,我们怎么知道这是第多少个训练样本呢?别急,我们可以用来表示这是第i个训练样本,那(2104,400)这个训练样本就可以被表示为
,1416就是
,这样就可以很方便的表示啦!
定义
下面我们来了解监督学习的过程,监督学习算法将输入一个数据集,那它做了什么呢?得到了什么结果?这将是本篇最后要讨论的内容。
监督学习的训练集包括输入特征和目标变量,要训练模型,就要输入训练集,然后监督学习算法就会产生一些函数f(也叫模型model),f的任务就是获取到一个新的输入x时,可以预测一个输出,我们把这个输出表示为,在机器学习中,我们用
来表示是预估值,而
才是真实值。
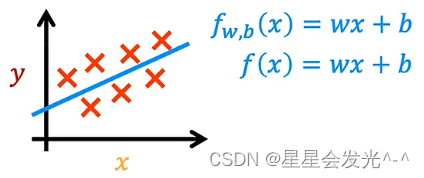
那我们怎么来表示这个函数f呢,在线性回归中,我们是一种认为f是一条直线,所以这里f可以被表示为,如果确定了w和b,也就确定了给出x时y的预估值
当给出了训练集之后,算法会生成一条最适合的直线,比如图中所示的直线,这就是线性回归模型,更细一步来讲,是有一个变量(one variable)的线性回归模型,这里的一个变量是指只有一个输入变量,这种线性回归我们叫它单变量线性回归(univariate linear regression),
本篇就先到这里了,为了能更好的达到目标结果,我们需要构造一个成本函数,成本函数的思想是机器学习中最普遍最重要的思想之一,用于线性回归和训练世界上许多先进的模型,我们将在下一篇中讨论它。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









