







哈喽,哈喽~,一年一度的抢火车票大战正式拉开序幕…
然饿大多数人碰到的是这种情况:当你满心期待摩拳擦掌准备抢票的时候,你会发现一票难求!想回趟家真难!
那么作为程序猿的你,当然要用程序猿的方式来抢票!下面分享用python来抢票!
对于没有Python基础的人看这一篇:最新12306抢票软件已发布,在也不用自己运行脚本了-CSDN博客
网站提供各种免费资源!资源吧 -
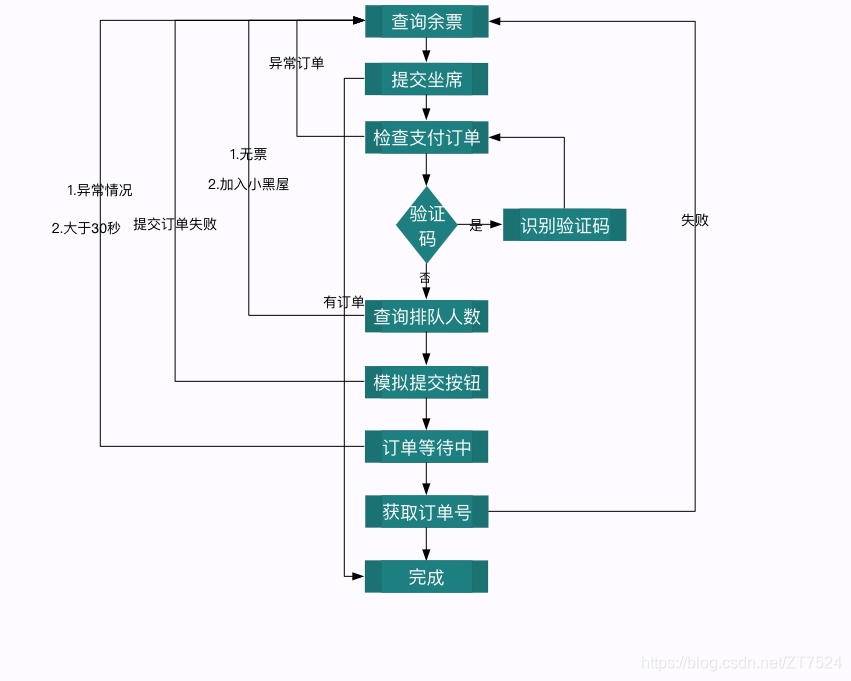
城市cookie可根据具体需求自行添加!不懂的点这里!
- 导入所需模块:
import re
from splinter.browser import Browser
from time import sleep
import sys
import httplib2
from urllib import parse
import smtplib
from email.mime.text import MIMEText
import time
此部分导入了代码所需的各种模块,用于实现不同的功能,包括正则表达式、网页浏览、时间操作、系统相关操作、HTTP连接、URL解析、发送电子邮件和短信等功能。
- BrushTicket 类初始化:
class BrushTicket(object):
def __init__(self, passengers, from_time, from_station, to_station, number, seat_type, receiver_mobile, receiver_email):
# 初始化实例属性
# ...
这部分定义了 BrushTicket 类并初始化了基于提供的参数的实例属性。这些属性包括乘客详细信息、车站信息、出发时间、座位类型、通知联系人和URL等。
- 登录功能:
def do_login(self):
self.driver.visit(self.login_url)
sleep(1)
print('请扫描二维码登录或使用您的账号登录...')
while True:
if self.driver.url != self.init_my_url:
sleep(1)
else:
break
do_login 方法负责登录网站。它打开登录的URL,等待用户手动登录(可以通过扫描二维码或使用账号登录),并等待登录成功。
- 车票预订功能:
def start_brush(self):
self.driver.driver.maximize_window()
self.do_login()
self.driver.visit(self.ticket_url)
try:
# ...
except Exception as error_info:
print(error_info)
start_brush 方法实现了车票预订功能。它最大化浏览器窗口,执行登录操作,然后导航到车票预订页面。它不断查询是否有可用车票,选择所需的座位类型,并尝试为指定的乘客预订车票。它还处理异常情况,并在成功预订时提供通知。
- 短信通知:
def send_sms(self, mobile, sms_info):
# ...
send_sms 方法负责发送短信通知。它使用"互亿无线"服务发送测试短信。它接收接收者的手机号码和短信内容作为参数,并返回从服务端收到的响应。
大家都有所体会12306那种神级验证码,即使是聪明如你也不定每次都能把验证码找对找全。然而经过训练后的模型却是可以的,不得不感叹科技强大。当然该程序中并没有涉及到这一识别验证码的核心技术,它只是将这一工作丢给第三方若快平台去做,然后自身利用结果即可。那么若快是如何识别这种神级验证码呢?通过机器学习 训练所需要的模型?笔者在这方面所了解的较少,不能给过多解释。但是这确实是个值得研究的方向。
- 邮件通知:
def send_mail(self, receiver_address, content):
# ...
send_mail 方法处理发送电子邮件通知的功能。它使用SMTP协议连接到电子邮件服务器,使用发件人的凭据登录,并向指定的接收者地址发送电子邮件。它包括主题、正文以及发件人/收件人的详细信息。它接收接收者的电子邮件地址和邮件内容作为参数。
注:给我们推送相关消息,需要用户去提供账户和密码,这是个冒险的尝试,避免不了信息泄露的可能。
- 主程序执行:
if __name__ == '__main__':
# 用户输入和初始化
# ...
# 开始预订车票
ticket = BrushTicket(passengers, from_time, from_station, to_station, number, seat_type, receiver_mobile, receiver_email)
ticket.start_brush()
主程序执行部分接收用户输入以获取预订车票所需的各个参数,使用提供的值初始化 BrushTicket 对象,并调用 start_brush 方法开始预订车票的过程。
注意!!!以下是Python部分主要代码:
源码资源获取:资源吧 -
def start_brush(self):
"""买票功能实现"""
# 浏览器窗口最大化
self.driver.driver.maximize_window()
# 登陆
self.do_login()
# 跳转到抢票页面
self.driver.visit(self.ticket_url)
try:
print('开始刷票……')
# 加载车票查询信息
self.driver.cookies.add({"_jc_save_fromStation": self.from_station})
self.driver.cookies.add({"_jc_save_toStation": self.to_station})
self.driver.cookies.add({"_jc_save_fromDate": self.from_time})
self.driver.reload()
count = 0
while self.driver.url == self.ticket_url:
try:
self.driver.find_by_text('查询').click()
except Exception as error_info:
print(error_info)
sleep(1)
continue
sleep(0.2)
count += 1
local_date = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('第%d次点击查询……[%s]' % (count, local_date))
try:
current_tr = self.driver.find_by_xpath(
'//tr[@datatran="' + self.number + '"]/preceding-sibling::tr[1]')
if current_tr:
if current_tr.find_by_tag('td')[self.seat_type_index].text == '--':
print('无此座位类型出售,已结束当前刷票,请重新开启!')
sys.exit(1)
elif current_tr.find_by_tag('td')[self.seat_type_index].text == '无':
print('无票,继续尝试……')
sleep(1)
else:
# 有票,尝试预订
print('刷到票了(余票数:' + str(
current_tr.find_by_tag('td')[self.seat_type_index].text) + '),开始尝试预订……')
current_tr.find_by_css('td.no-br>a')[0].click()
sleep(1)
key_value = 1
for p in self.passengers:
if '()' in p:
p = p[:-1] + '学生' + p[-1:]
# 选择用户
print('开始选择用户……')
self.driver.find_by_text(p).last.click()
# 选择座位类型
print('开始选择席别……')
if self.seat_type_value != 0:
self.driver.find_by_xpath(
"//select[@id='seatType_" + str(key_value) + "']/option[@value='" + str(
self.seat_type_value) + "']").first.click()
key_value += 1
sleep(0.2)
if p[-1] == ')':
self.driver.find_by_id('dialog_xsertcj_ok').click()
print('正在提交订单……')
self.driver.find_by_id('submitOrder_id').click()
sleep(2)
# 查看放回结果是否正常
submit_false_info = self.driver.find_by_id('orderResultInfo_id')[0].text
if submit_false_info != '':
print(submit_false_info)
self.driver.find_by_id('qr_closeTranforDialog_id').click()
sleep(0.2)
self.driver.find_by_id('preStep_id').click()
sleep(0.3)
continue
print('正在确认订单……')
self.driver.find_by_id('qr_submit_id').click()
print('预订成功,请及时前往支付……')
# 发送通知信息
self.send_mail(self.receiver_email, '恭喜您,抢到票了,请及时前往12306支付订单!')
self.send_sms(self.receiver_mobile, '您的验证码是:1230。请不要把验证码泄露给其他人。')
else:
print('不存在当前车次【%s】,已结束当前刷票,请重新开启!' % self.number)
sys.exit(1)
except Exception as error_info:
print(error_info)
# 跳转到抢票页面
self.driver.visit(self.ticket_url)
except Exception as error_info:
print(error_info)
def send_sms(self, mobile, sms_info):
"""发送手机通知短信,用的是-互亿无线-的测试短信"""
host = "106.ihuyi.com"
sms_send_uri = "/webservice/sms.php?method=Submit"
account = "C59782899"
pass_word = "19d4d9c0796532c7328e8b82e2812655"
params = parse.urlencode(
{'account': account, 'password': pass_word, 'content': sms_info, 'mobile': mobile, 'format': 'json'}
)
headers = {"Content-type": "application/x-www-form-urlencoded", "Accept": "text/plain"}
conn = httplib2.HTTPConnectionWithTimeout(host, port=80, timeout=30)
conn.request("POST", sms_send_uri, params, headers)
response = conn.getresponse()
response_str = response.read()
conn.close()
return response_str
def send_mail(self, receiver_address, content):
"""发送邮件通知"""
# 连接邮箱服务器信息
host = 'smtp.163.com'
port = 25
sender = 'gxcuizy@163.com' # 你的发件邮箱号码
pwd = '******' # 不是登陆密码,是客户端授权密码
# 发件信息
receiver = receiver_address
body = '<h2>温馨提醒:</h2><p>' + content + '</p>'
msg = MIMEText(body, 'html', _charset="utf-8")
msg['subject'] = '抢票成功通知!'
msg['from'] = sender
msg['to'] = receiver
s = smtplib.SMTP(host, port)
# 开始登陆邮箱,并发送邮件
s.login(sender, pwd)
s.sendmail(sender, receiver, msg.as_string())
















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











